
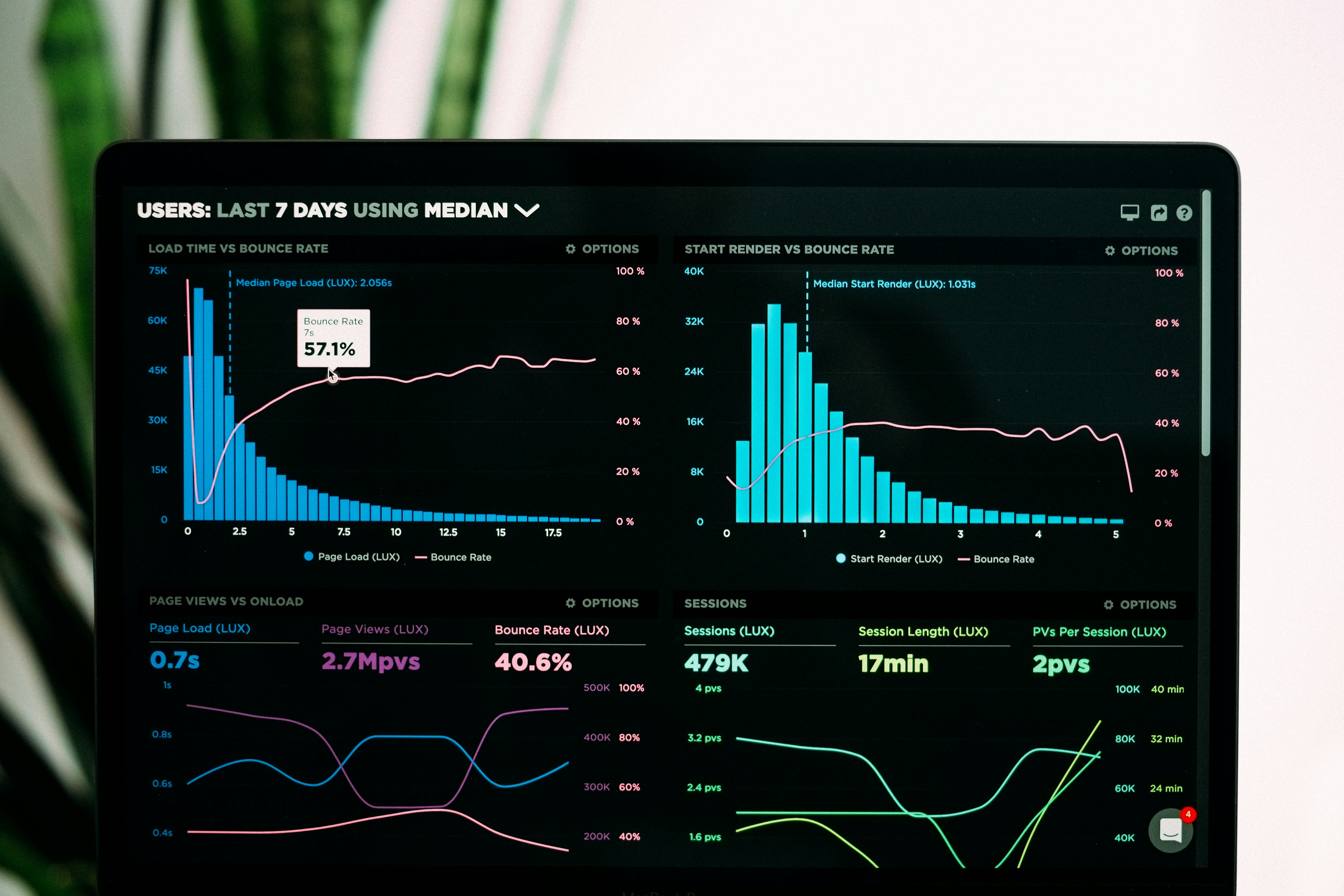
Respuesta a Incidentes de IA Agéntica: Rollback de Agentes Autónomos
Descubre cómo implementar un sistema de rollback para agentes autónomos, con snapshots, kill switch y supervisión humana. Evita daños en producción.
Descubre cómo implementar un sistema de rollback para agentes autónomos, con snapshots, kill switch y supervisión humana. Evita daños en producción.

Aprende cómo la supervisión Feynman-Kac mejora PINNs, reduce el mal condicionamiento y ofrece cotas de error. Ejemplos en Poisson, Schrödinger y más.

Nuevo método de aprendizaje por refuerzo reduce error de trayectoria en UAV de ala fija en un 86.77% respecto al autopiloto clásico. Descubre cómo el filtro HJB mejora la supervisión.

Descubre cómo la supervisión de segundo orden mejora el aprendizaje de sistemas caóticos, preservando atractores con bajo costo computacional.

Los modelos de difusión enmascarada (MDLM) son sensibles a pequeños desplazamientos posicionales. Descubre cómo CTC mejora el ajuste fino y supera a la entropía cruzada en cuatro benchmarks.

Descubre cómo combinar scores (perplejidad, contraste, verificación) con decodificadores para reducir alucinaciones en LLM sin supervisión. Resultados con Qwen3-1.7B.

Aprende cómo las funciones de confianza filtran etiquetas débiles para lograr generalización casi sin pérdidas. Mejora tu IA.

TrOPD estabiliza la destilación on-policy de LLMs usando regiones de confianza, superando la divergencia profesor-alumno. Mejora razonamiento, código y benchmarks.

Descubre cómo DenseMLLM permite a los LLM multimodales estándar realizar predicciones densas sin decodificadores adicionales. Resultados competitivos en segmentación y profundidad.
Descubre un nuevo framework que aprende a detectar anomalías en grafos dinámicos con pocos datos etiquetados, logrando alta precisión y generalización.
Descubre SAGE, un nuevo método de reordenamiento que mejora la robustez de los planificadores de difusión mediante autosupervisión y energías, sin necesidad de reentrenamiento.

Descubre cómo resolver conflictos de optimización entre ReID por imagen y texto. Un entrenamiento desacoplado mejora representaciones compartidas.

CAST optimiza el RLVR con autoenseñanza no privilegiada y asignación de ventajas token en grupos de varianza cero. Mejora el razonamiento.
Descubre cómo las críticas de modelos débiles pueden potenciar modelos de lenguaje fuertes mediante destilación on-policy, mejorando razonamiento y alineación para supervisión escalable.

Descubre CAREAgent, el agente clínico que combina razonamiento estructurado y herramientas integradas para generar órdenes clínicas precisas. Mejora el F1 un 5%

EvoPool revoluciona la anotación con un marco evolutivo multiagente que supera a los LLM en tareas especializadas, reduciendo costos hasta 31,000x. Descubre cómo.

Mejora el razonamiento algorítmico neuronal con reconstrucción auxiliar: representaciones más ricas que potencian el rendimiento de arquitecturas existentes.

Los LLMs optimizados por resultados alcanzan altos benchmarks pero colapsan en razonamiento. Te explicamos la paradoja y cómo los modelos de recompensa de procesos la resuelven.
POIROT detecta fallos en sistemas multiagente usando sus propios agentes, superando evaluadores centralizados. Mayor seguridad sin supervisión externa.

Descubre la arquitectura de runtime de agentes LLM con alcance organizacional para SOCs financieros, con auditoría, supervisión humana y seguridad integrada.