
Deferral Forzado: Manipulación de Decisiones de Enrutamiento en Cadenas de MLLM
El ataque de deferral forzado (FDA) manipula la confianza del modelo débil en cascadas MLLM, forzando el uso del modelo fuerte.
El ataque de deferral forzado (FDA) manipula la confianza del modelo débil en cascadas MLLM, forzando el uso del modelo fuerte.

Sistema con IA, digital twin y LLMs para detectar fugas de agua en Jordania. Prueba de concepto logra respuesta en menos de 2 minutos y costo cero en API.

California Water Service investiga sin evidencia de interrupción operativa. Descubre cómo el incidente cibernético fue manejado.

Descubre cómo los CSAEs aprenden conceptos visuales jerárquicos en MLLMs, mejorando la interpretabilidad y permitiendo intervenciones grupales.

Explora cómo la clasificación en cascada con deep learning ofrece sensibilidad controlable para neoplasias cutáneas. Validación clínica externa y comparación de arquitecturas.

Evita que una API externa caiga todo tu sistema. Implementa cortacircuitos por slot para degradación elegante. Aprende cómo en Q2BSTUDIO.

Descubre cómo la regularización espectral logra un 94% de retención en disipación profunda para generar turbulencia más precisa.

Nuevo método adaptativo de filtrado semántico con LLM que acelera el proceso un 60-100% manteniendo 90% de precisión. Ideal para grandes volúmenes de datos.
Evita que un servicio lento derrumbe tu arquitectura Node.js. Aprende Timeout, Retry y Circuit Breaker para prevenir fallos en cascada.

Descubre el modelo online de la Caja de Pandora para cascada contextual de LLM: aprende a seleccionar APIs de lenguaje con mínimo regret gracias a la estimación de índices de reserva y GMM.

CascadeNet: nuevo método de aprendizaje automático que recupera redes de influencia oculta a partir de datos de cascada, sin necesidad de modelos de difusión pr

CascadeNet usa ML y Jacobiano para recuperar redes de influencia ocultas en datos en cascada, con validación en COVID-19.

Descubre MAGE, un sistema de gestión activa de estado que mejora el éxito de agentes IA en tareas largas hasta un 20% y reduce el consumo de tokens en un 55%.

Descubre cómo CHARM detecta alucinaciones en cascada en RAG con 89.4% de precisión y 5.3% de falsos positivos. Aprende a mitigar errores en pipelines RAG.

Descubre cómo D^2SD acelera la inferencia de modelos de lenguaje usando dos difusores para generar y verificar tokens en paralelo, mejorando la eficiencia.
Descubre cómo StepFinder identifica la causa raíz de fallos en sistemas multi-agente con un marco semántico temporal, reduciendo tiempos de inferencia un 79%.
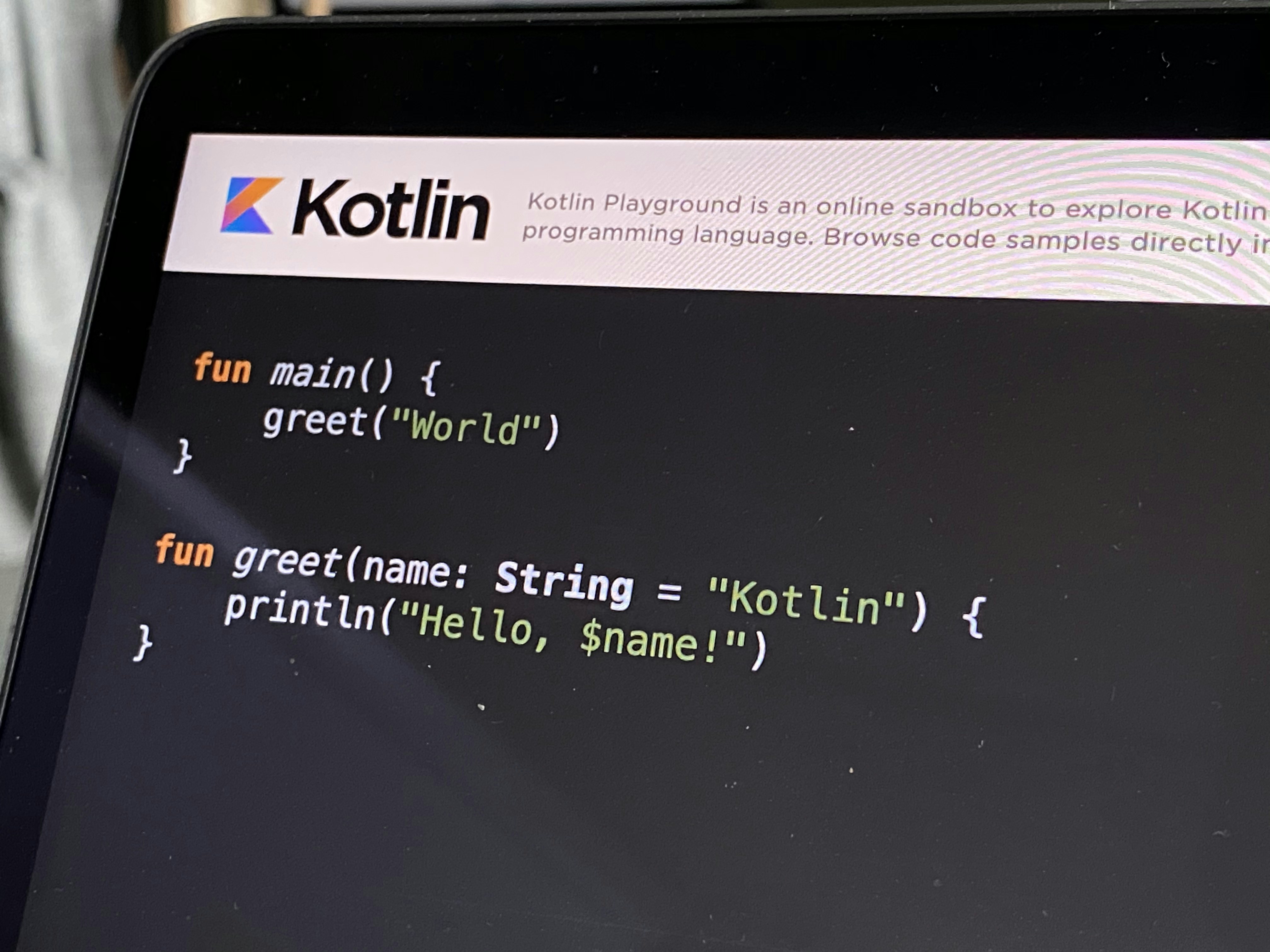
Descubre por qué Kafka no desacopla automáticamente tus servicios. Aprende los tipos de acoplamiento y cómo evitar fallos en cascada.