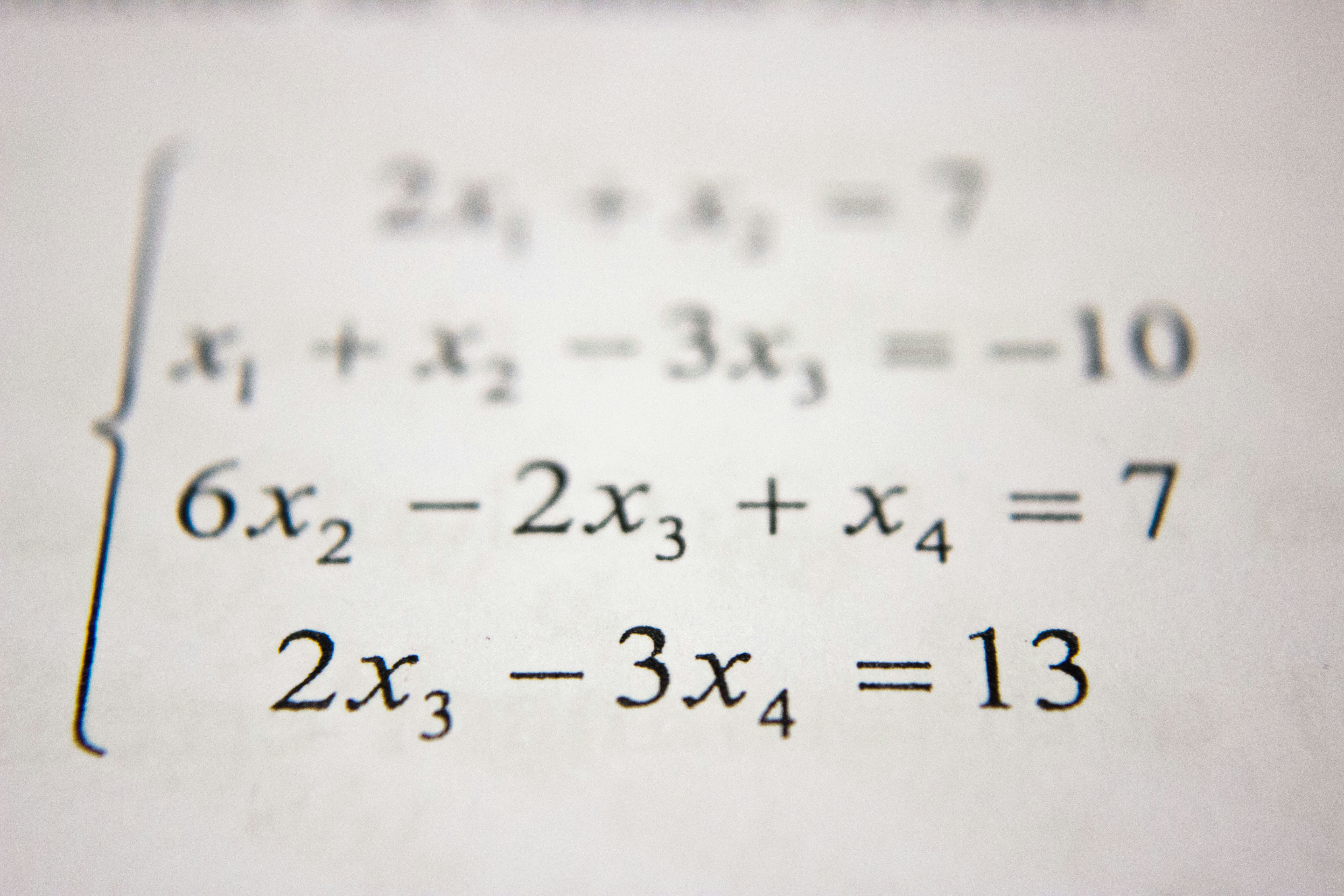
PyraMathBench: Evaluando y mejorando capacidad matemática en LLMs
Descubre PyraMathBench: evalúa y mejora la capacidad matemática de los LLMs con 32,505 preguntas y técnicas como SOLVE e IRPO.
Descubre PyraMathBench: evalúa y mejora la capacidad matemática de los LLMs con 32,505 preguntas y técnicas como SOLVE e IRPO.

Un nuevo benchmark de acertijos lógicos revela la estructura oculta del razonamiento en modelos de IA, más allá de la precisión.
Hedge-Bench: solo el 16% de éxito en tareas financieras complejas para agentes de IA. ¿Qué tan lejos estamos del analista humano?

La entropía falla en RL visual: VEPO selecciona tokens visual-informativos y supera en hasta 3.15 puntos. Descubre cómo.

Los Tokens de Percepción Imaginativa (IPT) mejoran el razonamiento espacial en modelos multimodales sin generar imágenes. Aumento del 3.4% en precisión en conteo multivista.

Descubre cómo TRAP usa parches adversariales para secuestrar razonamiento CoT en robots VLA y provocar comportamientos peligrosos. Vulnerabilidad crítica en IA.

Descubre por qué los SLMs miden artefactos de prompt, no rasgos psicológicos. Un estudio revela cómo los sesgos de cumplimiento dominan las evaluaciones.

Descubre cómo HARC corrige la ruptura de enrutamiento en MoE fusionados sin entrenamiento, usando curvatura hessiana. Ideal para razonamiento y código.

CR-Seg: segmentación razonada que combina atención y cadena de pensamiento para objetos complejos.

Descubre cómo los LLMs fallan ante cambios numéricos mínimos en problemas aritméticos. Nuevos ataques automáticos revelan fragilidades en razonamiento.

Descubre cómo TTRL-CoCoV mejora Pass@k y Pass@1 en razonamiento complejo sin etiquetas, usando verificación condicionada por confianza.

Descubre TAO-RL, el nuevo marco que combina filtrado de trayectorias con exploración guiada por entropía para optimizar el razonamiento de LLMs con herramientas. Mejora la eficiencia y precisión.

¿Los modelos de razonamiento grandes expresan su confianza de forma fiel? Cuantificamos la calibración entre incertidumbre interna y verbalizada, revelando desa

Descubre cómo los embeddings de grafos aproximan la inferencia probabilística en SEL de forma eficiente, con garantías de sonido y velocidad.

Descubre DTKG, un marco que combina verificación de hechos y cadenas en grafos de conocimiento para responder preguntas multi-salto con alta precisión.

Descubre MemVerse, el marco de memoria multimodal que permite a los agentes de IA recordar, adaptarse y razonar sin olvido catastrófico. ¡Mejora el aprendizaje continuo!

MIND: nuevo marco de razonamiento activo para modelos multimodales. Emula el proceso humano entender-repensar-corregir. Logra SOTA.

Descubre cómo X-RAY mapea la capacidad de razonamiento de los LLMs usando sondas formales y calibradas, revelando asimetrías y fallos interpretables.

Descubre cómo el benchmark REL evalúa el razonamiento relacional en LLMs, revelando sus limitaciones en tareas de alta aridad en ciencias.

Descubre cómo EvoOR-Agent utiliza la coevolución de arquitecturas de agentes y razonamiento interpretable para optimizar procesos complejos con LLMs. Mejora el rendimiento y la interpretabilidad.