
Caracterizando la geometría discreta de las redes ReLU
Las redes ReLU generan regiones lineales. El grado promedio de su grafo está acotado por el doble de la dimensión de entrada y su diámetro es independiente.
Las redes ReLU generan regiones lineales. El grado promedio de su grafo está acotado por el doble de la dimensión de entrada y su diámetro es independiente.

Descubre cómo la dinámica de aprendizaje revela una jerarquía de métricas Gram inducidas por pesos en redes ReLU. Optimiza tu entrenamiento profundo.
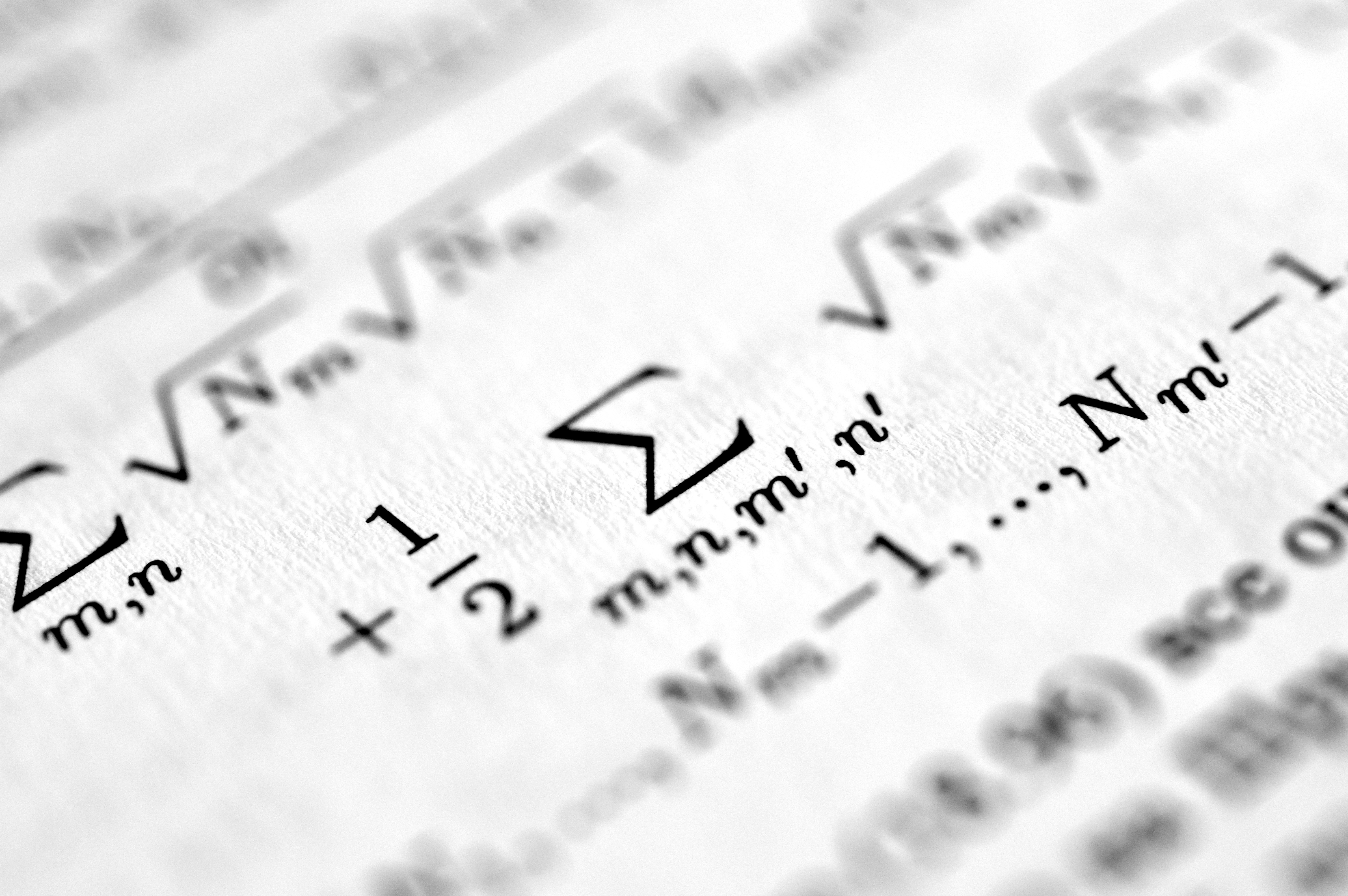
Aprende cómo la geometría de características aprendidas mejora la generalización en mínimos cuadrados no lineales, reduciendo la dependencia de parámetros.

SmartMixed: una estrategia en dos fases para que cada neurona aprenda su función de activación óptima. Mejora eficiencia y rendimiento en redes neuronales.

Descubre cómo GD y SGD alcanzan tasas óptimas de generalización en redes ReLU profundas, con resultados minimax comparables a kernels.

Descubre cómo SIREN, ReLU y Fourier-Features afectan la especificidad de transferencia en redes neuronales implícitas.

Descubre cómo la arquitectura afecta la transferencia en redes implícitas. Estudio comparativo de SIREN, ReLU y Fourier para modelos científicos.

Aprende cómo las redes neuronales con activaciones suaves mitigan la maldición de la dimensionalidad, garantizando convergencia uniforme y robustez en regresión. ¡Entra!

Cómo el fenómeno Grokking separa el ajuste de datos de la simplificación de representaciones con dos relojes de entrenamiento. Teoría de redes lineales y ReLU.

Descubre cómo entrenamiento condicionado por camino reescala redes ReLU para acelerar aprendizaje. Enfoque geométrico optimiza kernels y mejora inicialización.

Aprende cómo el descenso de gradiente logra convergencia lineal en redes ReLU, evitando puntos silla y alcanzando el mínimo global.

Descubre la inicialización Lyapunov para redes Leaky ReLU: cómo lograr estabilidad en activaciones y mejorar el aprendizaje en redes profundas.
Nuevo marco de aproximación cuantitativa mejora la destilación de flujo en difusión, reduciendo errores hasta 51.9% con particiones no uniformes.

Descubre cómo las redes neuronales ReLU aproximan medidas rectificables con error mínimo en distancia de Wasserstein, mejorando tasas según el parámetro m.

Descubre cómo el descenso de gradiente logra tasas de generalización óptimas en redes ReLU profundas con dependencia polinomial de la profundidad, mejorando resultados previos.

Nueva teoría de bifurcación revela que reemplazar ReLU por activaciones no monótonas evita el sobresuavizado en GNNs profundas. ¡Descubre la solución!

Descubre cómo se caracterizan los mínimos locales en redes ReLU de dos capas y cómo la sobreparametrización facilita el acceso a mínimos globales.

Descubre cómo el enfoque Multigrade Deep Learning permite entrenar redes profundas por grados, reduciendo errores residuales y garantizando convergencia uniforme en arquitecturas ReLU.

CART es un transformer recurrente que reduce parámetros al reutilizar un bloque central. Con estabilidad aprendida vía puerta LTI, ofrece resultados competitivos en GPU de consumo.

Descubre cómo la inferencia bayesiana en MLPs profundos no lineales se simplifica a un método kernel y cómo la profundidad mejora la evidencia del modelo. Una nueva perspectiva teórica.