
Relación entre CoCoA y ADMM en minimización de riesgo empírico distribuida
Descubre la relación entre CoCoA y ADMM en minimización de riesgo empírico distribuida y por qué ADMM puede superar a CoCoA.
Descubre la relación entre CoCoA y ADMM en minimización de riesgo empírico distribuida y por qué ADMM puede superar a CoCoA.

Preserva la alineación de seguridad de tus LLMs durante el fine-tuning con PACT: restricciones focalizadas en tokens de seguridad que evitan la deriva sin sacrificar rendimiento.

Descubre cómo Policy Split mejora la exploración dual en LLMs con regularización de entropía para mayor precisión y creatividad.

Descubre SDPG, un marco de gradiente de política autodestilada que estabiliza el entrenamiento de LLMs mediante autorefuerzo y ventajas de grupo.
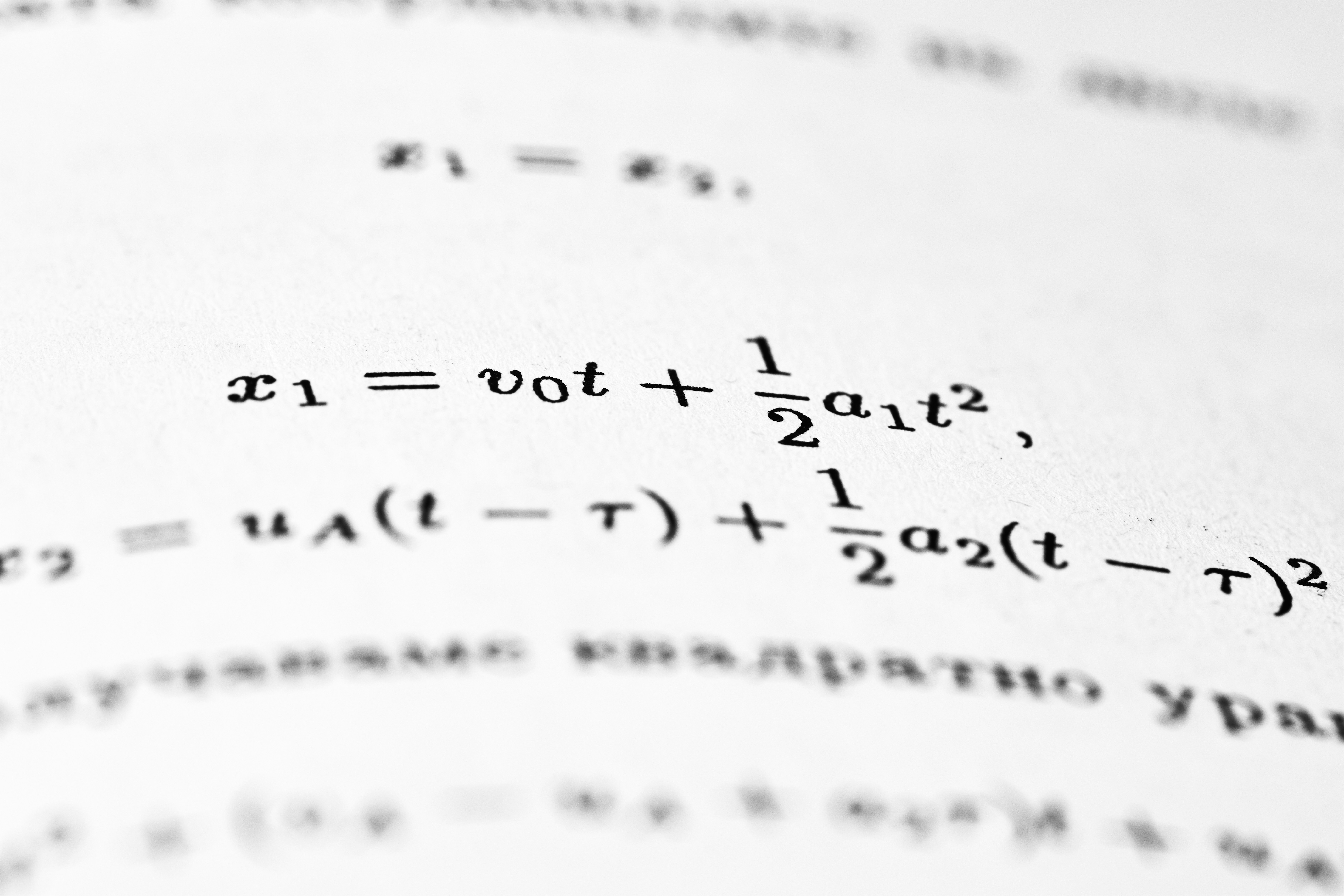
Descubre cómo la compresión aproximada garantiza predicciones confiables en secuencias, incluso con errores de optimización. Un análisis teórico del MDL.

Descubre AlphaQ, un método sin calibración que asigna bits a expertos en MoE basado en la pesadez espectral. Logra compresión 4x con precisión casi total.

OpenRFM mejora un 30% el rendimiento en tareas relacionales. Su arquitectura dual y preentrenamiento inteligente superan a modelos comerciales.

Descubre cómo el decaimiento de bajo rango (LRD) acelera el grokking en transformers invariantes a escala, comprimiendo valores singulares.

ReLoRA acelera la reutilización de adaptadores LoRA para servicios LLM en evolución, reduciendo tiempos de preparación hasta 8.9x y mejorando precisión un 4.6%.

Algoritmos que logran límites de arrepentimiento adaptativos a datos y varianza en MDPs tabulares online, óptimos en entornos adversariales y estocásticos.

Aprende cómo un algoritmo SBL estima núcleos de interacción en el modelo Motsch-Tadmor, cuantificando incertidumbre a partir de datos de trayectoria.

Descubre cómo un nuevo algoritmo espectral logra recuperación parcial y consistencia débil en el modelo HSBM no uniforme para detección de comunidades en hipergrafos.

Algoritmo SNMPBB: gradiente no monótono para NMF simétrica. 6x más rápido que alternativas y superior en clustering de grafos. ¡Optimiza!

Descubre cómo la Destilación de Confusión (CD) mejora el aprendizaje de modelos sin profesor, superando a otros métodos en CIFAR-100.

Analizamos el aprendizaje de características en destilación de conocimiento y presentamos Confusion Distillation, una auto-destilación eficiente que supera a otros métodos en 1.2%.

Annot-Mix mejora el entrenamiento con etiquetas ruidosas de múltiples anotadores vía Mixup. Superior a 11 enfoques en 11 datasets.

¿Sabías que la estimación honesta en bosques causales puede reducir la precisión? Descubre cuándo ayuda y cuándo perjudica en más de 7,000 conjuntos de datos.

Descubre AReT: la nueva técnica de IA que logra volumetría de nódulos pulmonares con solo 3 radiografías. Precisión del 98.3% y error del 11.4%.

Estudio revela que el reordenamiento con LLM puede amplificar contenido extremo, pero una regularización ligera mejora la diversidad ideológica.
Descubre cómo el grokking en regresión ridge demuestra que la generalización tardía no es un fallo de deep learning. Aprende a controlarlo con hiperparámetros.