
Reevaluando el aprendizaje continuo con pocos ejemplos
La evaluación con pocos ejemplos revela nuevas perspectivas sobre estabilidad y plasticidad en aprendizaje continuo. El meta-aprendizaje mejora la adaptación.
La evaluación con pocos ejemplos revela nuevas perspectivas sobre estabilidad y plasticidad en aprendizaje continuo. El meta-aprendizaje mejora la adaptación.

Aprende cómo la autoevaluación por clusters permite a los LLMs medir su incertidumbre con solo dos muestras, mejorando la confiabilidad de sus respuestas.

¿Los modelos de razonamiento grandes expresan su confianza de forma fiel? Cuantificamos la calibración entre incertidumbre interna y verbalizada, revelando desa
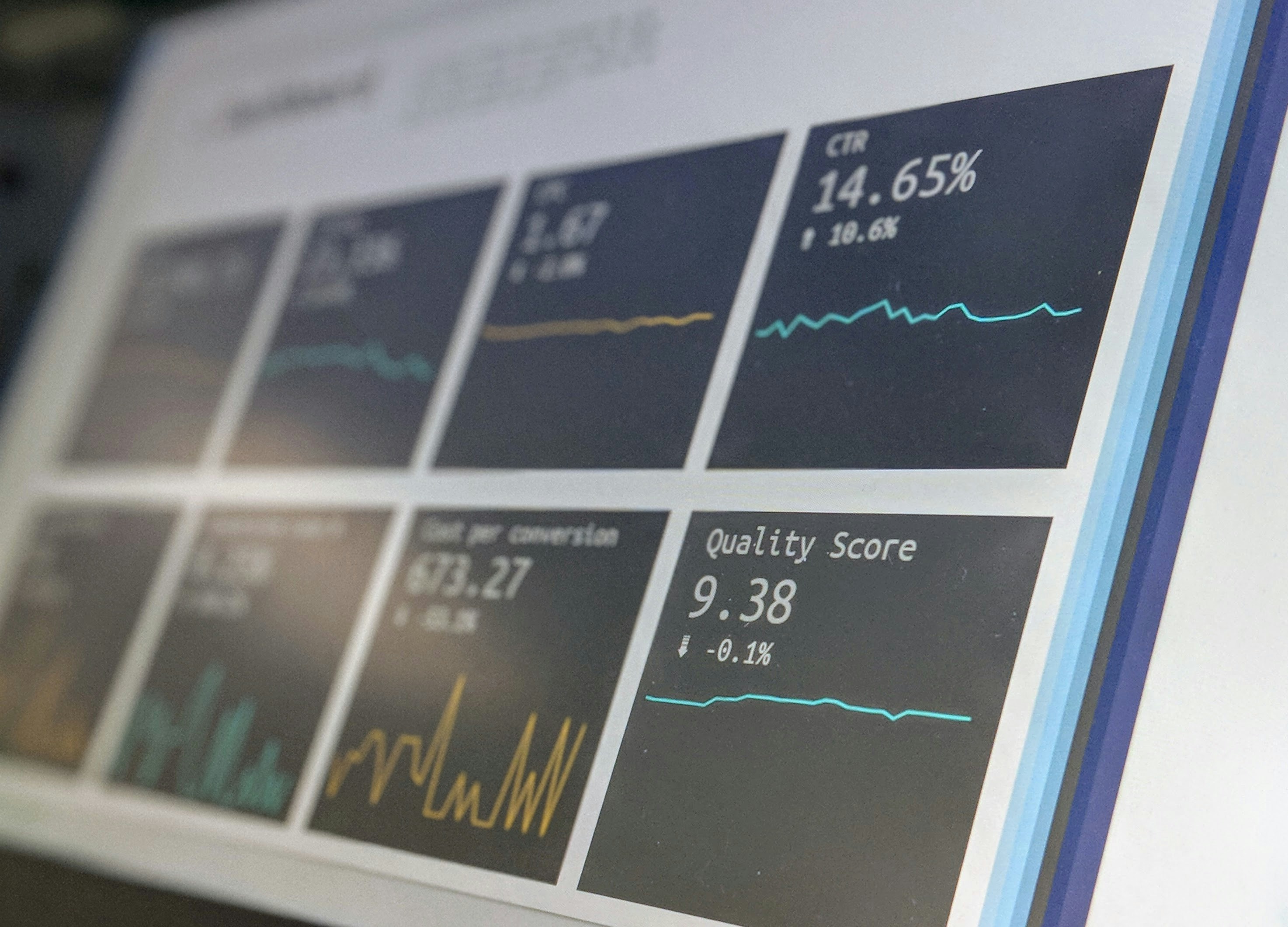
Descubre AlphaEval, marco de evaluación unificado y sin backtesting para minería de alfas. Evalúa poder predictivo, estabilidad, robustez y más. ¡Open source!

Descubre EvoEnv, el nuevo benchmark que evalúa a los agentes IA en entornos laborales dinámicos: planificación, exploración y aprendizaje continuo.

PieArena mide la capacidad de negociación de los LLMs en escenarios reales. GPT-5 iguala o supera a humanos en este benchmark.

12 métricas clave para evaluar la confiabilidad real de agentes de IA: consistencia, robustez, predictibilidad, seguridad. Más allá del éxito aparente.

Descubre cómo X-RAY mapea la capacidad de razonamiento de los LLMs usando sondas formales y calibradas, revelando asimetrías y fallos interpretables.

Descubre cómo el benchmark REL evalúa el razonamiento relacional en LLMs, revelando sus limitaciones en tareas de alta aridad en ciencias.

Mejora la transparencia en optimización de caja negra con IEMSO: métricas inclusivas que explican el proceso de surrogate optimization y aumentan la confianza.

WISE: Benchmark que evalúa conocimiento mundial en T2I. 1000 prompts en 25 subdominios, WiScore mide cultura, espacio-tiempo y ciencia.

Descubre CoMPAS3D, el dataset de captura de movimiento de salsa que permite evaluar robots humanoides en interacciones sociales con métricas objetivas.

Descubre cómo el cómputo de inferencia calibrado por distribución mejora la fiabilidad de LLM como juez, reduciendo errores y superando métodos tradicionales de votación.

Descubre PVF, un nuevo método de decodificación paralela para modelos de difusión que reduce hasta un 65% las evaluaciones de función sin perder precisión.
CodeHacker genera pruebas adversariales para detectar vulnerabilidades en soluciones de programación competitiva. Mejora benchmarks y entrena modelos de IA.

Descubre cómo el método LPCD burla a los atacantes 'camaleón' que cambian tácticas en streaming, usando desacoplamiento contrafáctico para evaluar riesgos.

Descubre la metodología rigurosa de Gate AI para evaluar detectores de inyección y jailbreaks en LLM con umbral único y 16 benchmarks. Resultados sin sesgos.

Descubre cómo los modelos frontera generan alucinaciones sintéticas como negativos duros para entrenar modelos de código y reducir alucinaciones +18.8%.

Descubre cómo IdEst, basado en dimensión intrínseca, evalúa representaciones SSL de forma eficiente, reduciendo costos computacionales y sin necesidad de etiquetas.

IdEst evalúa representaciones SSL con dimensión intrínseca: métrica geométrica que correlaciona con el rendimiento downstream. Ahorra tiempo en evaluación.