
¿Mentiste? Evaluando detectores de mentiras en modelos de lenguaje
¿Pueden los detectores de mentiras identificar cuándo un modelo de IA miente? Un estudio evalúa cuatro métodos en modelos de hasta 1B parámetros y revela sus limitaciones.
¿Pueden los detectores de mentiras identificar cuándo un modelo de IA miente? Un estudio evalúa cuatro métodos en modelos de hasta 1B parámetros y revela sus limitaciones.
Descubre HCPD, un método innovador para detectar alucinaciones en LLM sin referencias externas, usando un sondeo de criterios similar al razonamiento humano. Explicable y preciso.

Los métodos de interpretabilidad (SAEs, sondas) buscan separar conceptos, pero manipular características afecta múltiples conceptos, desafiando la independencia

¿Los LLM creen realmente sus afirmaciones al interpretar personajes? Un estudio revela diferencias entre roleplaying y desalineación emergente.

Descubre cómo Runtime Skill Audit (RSA) audita habilidades de agentes LLM en tiempo real, detectando comportamientos maliciosos ocultos con un 90% de precisión.

Descubre cómo ICALens usa ICA para encontrar direcciones interpretables en LLMs sin entrenar diccionarios, superando a los SAEs en eficiencia y sondas.

Descubrimos cómo seis algoritmos de alineación (PPO, DPO, SimPO, ORPO, GRPO, KTO) transforman internamente los modelos. Implicaciones para seguridad.
Descifra la dinámica de atención en modelos de audio con LSAC: acelera sin entrenamiento, manteniendo calidad.
Descubre cómo el nuevo método de crestas de densidad supera en hasta 20 puntos AUROC a técnicas actuales en detección de alucinaciones con pocas etiquetas de calibración.

Las sondas de estado oculto permiten moderar LLMs en streaming sin costo adicional. Detén contenido inseguro token a token, reduce latencia y ahorra recursos. Guía práctica.
Los LLMs pueden ocultar secretos mediante esteganografía. La detección con sondas lineales se evade, pero se restaura con recontextualización.

Las preguntas adaptativas y sondas del modelo del mundo permiten entrenar agentes de IA que explican su comportamiento y se adaptan a cambios.

Aprende a usar NVIDIA garak para construir un flujo de red-teaming defensivo en LLM con sondas y detectores personalizados. Incluye código completo.

Descubre cómo PRIG localiza la ambigüedad oculta en prompts de LLMs usando atribución por sonda, superando a GPT-5.4 en identificación de ambigüedad.

PRIG localiza ambigüedad en prompts de LLMs con atribución por sonda. Supera a GPT-5.4. ¡Mejora tus prompts ahora!

Descubre cómo la latencia de autocompromiso revela hacking implícito en modelos de lenguaje sin recompensa externa. Un nuevo enfoque para seguridad en IA.

Descubre cómo la latencia de autocompromiso detecta hackeo implícito sin modelos de recompensa. Una sonda para identificar atajos en el razonamiento de IA.

Echo-POSED: framework auto-supervisado para guía en ecocardiografía en tiempo real. Recomienda ajustes de sonda desde imágenes 2D sin etiquetas. Error angular medio de 8.2°.
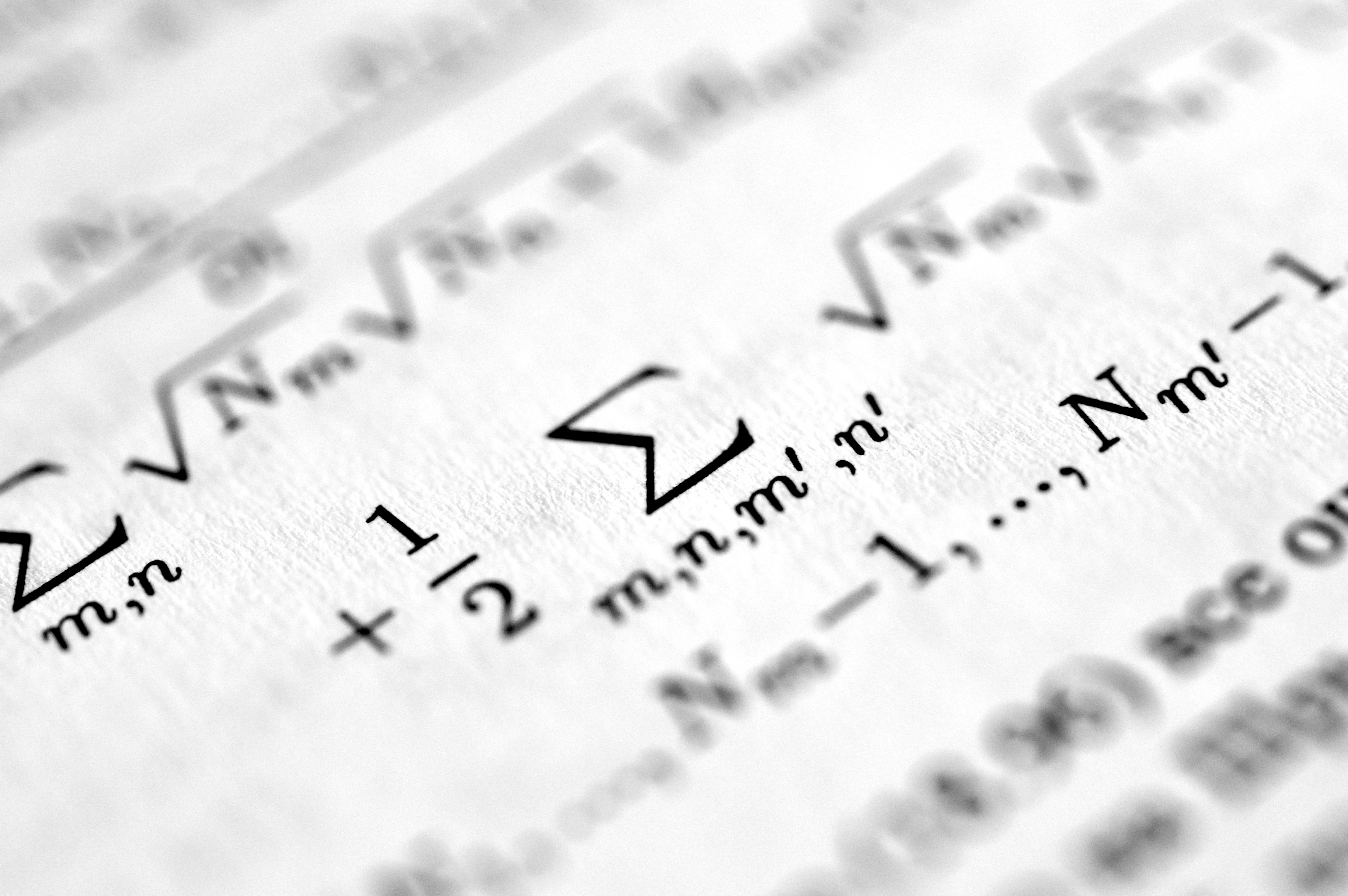
Descubre cómo los LLMs representan la suma geométricamente y por qué cometen errores. Un nuevo estudio revela la estructura oculta de la aritmética.

Descubre cómo X-RAY mapea la capacidad de razonamiento de los LLMs usando sondas formales y calibradas, revelando asimetrías y fallos interpretables.