
Minimización de arrepentimiento con oponentes adaptativos en juegos repetidos
Exploramos cómo minimizar el arrepentimiento en juegos repetidos con oponentes adaptativos, presentando algoritmos que logran cooperación y equilibrios óptimos.
Exploramos cómo minimizar el arrepentimiento en juegos repetidos con oponentes adaptativos, presentando algoritmos que logran cooperación y equilibrios óptimos.

Descubre Adalina, el algoritmo adaptativo que acelera la aproximación del Valor Shapley y semi-valores con espacio lineal. Ideal para atribución en IA.

Descubre las estrategias clave de la teoría de juegos para tomar mejores decisiones en negocios, política y más. Aprende equilibrio de Nash, dilema del prisionero y aplicaciones prácticas.

Los aprendices sin arrepentimiento explican la paradoja de Bertrand: por qué persisten precios altos. Análisis y experimentos revelan sorpresas.

Descubre cómo los modelos de juego potencial revelan transiciones críticas en el aprendizaje federado, optimizando el equilibrio entre esfuerzo y recompensa.

Alinea LLMs de caja negra en inferencia usando optimización restringida y teoría de juegos para balancear seguridad y utilidad.
Descubre cómo los LLM muestran una honestidad excesiva incluso cuando hay conflicto de intereses, según un nuevo benchmark basado en teoría de juegos.

Descubre por qué la IA en salud solo genera valor si modifica incentivos, no solo optimiza tareas. Perspectiva de teoría de juegos.

Francia, EE.UU. y China logran soberanía en IA regulando su aprendizaje nacional. Modelo basado en aprendizaje centrado en humanos.
Descubre cómo NAMEx, basado en teoría de juegos, mejora la colaboración entre expertos en modelos MoE, logrando mayor precisión y robustez en IA.

Descubre cómo los LLMs negocian en simulaciones de compra-venta. ¿Son honestos o aprovechan la asimetría de información? Análisis de su credulidad y rendimiento.

Descubre cómo los modelos de lenguaje como GPT se comportan estratégicamente al jugar piedra, papel o tijera, y en qué se diferencian de los humanos. Resultados sorprendentes.
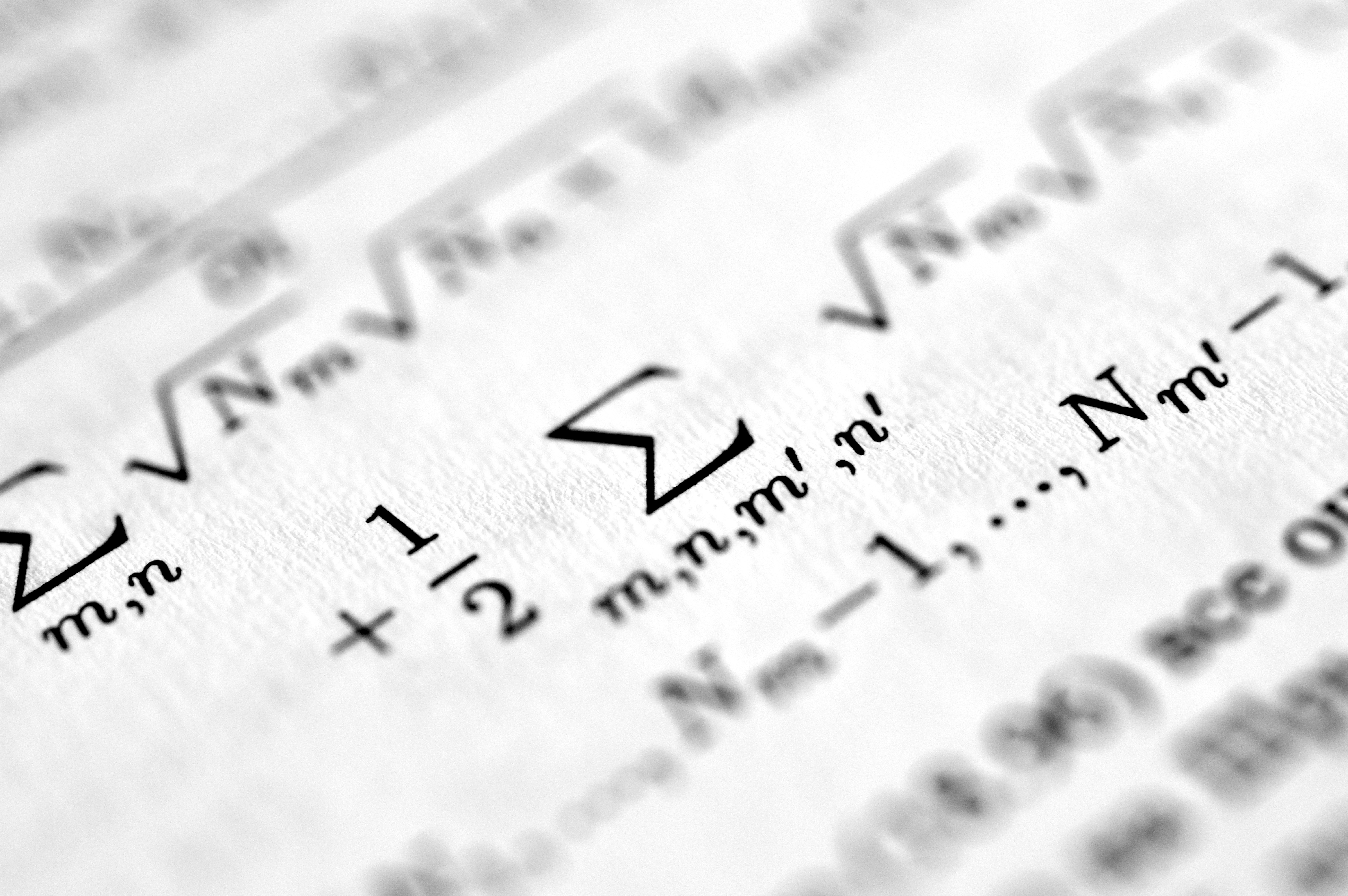
Descubre cómo los Universal Decision Learners unifican planificación, RL, intervenciones causales y teoría de juegos mediante extensiones de Kan. Una perspectiva matemática elegante.

Optimiza el bienestar social en sistemas multiagente: descubre por qué recompensa y castigo no son igual de efectivos.
<meta name=description content=Modelado diferenciable del oponente basado en creencias: técnica avanzada para anticipar y adaptarse a estrategias adversarias usando modelos diferenciables y actualización de creencias.>
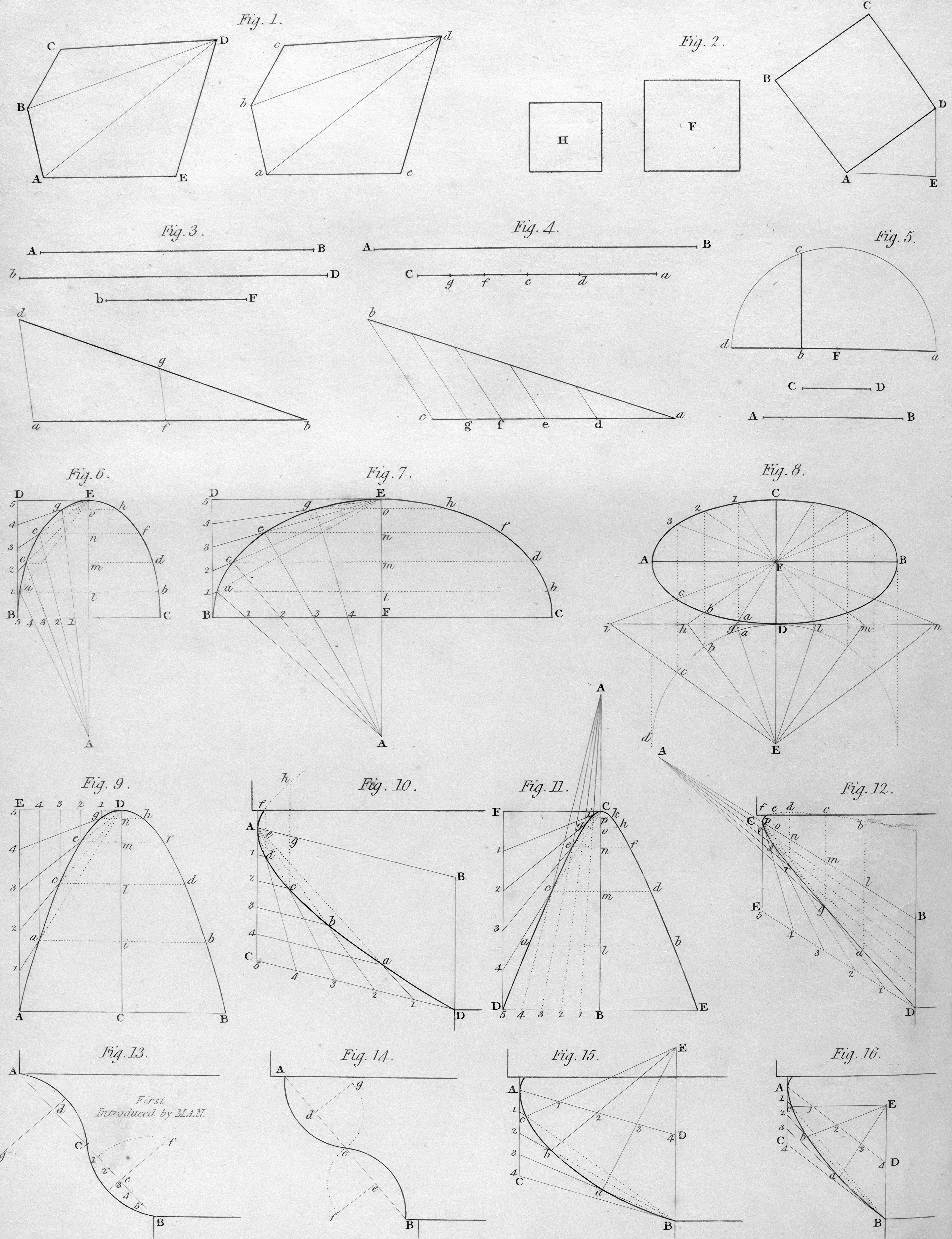
Aprende cómo la geometría transforma los juegos y sus solucionadores. Descubre técnicas geométricas para resolver estrategias y puzzles de manera eficiente.
Explora juegos de campo medio con núcleos y estadísticas U de Fourier: una fusión de teoría de juegos y análisis armónico. Para investigadores.
Descubre cómo lograr una asignación equitativa y sin envidia de bienes indivisibles incluso con consultas ruidosas. Un enfoque innovador para la justicia distributiva.
Auto-investigación en dilemas sociales secuenciales mediante tuberías cooperativas. Estrategias efectivas de colaboración y aprendizaje.

<meta name=description content=Análisis del arrepentimiento óptimo dependiente de la brecha en aprendizaje en línea privado. Descubre cómo minimizar el arrepentimiento preservando la privacidad del modelo.>