
Aprendizaje Físico Contrastivo por Perturbaciones
El marco PCPL permite que sistemas físicos aprendan clasificaciones mediante contraste de respuestas a perturbaciones, sin retropropagación ni procesador externo.
El marco PCPL permite que sistemas físicos aprendan clasificaciones mediante contraste de respuestas a perturbaciones, sin retropropagación ni procesador externo.

Nuevo algoritmo de optimización Riemanniana descentralizada online con consenso curvatura y cota de arrepentimiento O(√T).

Descubre VP2O, el nuevo marco de optimización variacional que logra +179 ELO en Codeforces y reduce un 32% los tokens en tareas matemáticas.

Descubre HELiX, algoritmo que formaliza el aprendizaje de IA con retroalimentación lingüística, ofreciendo garantías demostrables y mejora exponencial.
Descubre cómo el feedback de usuarios potencia tu CRM. Captura sugerencias, prioriza mejoras y optimiza ventas y soporte.

Descubre cómo el Proceso de Engagement redefine la interacción temporal entre acción y observación en sistemas de IA, mejorando la adaptación en entornos dinámicos.

Estudio compara retroalimentación en escritura técnica de LLMs, SLMs y humanos. Los estudiantes valoran los modelos locales por su privacidad y costo cero.

Descubre ePC, una reformulación de la Codificación Predictiva que elimina el decaimiento de señal y acelera el entrenamiento de redes profundas.

Descubre cómo las consultas conversacionales proactivas aceleran la personalización en bandits multiobjetivo, mejorando decisiones con resultados teóricos.

Descubre cómo la IA y el aprendizaje por retroalimentación mejoran la calidad del software con una arquitectura de bucle cerrado que reduce fugas de defectos hasta un 35%.

Analizamos la mejora de agentes de investigación profunda con retroalimentación de proceso. Resultados: ganancias del 8-15% en puntuación, pero sin acumulación. ¡Entra!

Descubre cómo un LMS con IA mejora el rendimiento académico en secundaria a largo plazo. Estudio longitudinal con privacidad y retroalimentación temprana.
Descubre cómo el feedback de usuarios optimiza el process mining y la automatización en Q2BSTUDIO. Mejora continua basada en datos y sugerencias.
Nuevo benchmark Learn2Match usa IA para optimizar mercados de emparejamiento bilateral con retroalimentación temporal. Mejora eficiencia y reduce regret.
Descubre cómo MARL optimiza mercados de emparejamiento con retroalimentación extendida, superando a métodos tradicionales en bienestar social y regret.
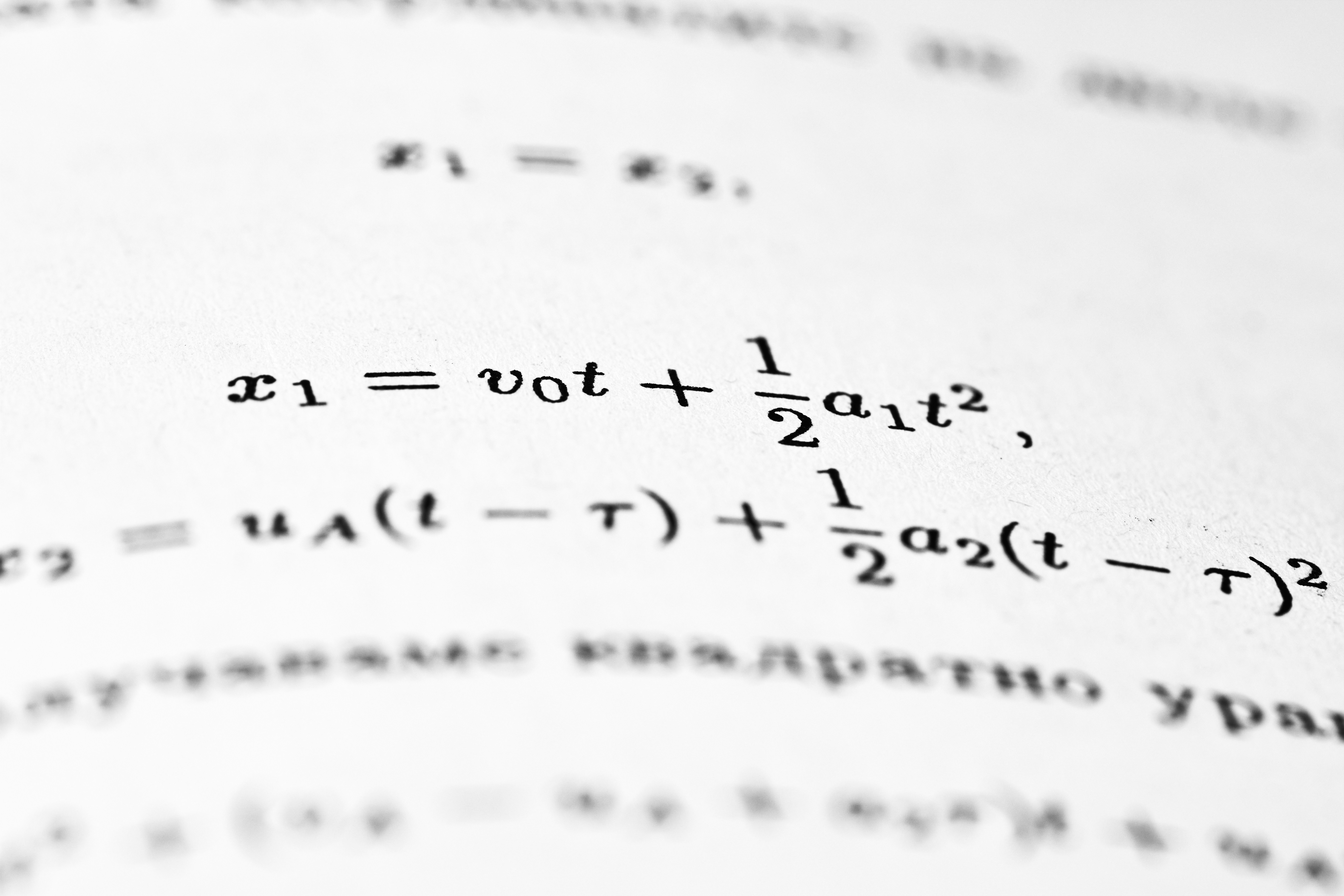
RCML mejora el control de restricciones en decisiones estocásticas usando aprendizaje residual, reduce ruido y estabiliza convergencia.

Descubre RETROSPECT, un sistema que combina un Transformer con un reranker para mejorar la retrosíntesis en química. Hasta 55% top-1 exacto.
Un estudio exhaustivo compara el razonamiento humano con el de DeepSeek-R1 en 30 problemas de AIME 2025, revelando diferencias estructurales y señales de razonamiento genuino.

¿Cómo lanzar una app que realmente vende? Un desarrollador comparte su experiencia creando Visual Minipro para Mac, superando rechazos de Apple y logrando sus primeras ventas.
Descubre cómo el feedback impulsa la precisión del RAG para conocimiento interno y reduce la duplicación de trabajo. Mejora continua con Q2BSTUDIO.