
Elige el mejor almacén de vectores para búsqueda semántica
¿Buscas almacenar 4M vectores para búsqueda semántica? Comparamos pgvector, Pinecone, Weaviate y Qdrant. Descubre cuál escala a 300 req/s sin costos ocultos.
¿Buscas almacenar 4M vectores para búsqueda semántica? Comparamos pgvector, Pinecone, Weaviate y Qdrant. Descubre cuál escala a 300 req/s sin costos ocultos.

Aprende cómo la lógica defeasible de puntos de vista permite implicaciones no monótonas con condicionales situados y cierres racional y lexicográfico.

PRISM combina modelos de visión fundacionales con expertos autoorganizados, superando la transferencia negativa para lograr el estado del arte en segmentación.
Descubre cómo el marco STS evita el colapso de atención en VLMs, mejorando la diversidad estructural y la relevancia semántica de tokens visuales.

Descubre PHASER, un marco de aprendizaje continuo para modelos VLA que evita el olvido catastrófico. Asigna memoria por fases y prioriza tareas olvidadas, logra

El método SHARS reduce alucinaciones en generación de textos largos usando muestreo de rechazo. Mejora la consistencia factual sin recursos externos. ¡Descúbrelo!

Descubre cómo Taiji optimiza recomendaciones industriales con LLM, equilibrando semántica e IDs de usuario. Resultados reales en Kuaishou.

Descubre cómo EvoOR-Agent utiliza la coevolución de arquitecturas de agentes y razonamiento interpretable para optimizar procesos complejos con LLMs. Mejora el rendimiento y la interpretabilidad.

WISE: Benchmark que evalúa conocimiento mundial en T2I. 1000 prompts en 25 subdominios, WiScore mide cultura, espacio-tiempo y ciencia.
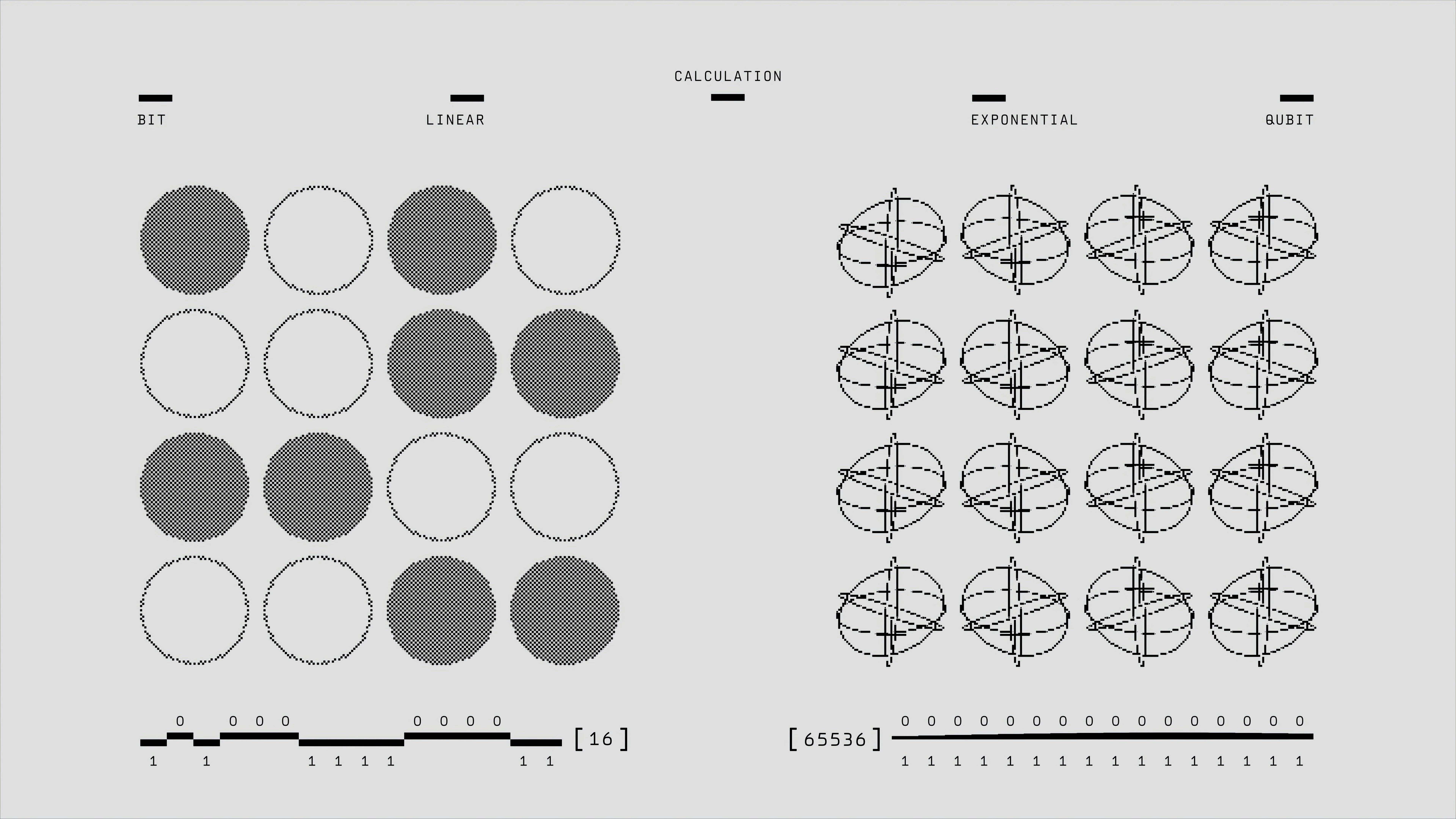
Descubre ReaLM, un innovador marco que une embeddings de KG y LLMs mediante cuantización residual para mejorar la completación de grafos. ¡Rendimiento líder!

Descubre cómo los modelos de lenguaje como ChatGPT revelan estructuras cuánticas similares a la cognición humana, apuntando a una convergencia evolutiva.
TimeOmni-VL unifica comprensión y generación de series temporales mediante visión, transformaciones bidireccionales sin pérdidas y generación guiada por entendimiento. ¡Lee más!

FederatedSkill permite a agentes LLM evolucionar habilidades colaborativamente y con privacidad, aumentando el éxito un 44% y reduciendo costos un 37%.

HiSE es un explicador ligero para redes neuronales de grafos heterogéneos con explicaciones semánticas jerárquicas de alta fidelidad y bajo costo.

Los tokens de grafo tienen alta activación pero baja utilidad semántica. Este análisis mecanicista revela la desconexión en modelos de lenguaje de grafos.

Descubre cómo el ajuste visual alinea imágenes y texto en modelos de lenguaje, optimizando el rendimiento multimodal sin aumentar el tiempo de entrenamiento.

D-Judge reescribe respuestas preservando semántica para desviar ataques multi-turno, reduciendo el éxito de jailbreaks en LLMs.

SVHalluc: nuevo benchmark para alucinaciones voz-visión en LLMs audiovisuales. Modelos fallan en alineación semántica y temporal.

Descubre EntangleCodec, el tokenizador de audio que unifica semántica y acústica. Mejora la comprensión de audio en un 7.4% y escala desde 0.6B a 8B parámetros, superando modelos mucho más grandes.

Un modelo compacto de percepción autónoma que integra múltiples sensores y aprendizaje balanceado para lograr mayor eficiencia y velocidad de inferencia.