
Las 20 mejores empresas para empleado de IA frente a humano en Madrid
Descubre las 20 empresas de Madrid que prefieren empleados de IA a humanos. Una tendencia laboral que está transformando el mercado.
Descubre las 20 empresas de Madrid que prefieren empleados de IA a humanos. Una tendencia laboral que está transformando el mercado.
<meta name=description content=TD-Lambda Adaptativo para Aprendizaje Cooperativo Multiagente - Descubre cómo mejorar el aprendizaje cooperativo multiagente con TD-Lambda adaptativo. Optimiza la colaboración y eficiencia en entornos multiagente.>

<meta name=description content=Descubre cómo el meta-aprendizaje por refuerzo con mínima atención optimiza el aprendizaje adaptativo. Técnica eficiente y clave en IA.>
Aprendizaje por refuerzo remoto robusto en canales no confiables con codificación homomórfica. Técnica innovadora para RL distribuido seguro y fiable.
Computación como maestro: de inferencia a supervisión sin referencia. Descubre cómo este enfoque redefine el aprendizaje automático sin necesidad de referencias.
Aprendizaje por refuerzo multi-agentes descentralizado: descubre cómo el modelado de contexto resuelve problemas complejos en sistemas distribuidos.

ETS: Escalado de prueba guiado por energía para alineación de RL sin entrenamiento. Descubre cómo esta técnica optimiza la alineación del aprendizaje por refuerzo sin entrenamiento adicional, usando la energía como guía.

Descubre f-GRPO y algoritmos de RL basados en divergencia para alinear LLMs. Técnicas avanzadas de alineamiento de modelos de lenguaje.

Descubre cómo la conectividad afecta las representaciones laplacianas en RL, mejorando la eficiencia y generalización del aprendizaje por refuerzo.
Escalado adaptativo en aprendizaje por refuerzo con restricciones: optimiza políticas respetando límites. Descubre cómo mejora la eficiencia y el rendimiento.
Descubre a los 30 mejores expertos en inteligencia artificial de Murcia. Conoce a los profesionales que lideran la innovación en IA.
<meta name=description content=Modelado_y_evaluación_comparativa_de_recompensas_de_diálogo_hablado._Análisis_de_técnicas_para_optimizar_sistemas_conversacionales.>

Android 17 refuerza protección contra estafas bancarias y privacidad con nuevas funciones de seguridad. Descubre cómo proteger tus datos.
<meta name=description content=Kintsugi reparar bases ejecutables para aprender políticas. Descubre cómo esta técnica japonesa de reparación optimiza el aprendizaje de políticas de forma innovadora.>

Descubre cómo los modelos de recompensa de proceso no supervisados optimizan el aprendizaje sin etiquetas. Una guía esencial para investigadores y desarrolladores.
Deep RL optimiza semáforos para lograr eficiencia y equidad en el tráfico urbano. Mejora la movilidad y reduce esperas
Descubre cómo el aprendizaje de recompensas de progreso con ProcVLM optimiza la manipulación robótica. Un enfoque innovador para mejorar el desempeño en tareas complejas.
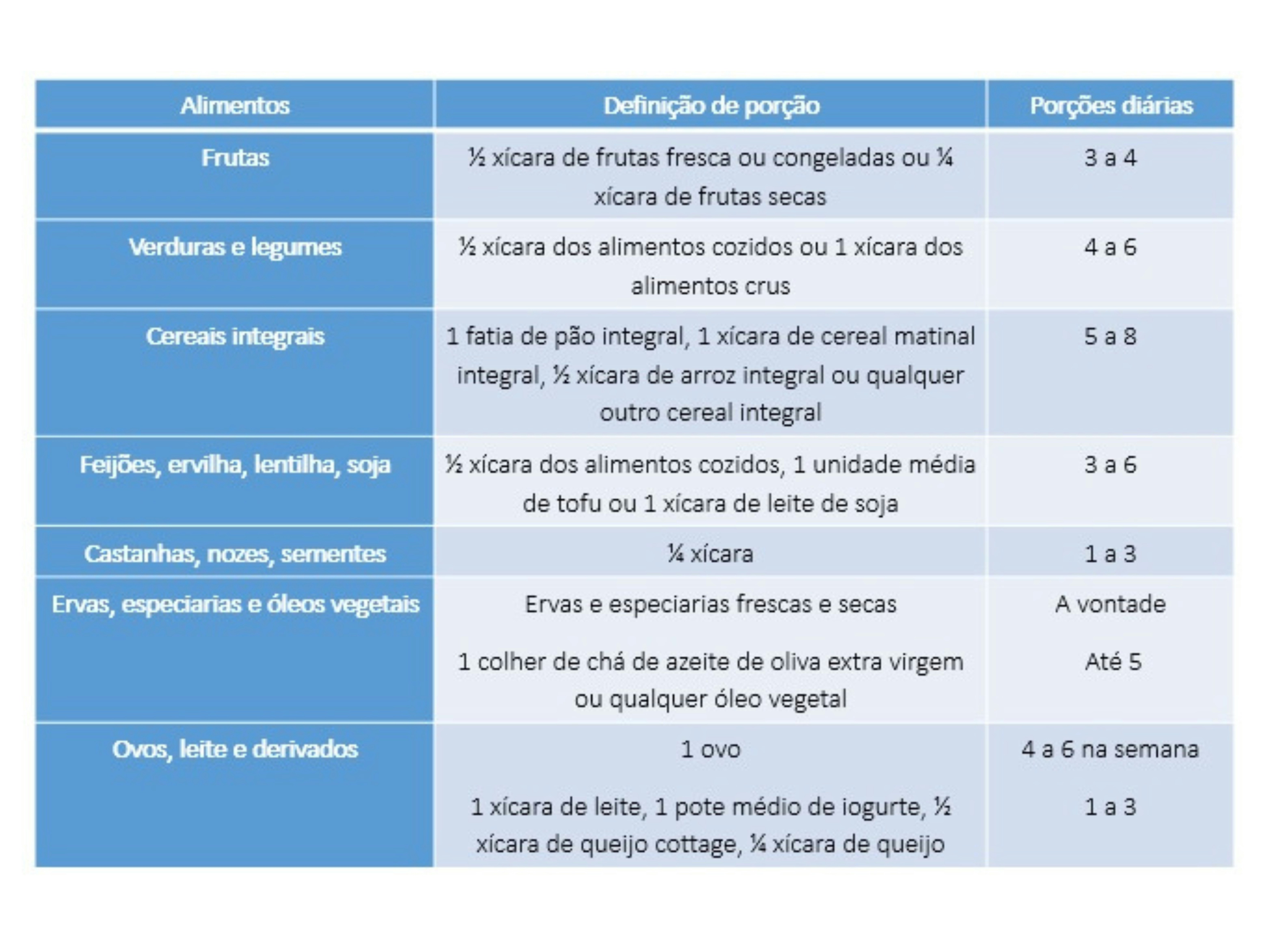
Descubre las métricas fundamentales para medir el aprendizaje por refuerzo: recompensa acumulada, eficiencia y convergencia. Optimiza tus modelos con esta guía clara.

<meta name=description content=Arrepentimiento óptimo en bandidos de índice único: estrategias y resultados. Una guía para minimizar el arrepentimiento.>

<meta name=description content=Supera el olvido catastrófico en visión con ajuste fino por refuerzo. Técnicas para conservar el aprendizaje y optimizar modelos.>