
Repensando la Regularización de Divergencia en RL para LLMs
Descubre DRPO: un nuevo método que reemplaza el recorte de ratio con regularización cuadrática suave para estabilizar el entrenamiento RL en modelos de lenguaje.
Descubre DRPO: un nuevo método que reemplaza el recorte de ratio con regularización cuadrática suave para estabilizar el entrenamiento RL en modelos de lenguaje.
GraphNC calibra la normalidad en detección de anomalías en grafos. Usa datos etiquetados y no etiquetados para reducir falsos positivos y mejorar la precisión.

Optimiza la programación logística portuaria con aprendizaje continuo, mejorando la generalización y reduciendo costos. ¡Lee más!

Descubre cómo ERSM mejora la robustez e interpretabilidad de modelos de visión al reducir redundancias y aislar objetos.
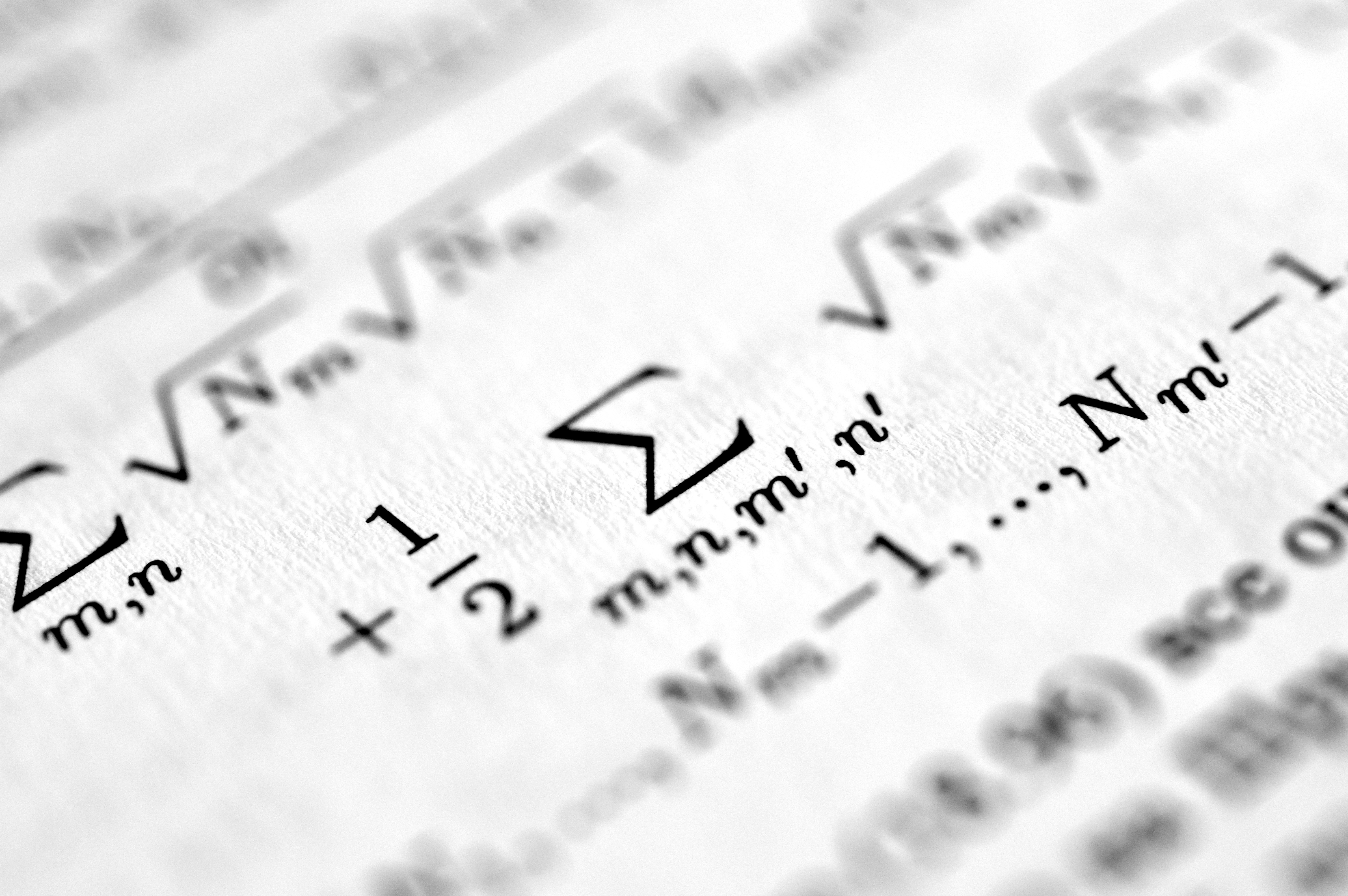
Aprende cómo la geometría de características aprendidas mejora la generalización en mínimos cuadrados no lineales, reduciendo la dependencia de parámetros.
Descubre las curvas de error de generalización en regresión kernel con decaimiento de potencia y su impacto en redes neuronales anchas.

Descubre cómo mejorar la optimización convexa estocástica cuando se desconocen parámetros clave. Métodos para evitar sobreajuste y lograr complejidad de muestreo óptima.

Descubre cómo el moldeado de recompensas desde la perspectiva del juego de Stackelberg mejora la alineación de LLMs en inferencia, reduciendo sesgos y aumentando el rendimiento.

Descubre Hyperflux, un método de poda que revela la importancia de cada peso mediante flujo y presión. Reduce latencia y energía manteniendo precisión.

Descubre cómo tratar la equidad como operación de simetría reduce sesgos en modelos de IA hasta un 90% con solo un 5% de pérdida de precisión.

SCALE es un planificador DRL que escala a clústeres de cualquier tamaño sin reentrenamiento, reduciendo el tiempo de respuesta hasta un 8.9%.

Descubre cómo la asimetría de estabilidad entre el razonamiento interno y las respuestas externas revela el engaño en LLMs, y cómo una nueva regularización lo mitiga sin perder capacidad.

La regularización MIR y la ley SoftQ mejoran el preentrenamiento con datos limitados, equivalente a 1.3 veces más datos.

Nuevo estudio propone regularización MIR y ley de escalado SoftQ para pretraining con datos limitados, logrando mejoras equivalentes a 1.3x más datos únicos.

Aprende a construir espacios latentes de VAE con topología prescrita, resolviendo el desajuste topológico y mejorando la calidad de reconstrucción en datos no euclidianos. Resultados superiores.
Descubre cómo SWUDI resuelve la fusión de modelos multitarea con regularización espectral cerrada, acelerando 28-72x sin datos de entrenamiento.
Descubre la contracción de covarianza con interpolación estocástica: reduce riesgo y permite regularización de autovectores. Aplicaciones en neuroimagen.
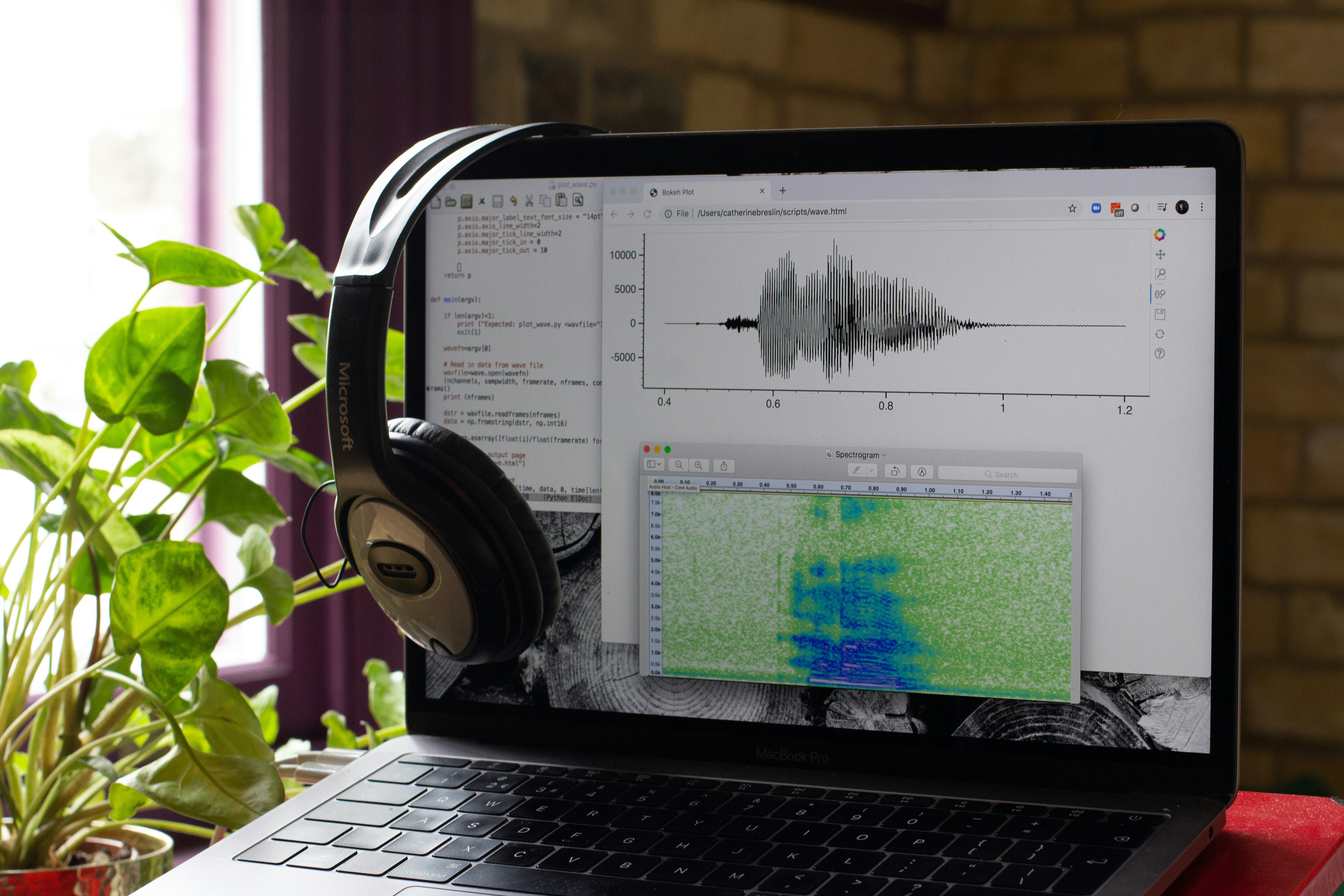
Descubre cómo el entrenamiento consciente de puntuación permite generar música de alta calidad con pocos datos. Nuestro modelo FluxAudio rankeó 2° en ICME 2026.

Descubre cómo detectar cambios en sistemas dinámicos ruidosos usando operadores de transferencia empíricos. Aprende el método con garantías de falsa alarma y aplicaciones en series temporales.
Nuevo enfoque: interpolación estocástica para contraer covarianza. Descubre tres mecanismos (planificación, flujo, parada temprana) que reducen el riesgo estadístico en datos de alta dimensionalidad.