
Medida de Relevancia Normalizada para Explicar Redes Neuronales
Descubre cómo la medida de relevancia normalizada unifica la explicación de estructuras latentes en redes neuronales, mejorando la transparencia en IA.
Descubre cómo la medida de relevancia normalizada unifica la explicación de estructuras latentes en redes neuronales, mejorando la transparencia en IA.
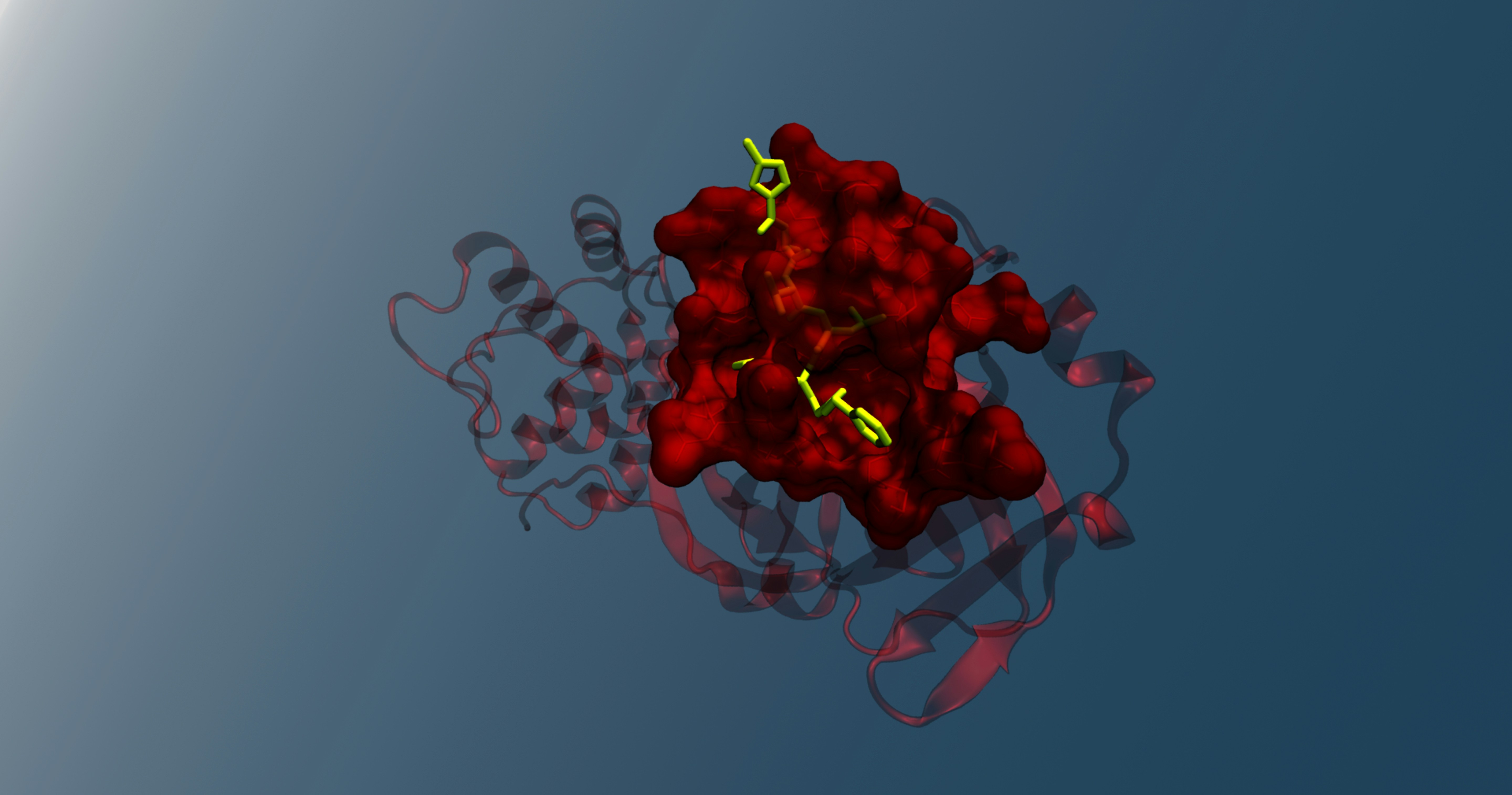
CryoProt revoluciona el análisis de proteínas con IA: modela interacciones entre cajas en mapas crio-EM para predicciones precisas. Mejora hasta un 12%.

Nuevo marco de aprendizaje por refuerzo offline que aprende representaciones sin recompensa y las afina con preferencias humanas, superando a métodos tradicionales en eficiencia.

Descubre cómo la escala en modelos de secuencias simpliciales se correlaciona con estructura y rendimiento en transformers. Un estudio revela patrones predecibles.
Descubre el marco bootstrap para aprender representaciones latentes: del rendimiento a la viabilidad en sistemas biológicos adaptativos.

¿Cómo se relacionan las leyes de escalado con las representaciones internas en deep learning? Este estudio revela una correlación entre rendimiento y estructura

Algoritmo en línea biológicamente plausible para representaciones dispersas e invariantes. Ideal para clustering, teselado y codificación en grandes datos.

¿Sabías que DQN y PPO aprenden representaciones invariantes diferentes? Descubre cómo afecta a la transferencia y la neurociencia.
FedSAP cierra la brecha de alineación-madurez en aprendizaje federado con prototipos, logrando hasta 4 puntos en datos no-IID y se extiende a semi-supervisado.

Descubre cómo las codificaciones posicionales anclan la estructura espacial en Vision Transformers y mejoran la robustez. La métrica SSDC revela la geometría.

Descubre cómo las representaciones semánticas SSL reducen 39 veces el FID en ImageNet, optimizando la generación en un paso sin métricas hackeadas.

Descubre cómo resolver conflictos de optimización entre ReID por imagen y texto. Un entrenamiento desacoplado mejora representaciones compartidas.
Descubre cómo Geodesic Flow Matching reduce un 72% el error en SLAM neuronal y mejora un 40% la eficiencia neural mediante representaciones de alta dimensión.

Una investigación revela que los Transformers aprenden inferencia transitiva mediante una geometría ordinal emergente, replicando el efecto de distancia simbólica observado en humanos y animales.

LLMs y EEG comparten un eje de valencia. La saturación limita la supervisión. Descubre cómo un ensamble mejoró un 10.5% la precisión en FACED.

¿Son únicas las representaciones que aprende tu modelo? Descubre el criterio de fibra para identificar si las propiedades de representación son identificables en aprendizaje supervisado.

Descubre en este estudio comparativo las diferencias clave entre políticas VLA y modelos WAM en comportamiento y representaciones internas.

Descubre cómo los modelos de lenguaje grandes representan diferentes idiomas desde un punto de vista estructural y qué diferencias clave existen entre lenguas de bajos y altos recursos.

Mejora el razonamiento algorítmico neuronal con reconstrucción auxiliar: representaciones más ricas que potencian el rendimiento de arquitecturas existentes.
Descubre cómo VRPO mejora el alineamiento de representaciones en difusores mediante optimización por refuerzo, logrando +1.8 FID y 2.3x más rápido que REPA.