
CAPED: Defensa Contextual de Privacidad para GUI Móviles
CAPED protege tu privacidad visual en agentes GUI móviles: solo expone datos necesarios para cada tarea, reduciendo fugas de información sensible. Descúbrelo.
CAPED protege tu privacidad visual en agentes GUI móviles: solo expone datos necesarios para cada tarea, reduciendo fugas de información sensible. Descúbrelo.

Descubre el MPC agentivo que integra LLMs para adaptar el control semántico en vehículos autónomos, respondiendo a normas sociales y preferencias del usuario.
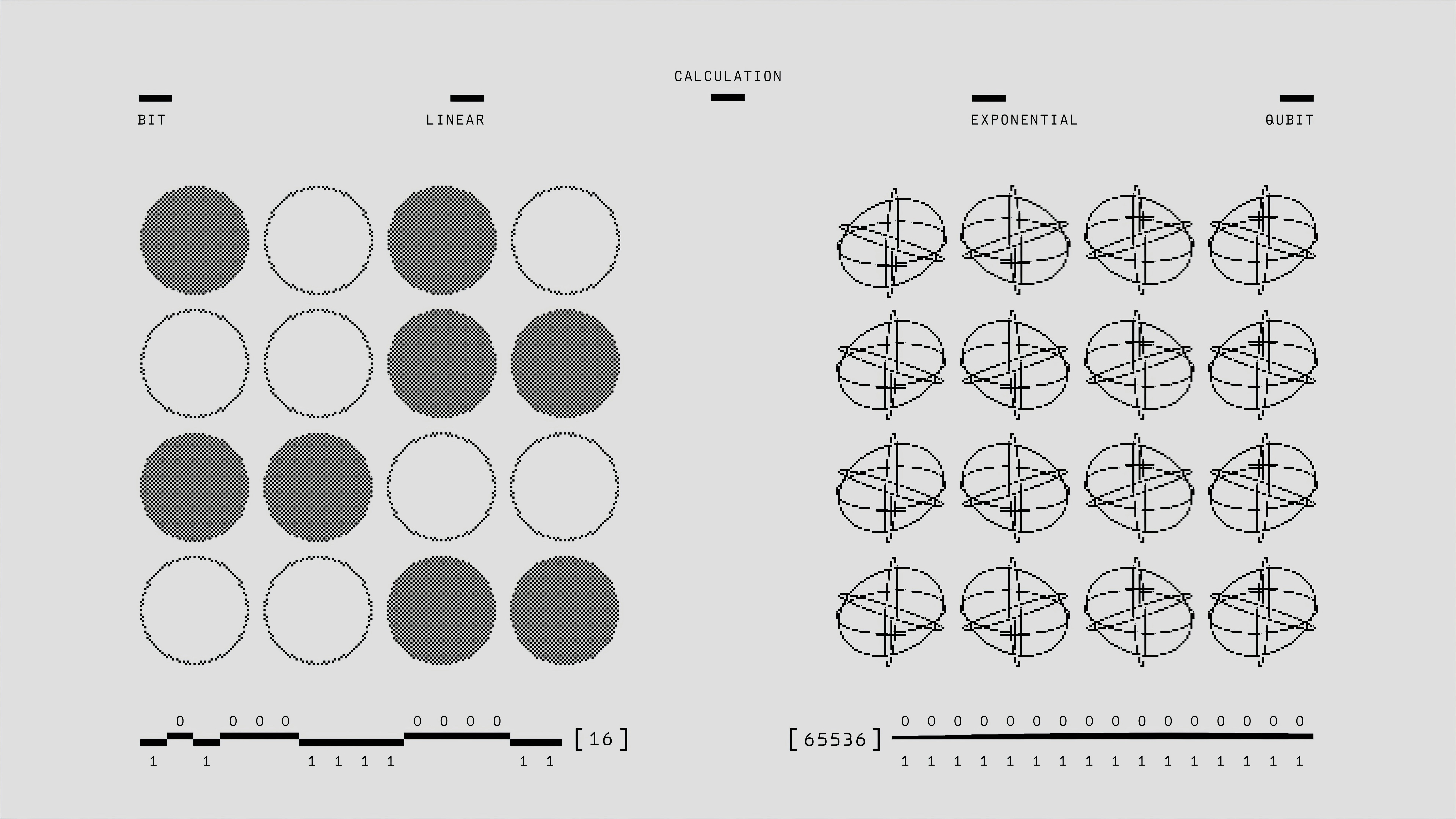
Descubre PERIA, un agente visual que usa herramientas para mejorar el razonamiento espacial. Supera a modelos grandes en tareas de mapas, probing y reconstrucción.
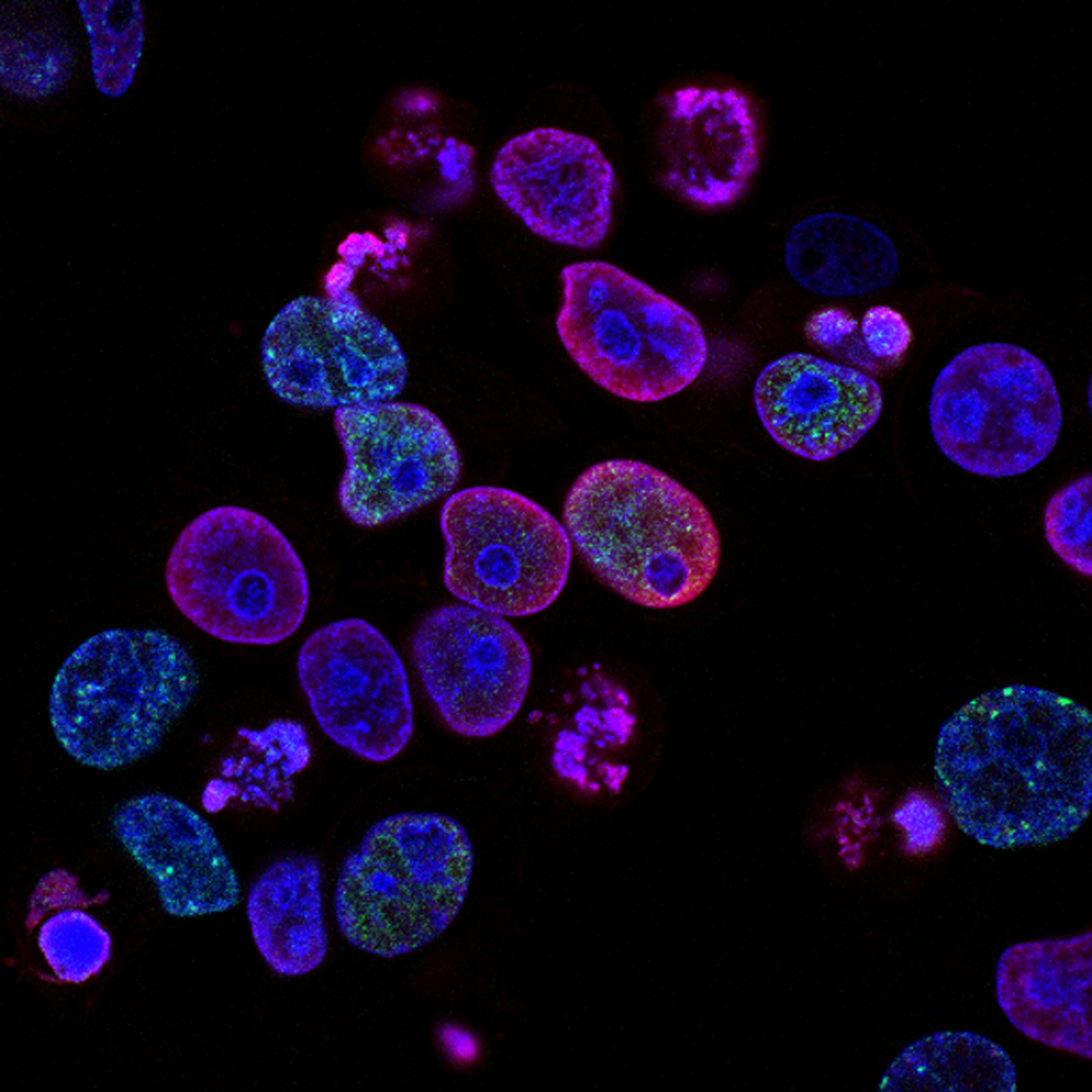
OCOO-T: modelo de célula virtual minimalista que predice respuestas transcripcionales a perturbaciones con alta precisión y escalabilidad.

TimeROME-DLM permite editar conocimiento en modelos de difusión enmascarados sin reentrenar. Rápido, sin VRAM extra, escala a 400 hechos. ¡Conócelo!

JSCGC reemplaza la decodificación tradicional por modelos generativos, mejorando la calidad perceptual y semántica en comunicaciones inalámbricas.

Aislamiento modal en razonamiento intercalado reduce coherencia. MoTiF supervisa transiciones con refuerzo paso a paso para mejorar precisión en tareas.

scLLM-DSC: un novedoso marco de clustering multimodal que aprovecha grandes modelos de lenguaje para mejorar la precisión en el análisis de células individuales.

scLLM-DSC mejora el clustering de scRNA-seq integrando conocimiento de LLM y supera 11 métodos. Conoce este avance en bioinformática.

Descubre cómo EA-WM integra verificación de eventos en modelos del mundo para una manipulación robótica más precisa y segura en tareas de largo horizonte.

Descubre cómo IVT enseña a modelos visión-lenguaje a corregir sus errores espaciales: precisión 82% y degradación 5x menor.

Robot humanoide se distingue de otros usando percepción propioceptiva-visual sin etiquetas. Crea modelo corporal 3D para navegación y evitar colisiones.

¿El benchmark ROAR es confiable? Descubre cómo la borrosidad en mapas de atribución infla resultados y engaña.
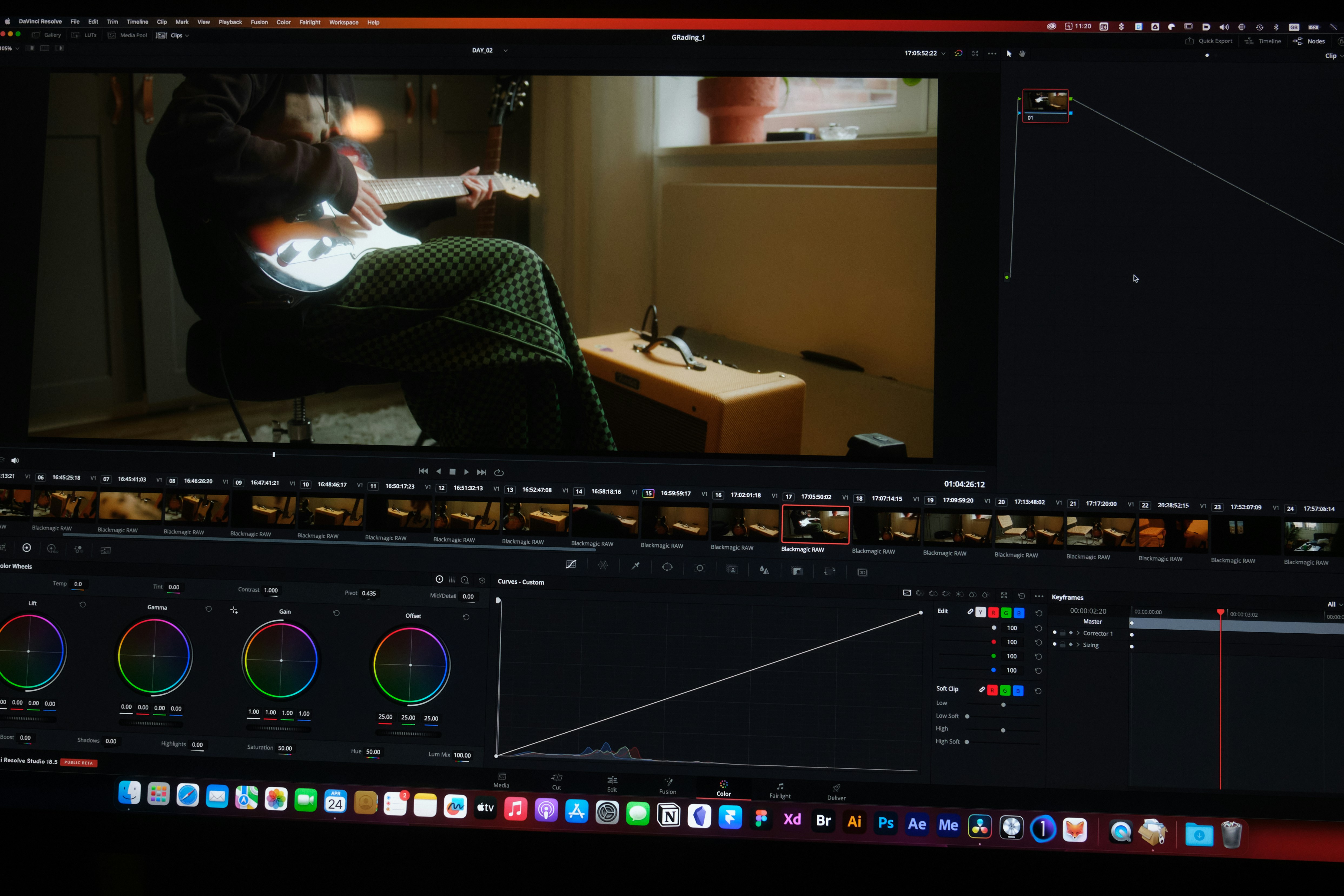
Descubre cómo ReFoCUS utiliza aprendizaje por refuerzo para seleccionar fotogramas clave en video, mejorando la precisión en tareas de comprensión contextual.
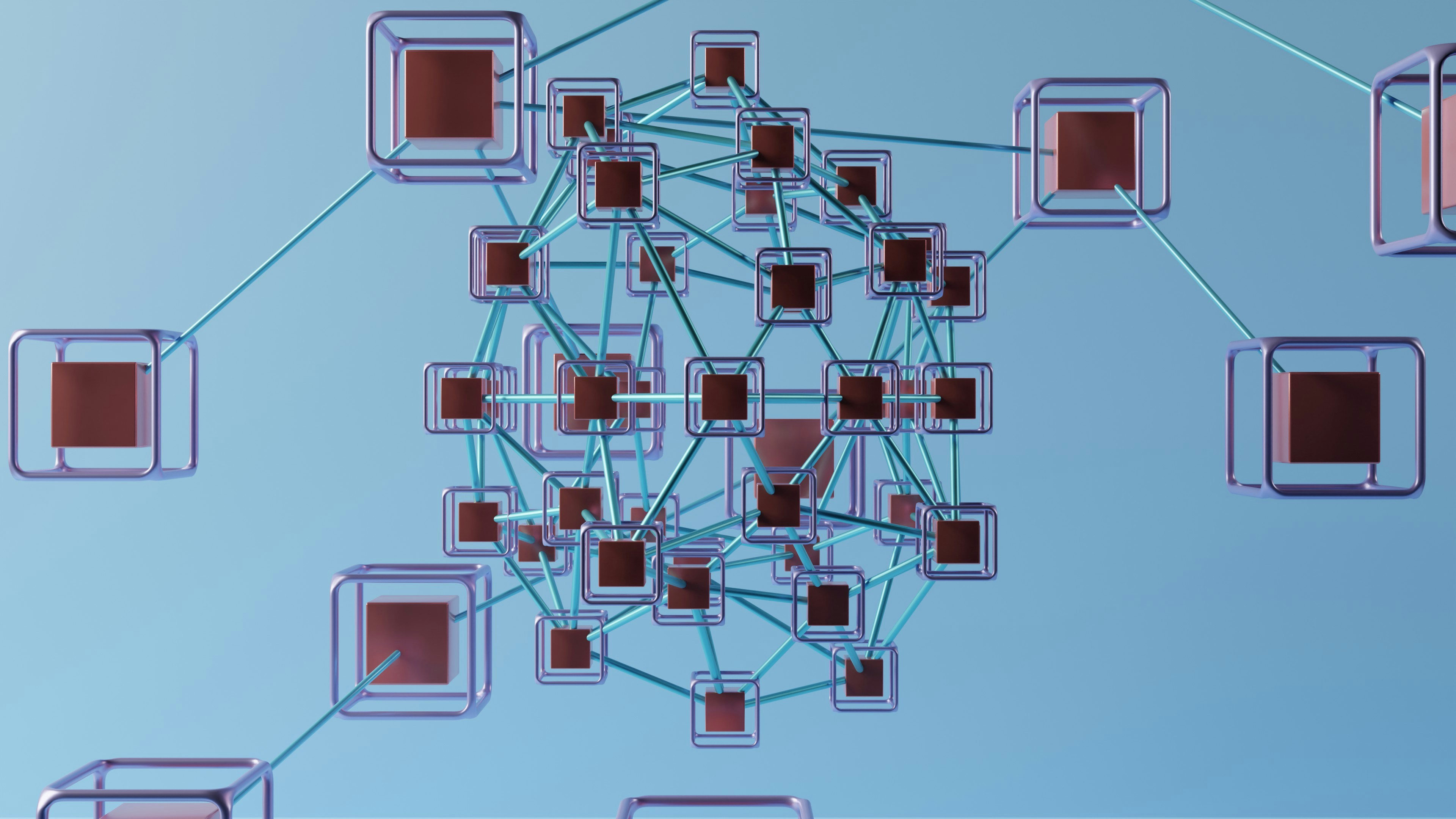
Conoce KG-ER, el lenguaje de esquemas conceptuales que unifica la representación de grafos de conocimiento sin depender de la tecnología. ¡Mejora semántica!

Conoce VDE Bench, el benchmark que evalúa modelos de edición de imágenes en documentos densos bilingües chino-inglés. Ideal para IA.

Descubre LatentLens, un método que revela qué codifican los tokens visuales en modelos de lenguaje. Mejora la interpretabilidad de VLMs.

Ex-Omni genera animación facial 3D sincronizada con voz para modelos omni-modales. Código abierto, baja latencia y alta calidad.
PaLMR alinea procesos de razonamiento visual en modelos multimodales, reduciendo alucinaciones y mejorando fidelidad. Logra resultados de vanguardia en HallusionBench, MMMU, MathVista y MathVerse.
Aprende cómo la tensorización de entropía extiende la desigualdad de McDiarmid a datos dependientes. Aplicaciones en ML, grafos aleatorios y más.