Mejora del razonamiento multimodal mediante optimización de la peor dimensión
Descubre cómo la optimización de la peor dimensión supera las fallas ocultas en modelos de razonamiento multimodal, mejorando la consistencia lógica y visual.
Descubre cómo la optimización de la peor dimensión supera las fallas ocultas en modelos de razonamiento multimodal, mejorando la consistencia lógica y visual.

PAFO optimiza modelos de recompensa personalizados con equidad de Pareto, reduciendo el sesgo hacia grupos minoritarios.

GIFT usa LLMs para diseñar estados y recompensas en RL financiero, mejorando el rendimiento de carteras. Descubre cómo optimizar tus inversiones.

PAEC calibra la entropía solo en posiciones clave para evitar el colapso y mejorar el razonamiento de LLMs en problemas matemáticos. ¡Aumenta el rendimiento!

Descubre cómo los LLMs con razonamiento y verificación mejoran la predicción de trayectorias y destino de buques a 30 días, superando a métodos tradicionales.
Descubre cómo ISPO mejora el razonamiento en LLMs con señales intrínsecas, superando fallos de GRPO como colapso y certeza alucinada.

Descubre cómo T²-GRPO optimiza agentes cuidadores con recompensas del entorno, mejorando la atención en demencia con seguridad y eficiencia.

Mejora el alineamiento de LLMs con SAW, ponderación dinámica que optimiza el aprendizaje multiobjetivo sin apenas coste computacional.
Rosetta Memory adapta la memoria entre modelos de lenguaje como GPT y Claude. Optimiza la escritura y lectura para mejorar tareas complejas. ¡Descubre su

Investigación revela que agentes de IA alertan de fallos antes de cometerlos. Conoce el patrón de coherencia forzada y su detección con un 94% de precisión.

Descubre cómo el bucle hacker-fixer protege benchmarks de agentes contra reward hacking, eliminando el 100% de exploits en KernelBench. Una solución

Descubre cómo la incertidumbre en RLHF se unifica con un modelo distribucional, mitigando el reward hacking. Clave para optimización robusta.

El nuevo marco E2E unifica tokenizador, LLM y FM, logrando un WER del 0.78% y 1.56% en TTS, superando a los sistemas en cascada.

Aprende cómo los residuos de solucionadores y las recompensas aditivas saturadas (SAR) logran que un modelo de 8B compita con sistemas frontera en generación

Descubre cómo SAR mejora 2.3x la resolución de problemas geométricos de precisión crítica, superando el enmascaramiento de gradientes atípicos.

STRIDE mejora el RLVR con estimación discriminativa: asigna créditos precisos a patrones estratégicos. ¡Optimiza el razonamiento de tu IA!
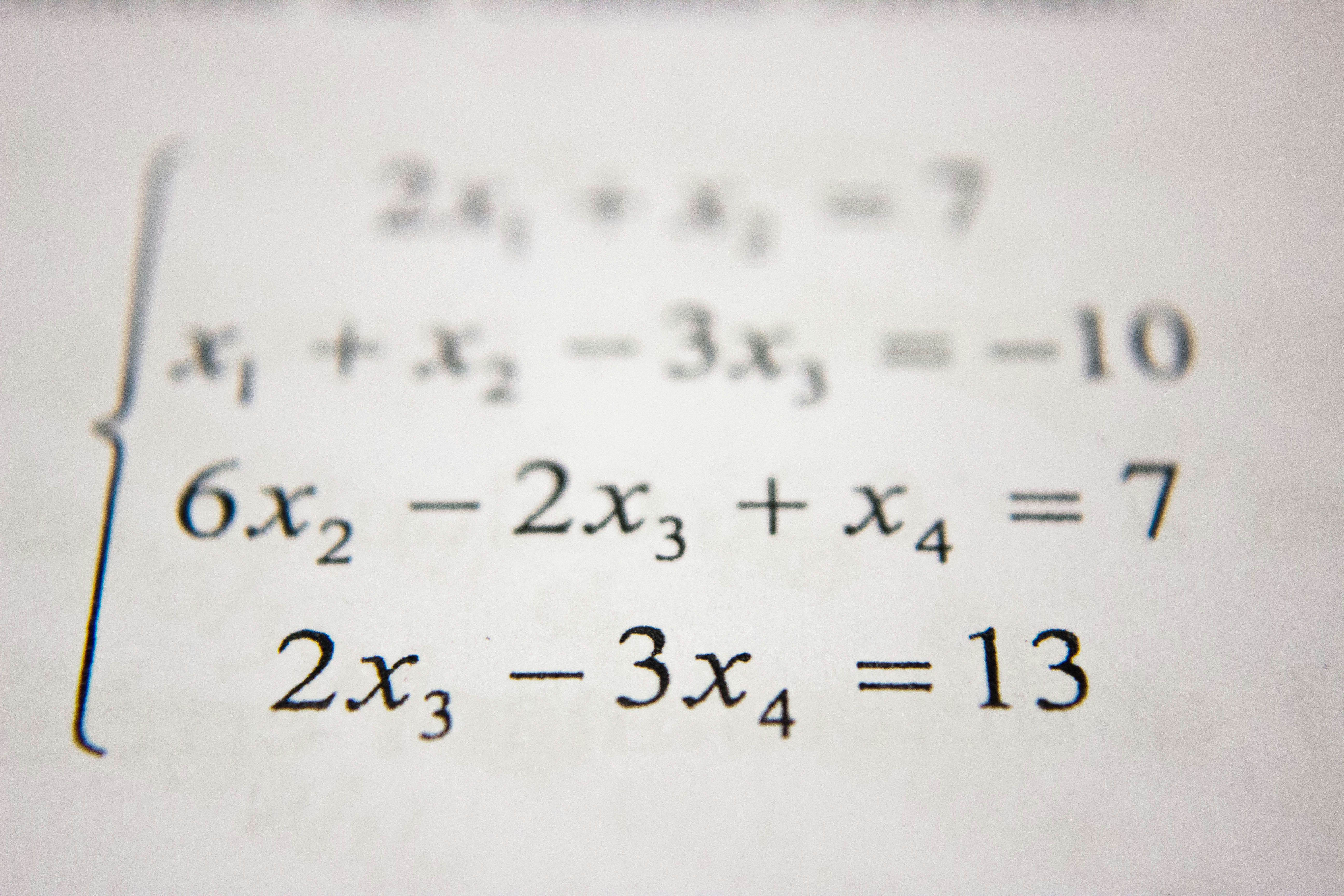
Descubre por qué los datos de alta recompensa dañan el razonamiento matemático en modelos pequeños y cómo la alineación de estilo mejora la destilación.

Explora la derivación de optimización de políticas en LLM: de la recompensa esperada a GRPO. Un marco unificado que diagnostica fallos y guía el diseño de
La codicia se aprende: los incentivos visibles pueden hacer que la IA sacrifique su tarea por recompensas. Un peligro para la seguridad y alineación.

Descubre cómo GERS mejora la generalización en RL usando solo métricas escalares, superando a métodos tradicionales en entornos no vistos.