Mapa jerárquico semántico-geométrico para navegación visual-lingüística
Descubre cómo un mapa jerárquico semántico-geométrico permite navegar en 3D con instrucciones de lenguaje, superando métodos supervisados.
Descubre cómo un mapa jerárquico semántico-geométrico permite navegar en 3D con instrucciones de lenguaje, superando métodos supervisados.

La diversidad en exploración supera a la frecuencia de uso de herramientas. Descubre el colapso y cómo la regularización de entropía mejora el razonamiento.

¿Sabías que los modelos multimodales aciertan la regla pero fallan en la respuesta? Descubre StemBind, un benchmark que localiza el verdadero cuello de botella en el razonamiento visual abstracto.

Descubre cómo el razonamiento continuo mejora las políticas VLA en robótica, con un 40% más de éxito en tareas. Un nuevo lenguaje interno compartido y verificable.

Los LLMs fallan al predecir efectos de perturbaciones celulares. CORE organiza evidencia contrastiva para mejorar la precisión hasta un 28.6%. Descubre cómo.

ThinkSwitch combina destilación de contexto con LoRA e interpolación de pesos para mejorar modelos de lenguaje en razonamiento, reduciendo costos y latencia sin sacrificar precisión.

Soft-NBCE optimiza la inferencia de LLMs en contextos largos: fusión de fragmentos con pesos de entropía y destilación de consistencia para mayor precisión en razonamiento multi-salto.

Descubre cómo APEIRIA combina la transparencia del razonamiento simbólico con la flexibilidad de los LLMs 3D para mejorar el razonamiento espacial. ¡Lee más!
Descubre cómo RefMem-Bench y REMIND evalúan y mejoran la memoria reflexiva en diálogos largos, superando la simple recuperación de hechos.

POPO elimina muestras ineficaces acelerando el fine-tuning de LLM para razonamiento matemático, planificación y geometría visual con menos rollouts.
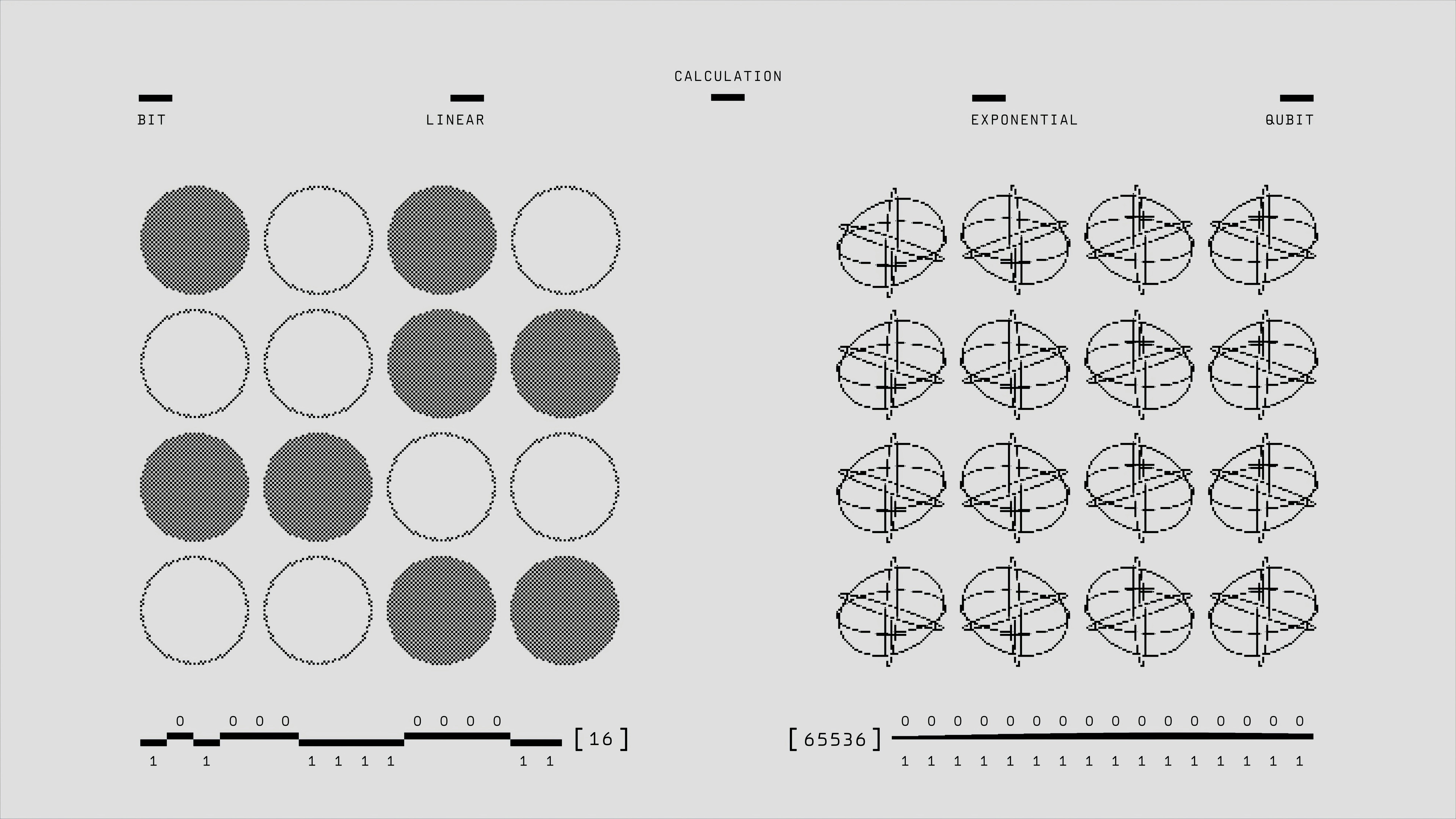
Los tokens latentes en modelos multimodales no almacenan memoria visual. Descubre cómo los marcadores de límite y formato generan las ganancias.

Descubre cómo el uso guiado de LLMs en estadística mejora el aprendizaje autónomo y la calibración del conocimiento, superando el simple acceso a la IA.

TimeSage-MT evalúa la capacidad de agentes IA en análisis de series temporales a lo largo de múltiples turnos. Descubre sus debilidades en memoria y toma de decisiones.

Marco RAG con agentes y grafos que analiza literatura técnica en 13 pasos autónomos, verifica citas y busca evidencia externa. Ideal para investigadores.

EvoPool revoluciona la anotación con un marco evolutivo multiagente que supera a los LLM en tareas especializadas, reduciendo costos hasta 31,000x. Descubre cómo.
Descubre cómo LLMs listos para usar mejoran el razonamiento matemático sin entrenamiento, superando la votación mayoritaria hasta 28%.

MOSS-Audio unifica voz, sonido y música con DeepStack y time markers. Descubre su arquitectura y rendimiento en ASR y razonamiento con audio.

Mejora el razonamiento de LLMs con TOPD: destilación on-policy con guía futura aumenta precisión del 47.8% al 52.2%.
PlanarBench evalúa la capacidad de los LLMs para dibujar grafos planos en ASCII. Descubre cómo el número de aristas predice el rendimiento de 91 modelos.

Descubre DarkVesselNet: fusión de SAR, óptico y AIS con IA para detectar barcos oscuros. Razonamiento de trayectorias y detección de anomalías.