
Convergencia de aproximaciones bi-escala markovianas en RL
Descubre cómo se demuestra la convergencia de algoritmos bi-escala bajo ruido markoviano, un avance clave para el aprendizaje por refuerzo off-policy.
Descubre cómo se demuestra la convergencia de algoritmos bi-escala bajo ruido markoviano, un avance clave para el aprendizaje por refuerzo off-policy.
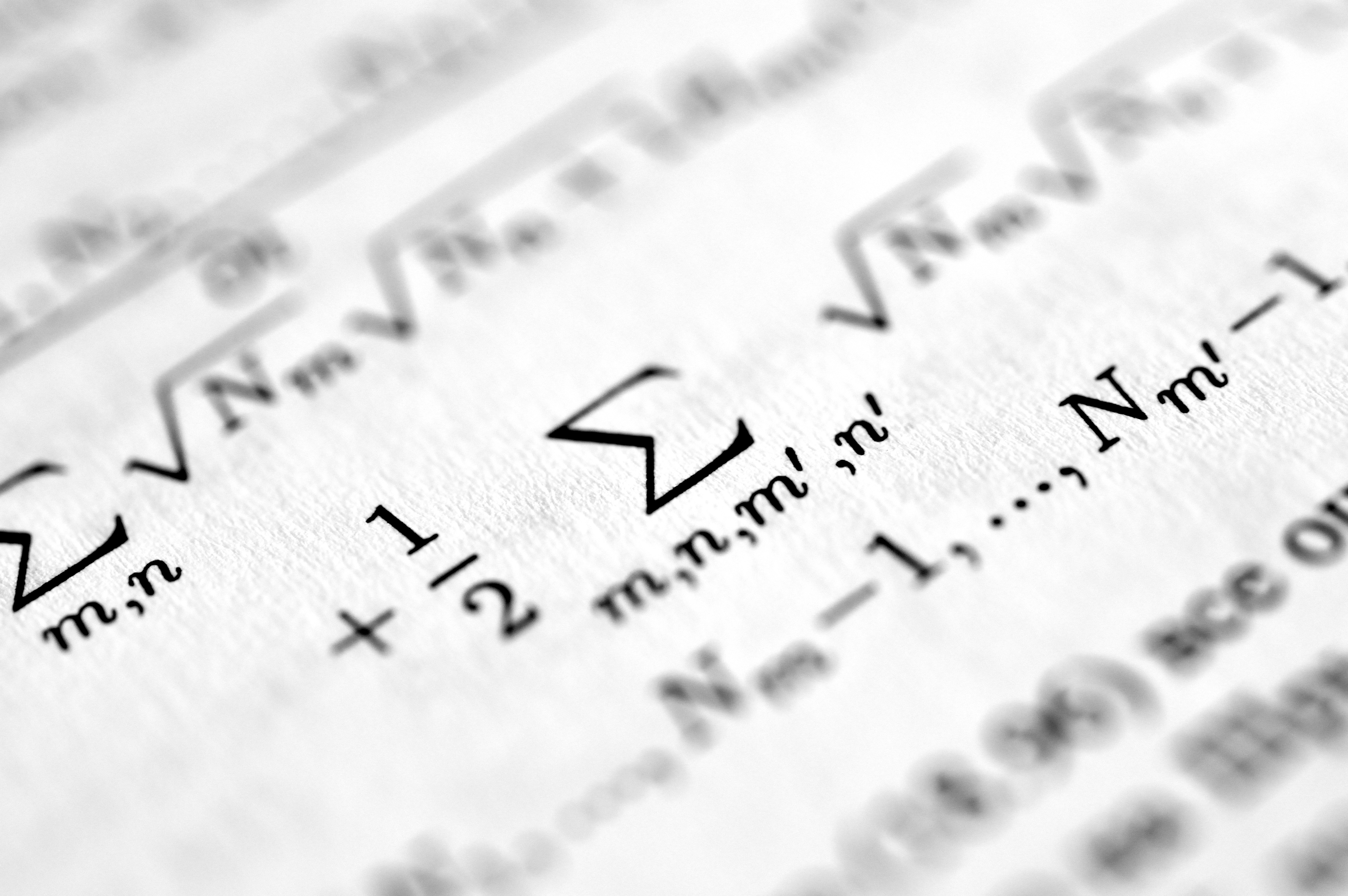
Descubre cómo las funciones de Lyapunov permiten analizar la convergencia finita de algoritmos estocásticos en aprendizaje automático y refuerzo.