
GLIDE: Inferencia basada en predicciones para evaluar sistemas GenAI
GLIDE: biblioteca Python que combina anotaciones humanas y predicciones de LLM para evaluar sistemas GenAI y agentes sin sesgo, ahorrando costos de anotación.
GLIDE: biblioteca Python que combina anotaciones humanas y predicciones de LLM para evaluar sistemas GenAI y agentes sin sesgo, ahorrando costos de anotación.
Descubre cómo manejar los pagos que nunca devuelven un 'sí' o 'no'. Conoce la máquina de estados efímera de x402-recovery para evitar pérdidas en redes inestables.

El colapso silencioso de la red eléctrica de EE.UU. por la IA y los incendios forestales, y cómo startups y reguladores luchan por salvarla.

Descubre cómo unificar herramientas de IA en las 7 etapas del desarrollo para optimizar calidad, reducir riesgos y acelerar la entrega. Guía esencial para líderes.
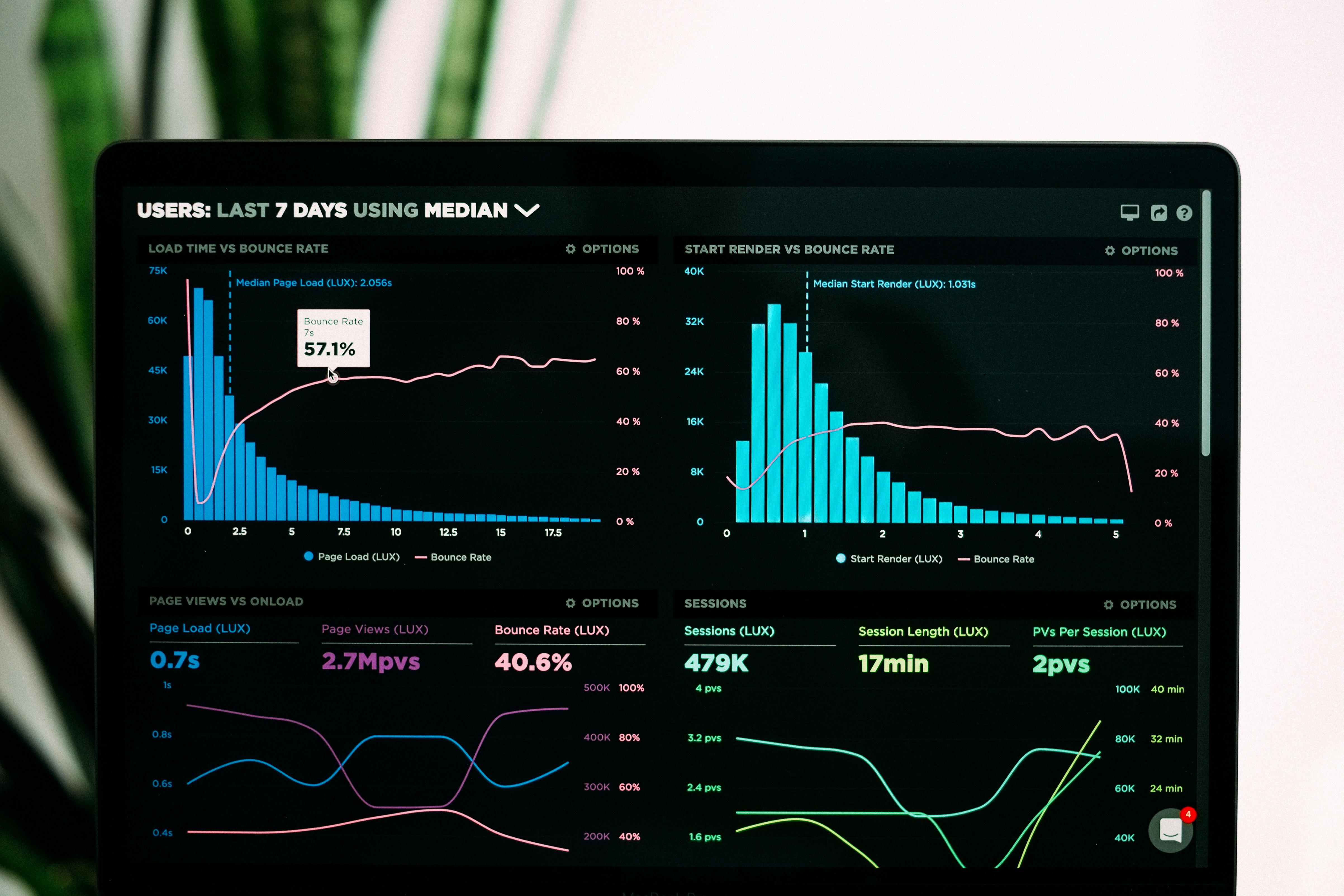
Descubre cómo FastNetMon LiveView lleva la defensa DDoS a un nuevo nivel: visibilidad en tiempo real, control de automatización y gobernanza operativa desde un panel web.

La IA solo conoce lo que tecleas. El verdadero foso está en los sensores físicos que capturan tu comportamiento real. Un experimento con Raspberry Pi y los desafíos de privacidad.

Descubre cinco estrategias para reducir costos de inferencia en IA. Optimiza prompts, elige modelos eficientes y reduce tokens de salida.

Descubre cómo entrenar tu propio LLM desde cero en 7 pasos con el método FareedKhan-dev. Deja de ser usuario y conviértete en creador de IA.

China utiliza IA para predecir disturbios políticos con un 95% de precisión. Descubre cómo el Proyecto Harmony monitorea 500 millones de usuarios y sus implicaciones éticas.

¿Y si Ómicron te diera las claves para construir tus propias defensas? Nature revela cómo su fusogenicidad atenuada facilita innovar en salud.

Descubre por qué la ejecución operativa supera a la estrategia de IA en retail. Aprende a operacionalizar inteligencia para resultados reales.

Arquitectura real de app de viajes compartidos en tiempo real con Node.js, Socket.io y Google Maps. Matching, concurrencia y lecciones de producción.

Descubre LiMuon, el optimizador ligero y rápido que reduce memoria y complejidad muestral para entrenar modelos grandes. ¡Mejor rendimiento!

Descubre cómo aumentar el número de neuronas sin añadir parámetros mejora la precisión al reducir la interferencia entre características. Optimiza tu IA.
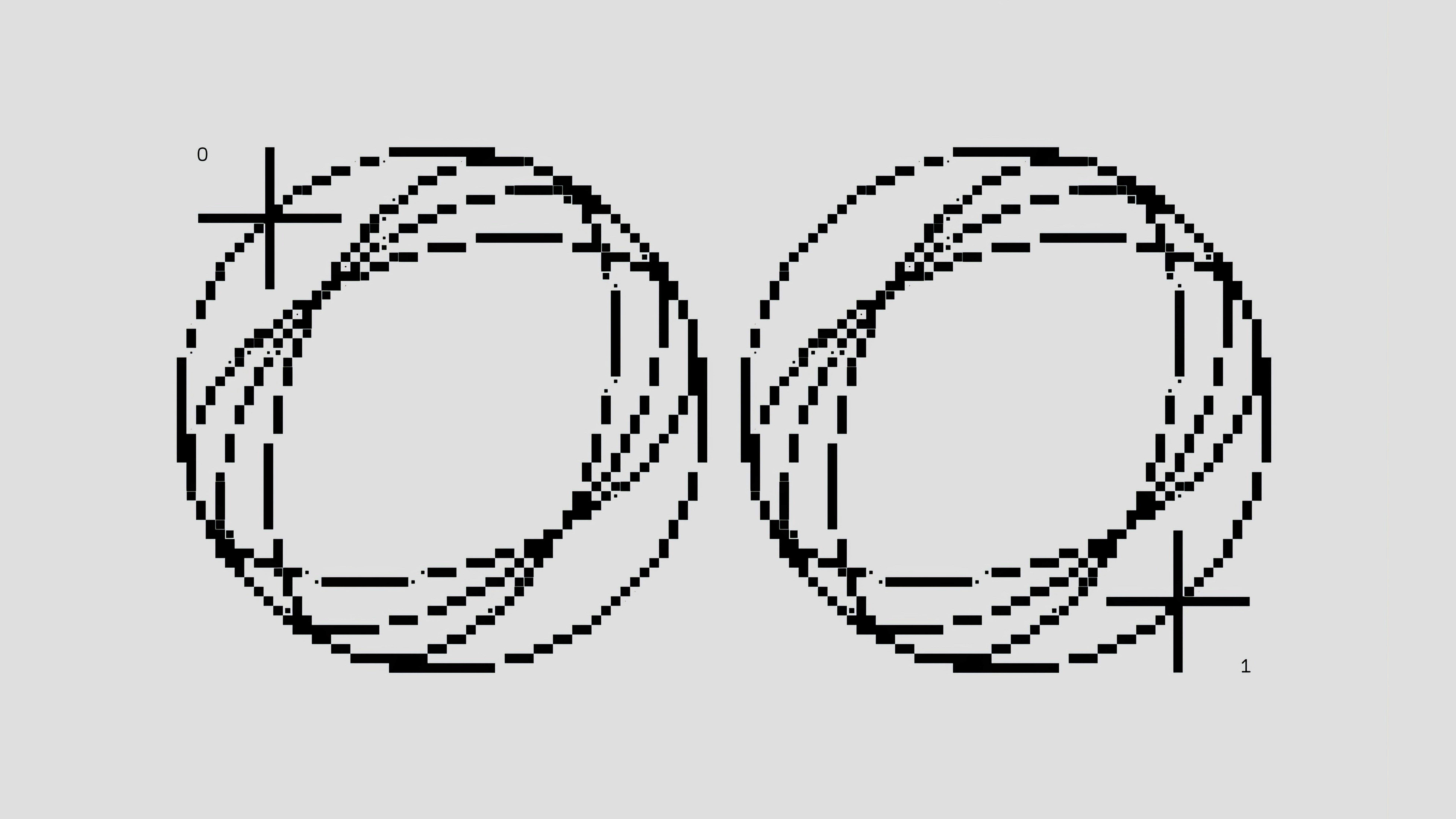
Descubre cómo los kernels invariantes de árbol garantizan inferencia determinista con resultados bit a bit idénticos, eliminando el desajuste entre entrenamiento e inferencia en LLMs.

Descubre cómo el espacio de vista permite aprender representaciones en grafos con características heterogéneas, superando modelos previos en un 8,93%.

Descubre cómo los denoisers suavemente restringidos mejoran el cumplimiento de EDPs sin rigidizar el modelo. Ideal para física computacional con IA.

Extrae algoritmos interpretables de un Transformer Discreto. Descubre cómo convertir pesos neuronales en código legible para una IA más explicable.

Descubre TRINE: motor FPGA adaptativo que acelera inferencia multimodal. Reduce latencia hasta 22.57x con solo 20-21W. Ideal para visión, lenguaje y grafos.

Descubre XOResNet, que usa meta-residuales XOR para superar limitaciones del aprendizaje residual en SNNs. Logra mejor precisión en CIFAR y miniImageNet.