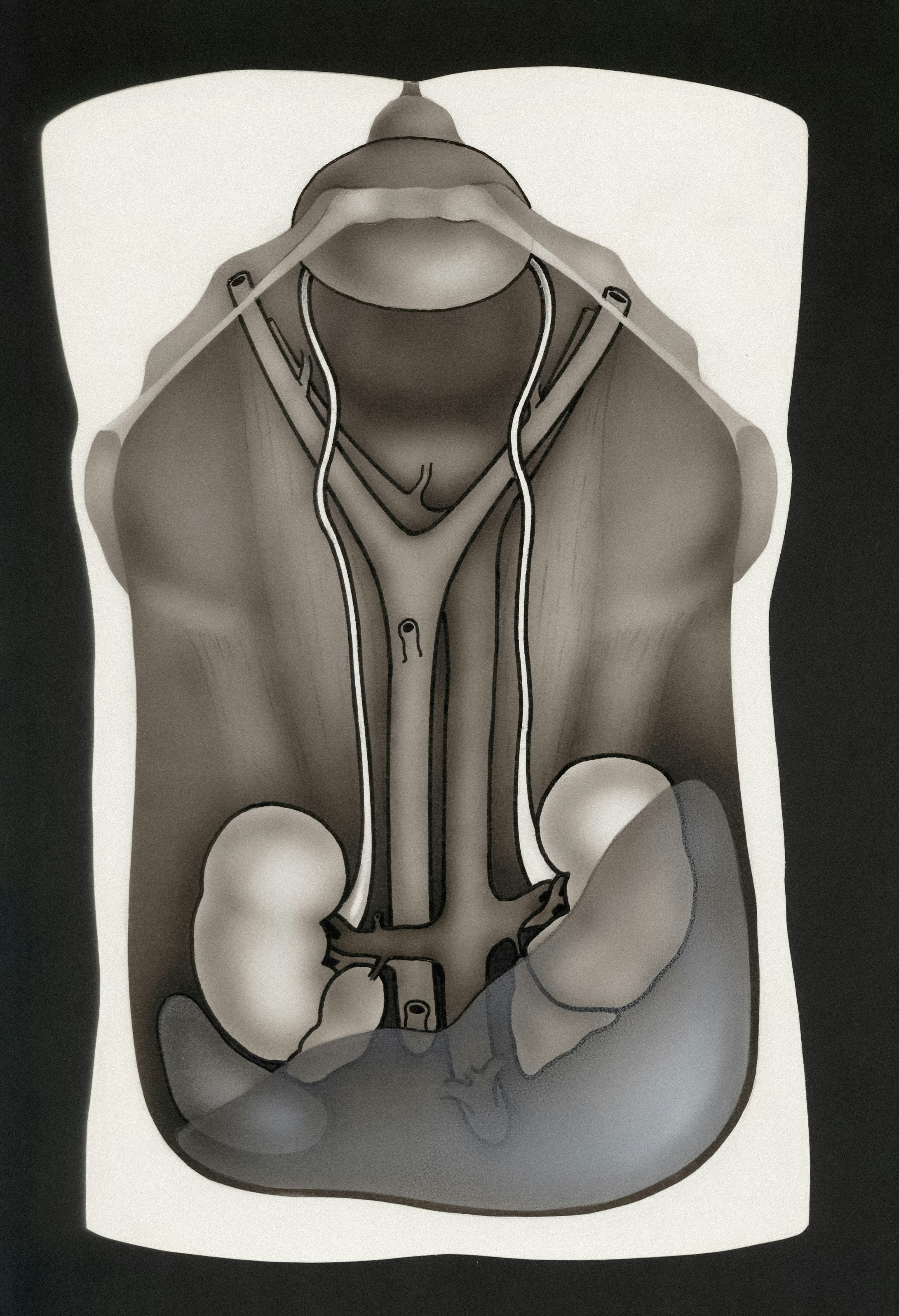
Segmentación 2D-U-Net multiplano de órganos abdominales con mapas de ocurrencia
Segmentación abdominal con 2D-U-Net multiplanar y mapas de ocurrencia espacial mejora precisión en CT 3D. Modelo ligero y eficiente.
Segmentación abdominal con 2D-U-Net multiplanar y mapas de ocurrencia espacial mejora precisión en CT 3D. Modelo ligero y eficiente.

GVC-Seg segmenta instancias 3D sin entrenamiento, elimina sesgo de confianza usando correspondencia geométrico-visual. Resultados de vanguardia.

¿El modelo SAM es ciego a las texturas? Revelamos dónde reside la evidencia y cómo interpretar sus fallos. Lectura esencial para investigadores en IA.

ActiveSAM acelera la segmentación de vocabulario abierto hasta 5.5x sin entrenamiento, superando a SegEarth-OV3 en precisión y robustez. Ideal para entornos

SLUM-i: aprendizaje semisupervisado para mapeo de asentamientos informales con mejora en calidad de datos. Logra +5.9 pp mIoU.

Descubre CLARITY, un framework de fusión RGB-T adaptativa guiado por lenguaje visual, que logra SOTA en segmentación de escenas de conducción (62.3% mIoU).

Descubre el dataset NEST3D: 1.4 TB de imágenes RGB y multiespectrales de nidos de tejedores sociables. Ideal para segmentación 3D y conservación de aves.
Descubre cómo los adaptadores de profundidad con preprocesamiento sinusoidal mejoran la precisión en tareas RGBD, alcanzando 56.05 mIoU en SUN-RGBD. Sin necesidad de ajuste fino.

Descubre cómo V-pretraining mejora capacidades objetivo usando pocos ejemplos finales como feedback, sin degradar la generalización. Ideal para modelos de lenguaje y visión.

Descubre LASA, un método de supervisión débil que segmenta bocetos con vocabulario abierto usando atención multi-capa. Mejora mIoU hasta +15.7. ¡Lee más!

Descubre cómo combinar datos sintéticos con solo un 20% de datos reales iguala y mejora la detección de grietas en mampostería con CNN. ¡Resultados sorprendentes!
Mejora la segmentación y profundidad con marginalización de fase en Vision Transformers. Sin entrenamiento, más precisión.

I-Segmenter: segmentación semántica eficiente con transformador de visión solo enteros, reduce tamaño 3.8x, acelera inferencia. Para dispositivos limitados.

Descubre PolyBuild, un método innovador que extrae directamente contornos de edificios en imágenes satelitales sin post-procesamiento. ¡Resultados superiores!

Aumenta la precisión de segmentación médica con predictor de cajas ligero integrado en MedSAM. Resultados: Dice 0.89-0.98 en múltiples modalidades.

PRISM combina modelos de visión fundacionales con expertos autoorganizados, superando la transferencia negativa para lograr el estado del arte en segmentación.

Un modelo compacto de percepción autónoma que integra múltiples sensores y aprendizaje balanceado para lograr mayor eficiencia y velocidad de inferencia.

Descubre FedS2R, el primer marco de generalización federada one-shot para segmentación semántica sintética-real en conducción autónoma, con mejoras en Cityscapes, BDD100K, Mapillary, IDD y ACDC.