
Convierte especificaciones en evaluaciones para cualquier agente con ASSERT
ASSERT transforma especificaciones en lenguaje natural en evaluaciones ejecutables para agentes de IA. Pruebas más rápidas, precisas y auditables.
ASSERT transforma especificaciones en lenguaje natural en evaluaciones ejecutables para agentes de IA. Pruebas más rápidas, precisas y auditables.

La taxonomía de Fei-Fei Li define tres tipos de modelos del mundo, pero omite la capa esencial: la representación interna. ¡Descúbrelo!

Fei-Fei Li propone una taxonomía de modelos del mundo, pero omite la representación interna. Descubre por qué la simulación es el verdadero pilar.

FailureScope identifica debilidades en modelos de lenguaje mediante clustering conductual. Mejora la evaluación en benchmarks, diálogos y ataques adversariales.

Nueva taxonomía GEMM revela los límites prácticos del pruning en LLM. La poda estática y dinámica dominan según la pérdida de calidad. Resultados clave para acelerar inferencia.

Explora el estado del arte de las HGNN para detección de anomalías en ciberseguridad. Taxonomía, benchmarks y desafíos clave.

Descubre cómo Anything2Skill transforma conocimiento externo en habilidades ejecutables para agentes, mejorando RAG con tasas de éxito del 98%.

Autoexplicabilidad en sistemas complejos: estado, niveles y retos. Revisión sistemática que establece la base para sistemas que se explican a sí mismos.

Descubre DySECT, un sistema de extracción dinámico que aprende continuamente. Mejora la precisión integrando conocimiento y razonamiento gráfico.

Descubre cómo el modelo Bradley-Terry ofrece rankings justos y robustos para comparar algoritmos de recomendación según las características del dataset.
Primera taxonomía empírica de fallos runtime en servidores MCP. Basada en 837 hilos y validada por 55 desarrolladores, identifica 73 tipos de fallos.

Descubre la primera taxonomía de fallos en servidores MCP. 837 hilos analizados y encuesta a 55 desarrolladores revelan los 27 subtipos de fallos runtime.

BloomBench: el primer benchmark bilingüe para evaluar cognitivamente modelos de visión-lenguaje. Asimetrías clave entre árabe e inglés.

Descubre BloomBench, benchmark bilingüe (árabe-inglés) que evalúa la capacidad cognitiva de modelos visión-lenguaje. Revela brechas en memoria y creatividad.

Actualizamos la taxonomía de fallos en sistemas de IA agentiva con 7 nuevos modos, basados en 12 meses de red teaming. Descubre cómo proteger tus agentes.

Descubre cómo seis frameworks transforman los prompts en procesos estructurados para agentes de desarrollo de IA. Taxonomía, evaluación y recomendaciones.

Descubre cómo clasificar y predecir fallos en RLHF como reward hacking y colapso. Estudio empírico con PPO y DPO que revela dinámicas ocultas.
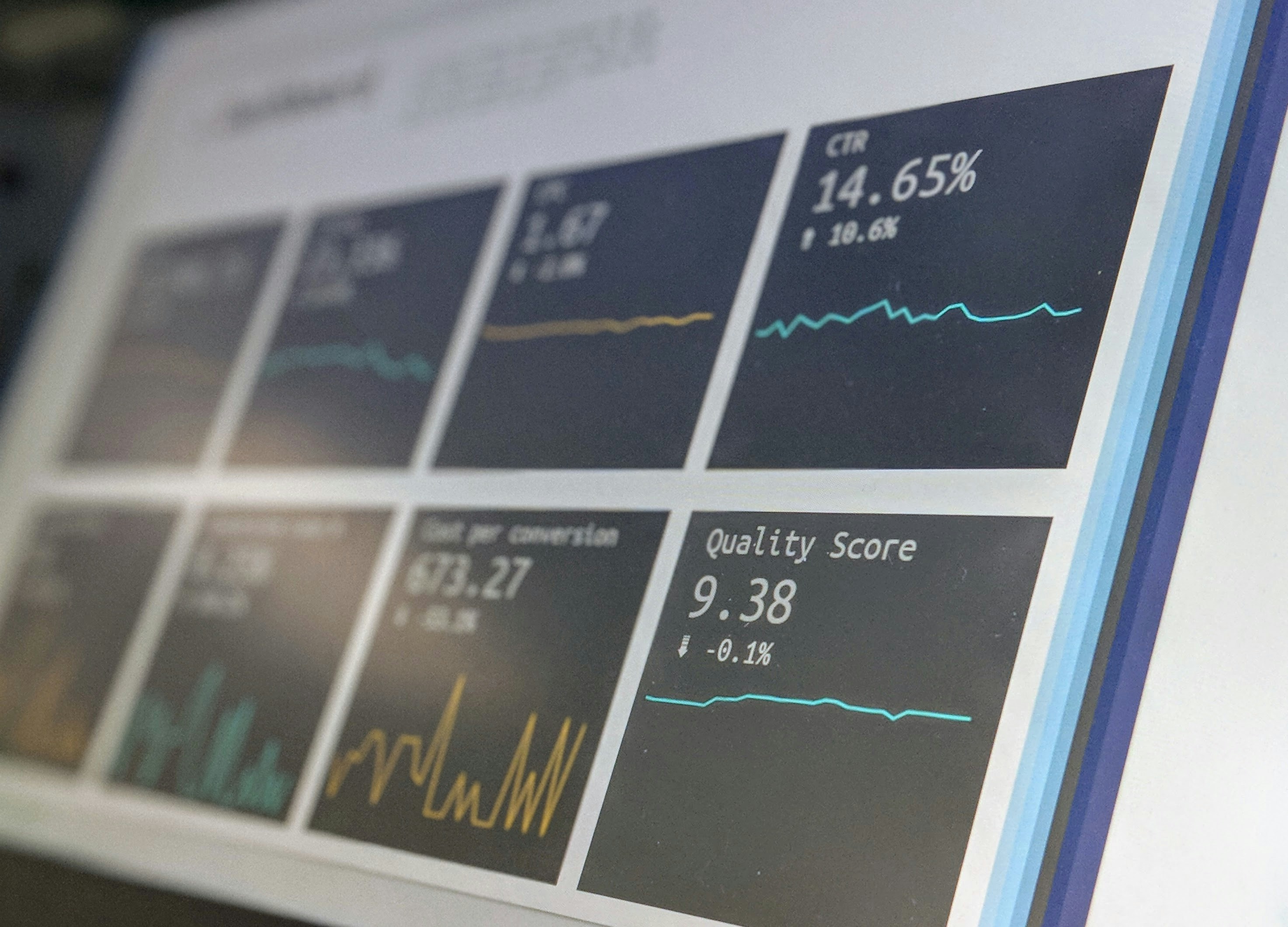
Descubre HiFi-KPI, el dataset con 1.65M de párrafos y 198k etiquetas jerárquicas para extraer KPIs de informes financieros. Modelos de IA alcanzan 0.906 F1 en clasificación.