
IntAttention: Pipeline entero de atención para inferencia en edge
Descubre IntAttention: acelera la inferencia de Transformers en edge hasta 3.7x con pipeline entero sin conversiones. Sin pérdida de precisión.
Descubre IntAttention: acelera la inferencia de Transformers en edge hasta 3.7x con pipeline entero sin conversiones. Sin pérdida de precisión.

Los SuperActivadores: tokens de cola en Transformers que señalan conceptos con alta fiabilidad, mejorando la detección en 0.14 F1. ¡Descubre el mecanismo!

Descubre cómo los transformers con bucles y relleno logran reconocer lenguajes libres de contexto, y por qué los lenguajes no ambiguos son más eficientes.

Extrae algoritmos interpretables de un Transformer Discreto. Descubre cómo convertir pesos neuronales en código legible para una IA más explicable.

¿Qué opciones de arquitectura realmente importan en transformers con padding? La precisión numérica y la profundidad determinan su expresividad, con equivalencias a circuitos AC0 y TC0.

Descubre ConTrans: combina convolución y transformer para representaciones local-global en localización zero-shot, nuevo benchmark.
Descubre cómo las cabezas de atención posicionales y simbólicas aprenden en Transformers, su geometría RoPE y generalización de longitud.

Descubre DTop-p MoE, un nuevo mecanismo de enrutamiento dinámico que aprende el umbral de probabilidad para controlar la esparcidad, superando a Top-k y Top-p fijo en modelos fundacionales.

PictSure clasifica imágenes con pocos ejemplos usando aprendizaje en contexto. La calidad de los embeddings pre-entrenados es clave. Modelo open source.

¿Sabías que un transformer fijo puede simular cualquier otro modelo? Investigación revela que el poder está en la representación, no en los pesos. Entra y descúbrelo.
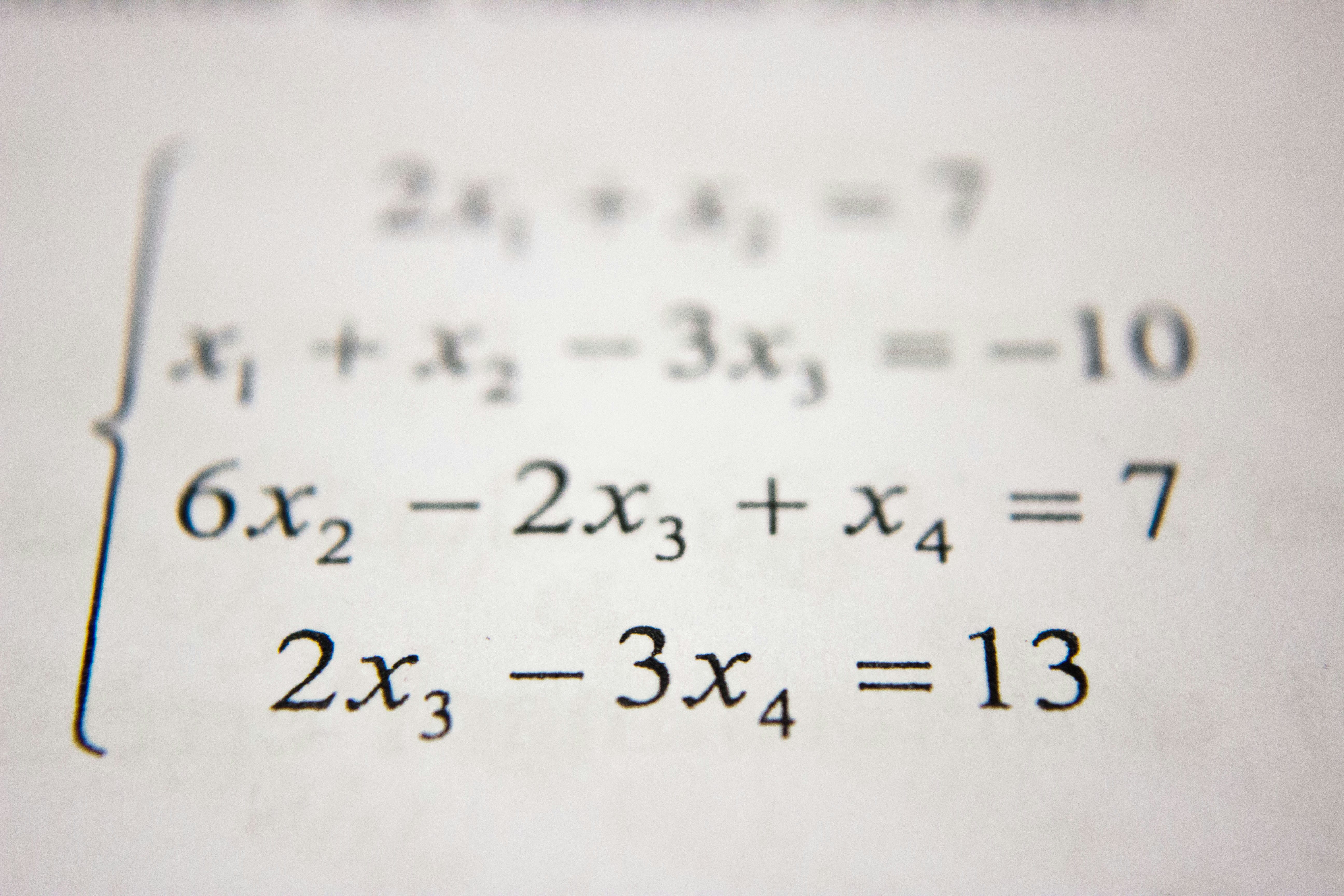
Estudio mecanicista revela cómo los transformers aprenden aritmética modular y asignación de variables para generalizar combinaciones no vistas. ¡Entra!

Descubre CHARM, el modelo JEPA multimodal para embeddings semánticos en series temporales. Ideal para anomalías y predicción.

Descubre cómo un optimizador basado en atención encuentra simetrías en Hamiltonianos de Pauli usando IA, superando métodos tradicionales en modelos de Ising y Toric.

RIB permite FlashAttention en SR Transformers, logrando ventanas de 96x96, 2.1x menos entrenamiento y 2.9x menos inferencia. Alcanza 35.63 dB PSNR en Urban100.

Descubre VMoER, un marco bayesiano que mejora la incertidumbre en MoE con un 94% menos error y solo 1% más de FLOPs.

Descubre cómo un pequeño transformer aprende el mapa zeta en caminos de Dyck, y cómo la interpretabilidad mecánica revela un nuevo algoritmo verificable por humanos.
Comparativa de memoria: Chain-of-Thought vs Transformers en bucle comprimido. Los bucles no pueden igualar el razonamiento con scratchpad. ¡Descubre por qué!

ImmersiveTTS genera voz natural integrada en entornos reales, superando en naturalidad e inteligibilidad a otros modelos. Conoce cómo logra la alineación semántica con difusión multimodal.

Descubre FHRFormer, un transformer auto-supervisado que imputa y predice la frecuencia cardíaca fetal con alta precisión.
Comparativa de codificación posicional para modelos Transformer en EEG. Analizamos técnicas y su impacto en el rendimiento. Descubre la mejor opción.