
Diagnóstico de fallos en colaboración visual con recursos limitados
Descubre cómo estado compartido amplifica alucinaciones en agentes visuales limitados. Dos modos de fallo y marco CoSee para mejorar la fiabilidad comunicativa.
Descubre cómo estado compartido amplifica alucinaciones en agentes visuales limitados. Dos modos de fallo y marco CoSee para mejorar la fiabilidad comunicativa.

Exploramos cómo ASP crea abstracciones potentes para Reinforcement Learning usando el framework CARCASS. Casos en Blocks World y Minigrid.

Descubre cómo el Monte Carlo secuencial reforzado mejora el muestreo amortizado de distribuciones complejas. Entrenamiento off-policy y temperado adaptativo para mayor precisión.

Descubre cómo el aprendizaje por refuerzo multiagente escalable resuelve restricciones globales mediante consenso distribuido, superando limitaciones de CTDE.

¿Cómo mejoran los modelos mundiales con teoría de la mente la coordinación multiagente en entornos parcialmente observables?

Los LLMs pueden pronosticar el rendimiento de kernels GPU funcionando como sustitutos selectivos. Esto permite explorar más candidatos y hallar kernels más rápidos con menor costo de medición.

ReuseRL aplica el principio de compresión para que agentes de IA generalicen mejor. Aumenta el éxito en ALFWorld y TextWorld. ¡Descúbrelo!

LongTraceRL mejora el razonamiento en contexto largo usando recompensas de rúbrica y distractores por niveles desde trayectorias de agentes de búsqueda.

Descubre cómo los modelos de lenguaje infieren eventos a partir de series temporales usando datos deportivos. Un nuevo benchmark y técnicas de destilación mejoran el rendimiento.

Descubre cómo dos comunidades unifican enfoques para recuperar recompensas desde datos offline. Análisis de identificación y algoritmos IRL/DDC.

El 'colapso cero' es un fallo crítico en métodos de gradiente de política en subastas. Aprende a evitarlo con estrategias prácticas de inicialización y arquitectura.

Aprendizaje por refuerzo e inferencia recursiva automatizan verificación formal. Logros: del 2% al 58% en Dafny y mejoras en Lean.

Descubre cómo SDM-Q usa aprendizaje por refuerzo para clasificar enfermedades con menos datos ómicos, reduciendo costes y manteniendo precisión.

Analizamos los desafíos del RL en sistemas energéticos reales: observabilidad, diseño de acciones, recompensa y la brecha simulación-realidad.

Descubre cómo se demuestra la convergencia de algoritmos bi-escala bajo ruido markoviano, un avance clave para el aprendizaje por refuerzo off-policy.
Descubre SDRL, un nuevo método de aprendizaje por refuerzo distribucional que usa divergencias cortadas para manejar distribuciones multivariantes. Mejora en juegos Atari y entornos complejos.

Descubre cómo Survival RL supera el dilema del contraste, logrando 2x a 8x mejor rendimiento en robótica de largo plazo. ¡Auto-supervisado y escalable!
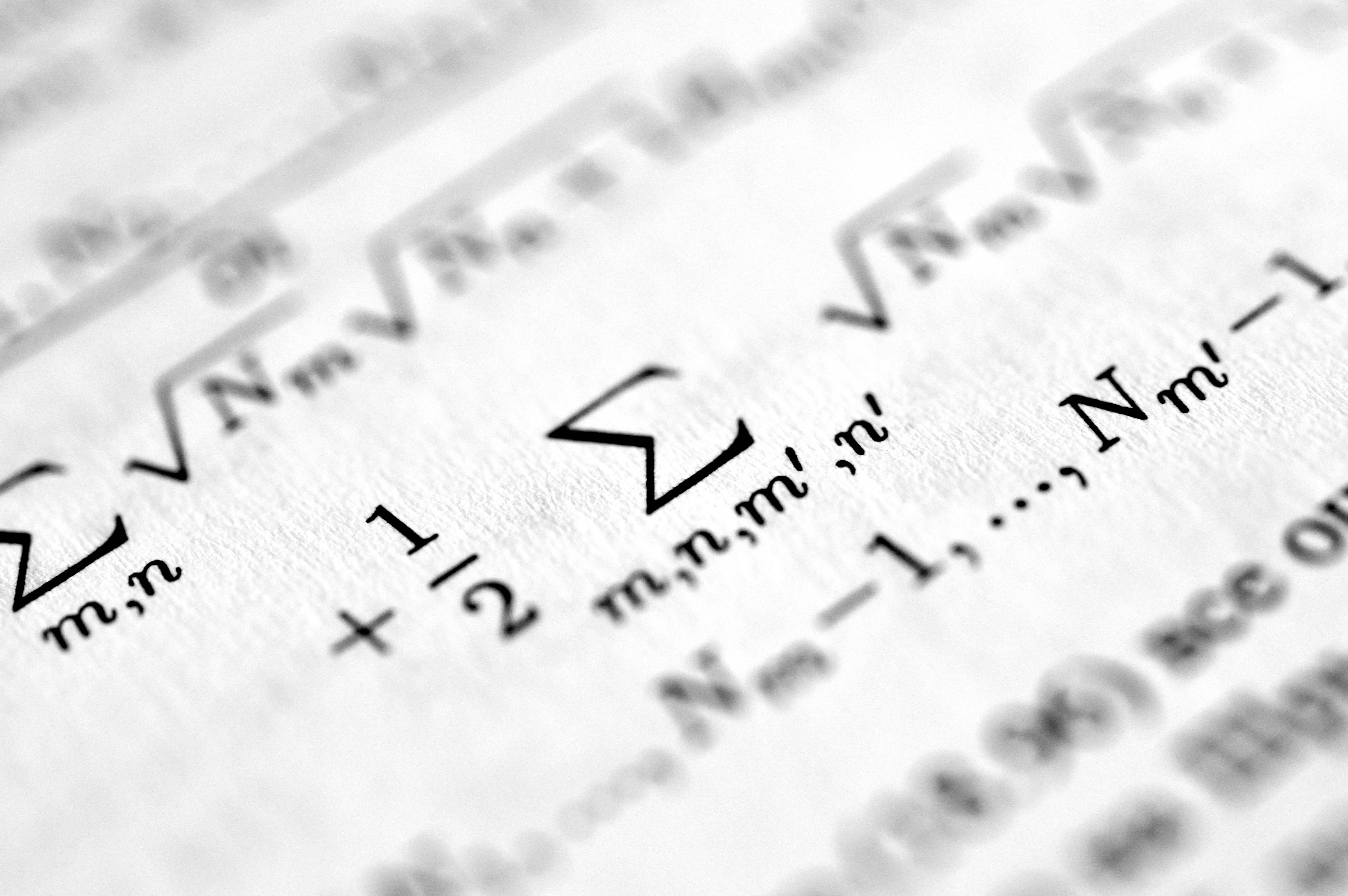
Descubre cómo el marco de Lyapunov permite analizar la convergencia en tiempo finito de algoritmos estocásticos como Q-learning y SGD. Ideal para IA y RL.
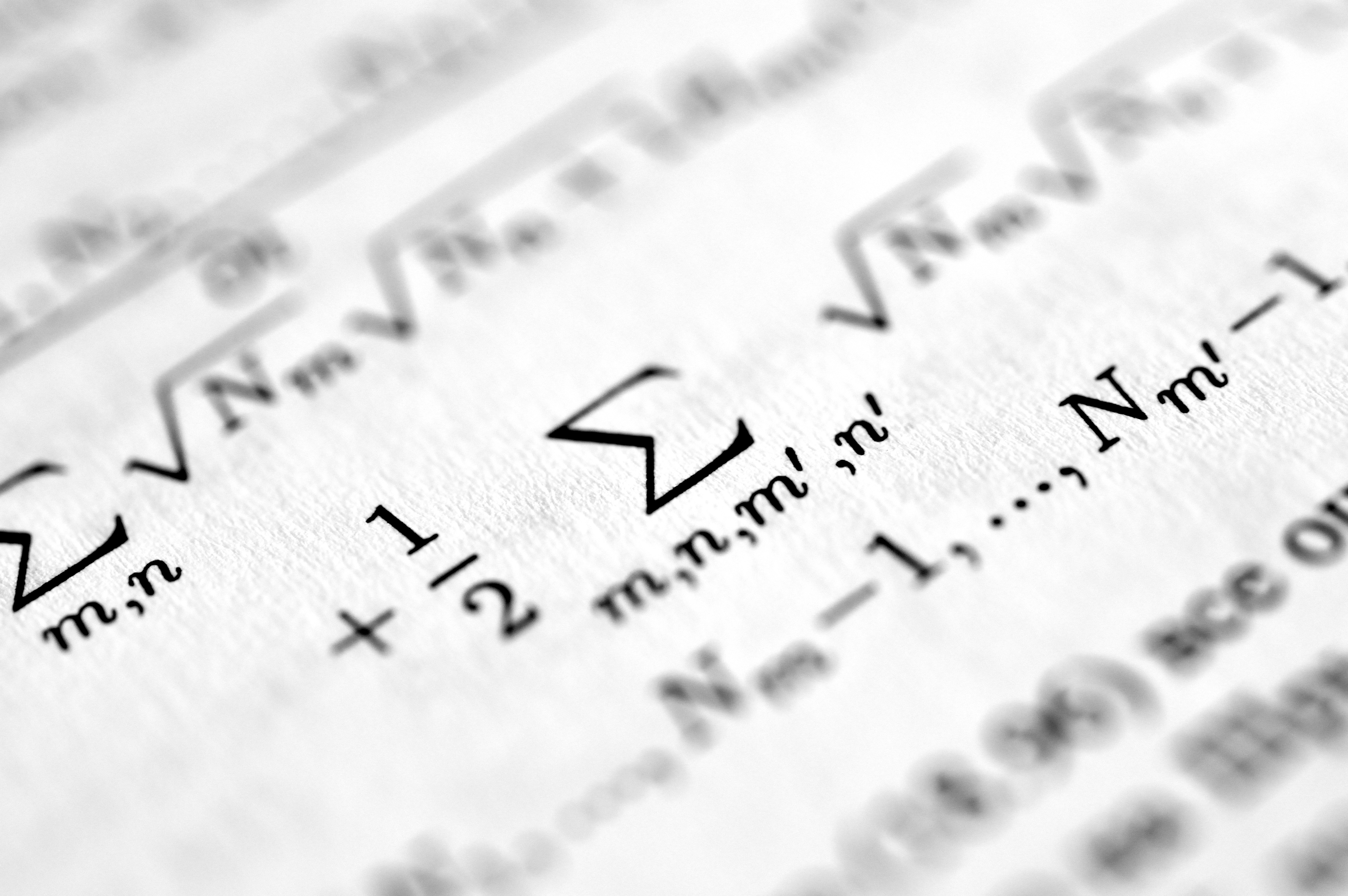
Descubre cómo las funciones de Lyapunov permiten analizar la convergencia finita de algoritmos estocásticos en aprendizaje automático y refuerzo.

Descubre cómo el nuevo marco MORL con criterio max-min logra equidad y cumple restricciones en control térmico, locomoción y tráfico. ¡Optimiza decisiones multiobjetivo!