
Más charla, menos significado: Automejora en SLMs
¿Los modelos de lenguaje pequeños realmente aprenden de sus errores? Un estudio revela que solo mejoran un 4.4% y que más razonamiento puede empeorarlos.
¿Los modelos de lenguaje pequeños realmente aprenden de sus errores? Un estudio revela que solo mejoran un 4.4% y que más razonamiento puede empeorarlos.

Descubre cómo los Certificados de Ignorancia Estructurada (SIC) entrenan a los modelos de IA para reconocer sus límites, reduciendo alucinaciones y mejorando la precisión en consultas complejas.

Descubre cómo Anything2Skill transforma conocimiento externo en habilidades ejecutables para agentes, mejorando RAG con tasas de éxito del 98%.

SkeMex permite a agentes médicos acumular habilidades reutilizables de la experiencia, mejorando el razonamiento clínico sin actualizar modelos.
Descubre cómo CEF-Log detecta logs maliciosos con un 99% de precisión usando solo 4 ejemplos y explicaciones forenses claras. Ideal para ciberseguridad.

¿Sabías que los agentes de datos con LLM tienen vulnerabilidades críticas? Un nuevo estudio revela 14 técnicas de ataque. Infórmate.

Los formatos estructurados como JSON pueden degradar el rendimiento de la IA si el modelo opera al límite. Estrategia: pensar antes de formatear.
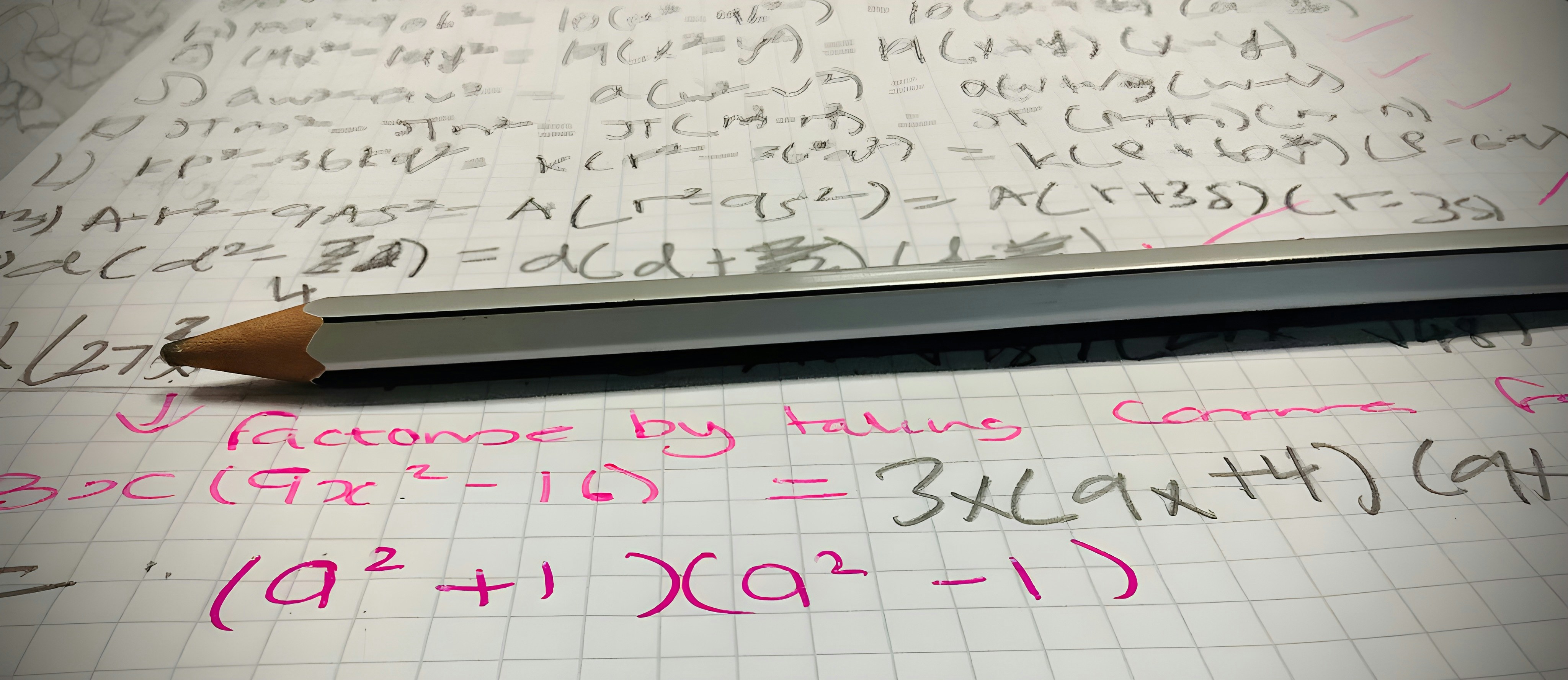
TheoremBench evalúa LLMs en Lean4 con teoremas clásicos y subteoremas. Mide cobertura y eficiencia para revelar debilidades en razonamiento formal.
Un estudio de ablación revela que la calidad de la evidencia, no solo el razonamiento, limita el rendimiento de los científicos de IA en valoración farmacéutica.

El razonamiento óptico usa imágenes como medio de razonamiento, superando al texto en eficiencia y reduciendo tokens un 28% en tareas de IA.
Los grafos de conocimiento y LLMs con RL logran predecir perturbaciones transcriptómicas con alta precisión, superando a métodos complejos. Descubre cómo.

Descubre cómo la selección intrínseca y el remuestreo de partículas mejoran el escalado en tiempo de inferencia sin necesidad de verificación externa, logrando

SpatialWorld es un benchmark unificado que evalúa el razonamiento espacial interactivo de modelos multimodales. GPT-5 solo logra un 17% de éxito. Descubre los desafíos.

BRAIN utiliza inferencia activa y modelos generativos para lograr una IA causal, adaptativa e interpretable en redes 6G. Supera al DRL en robustez y asignación de recursos.

El post-entrenamiento actual de LLMs es en realidad un ajuste fino masivo. ¿Estamos retrocediendo a métodos antiguos? Descúbrelo.

CAPruner optimiza la poda de grafos de escena para potenciar el razonamiento espacial 3D de LLMs, reduciendo costos y mejorando precisión.

LWS permite a los LLM generar texto visible en tiempo real mientras hablan, mejorando la interacción full-duplex.

Evaluamos prompts avanzados en Gemini Flash para QA biomédica. Un prompt complejo logró 0.720, superando al básico (0.565). El diseño de prompts es clave.

Descubre cómo el Tarot y el I-Ching alteran el comportamiento de los LLM en juegos multiagente, generando ganadores distintos y revelando el poder del proceso reflexivo.

Mejora la generación de ensamblajes LEGO con IA usando un método eficiente que evita errores de alineación y semántica. Descubre PVPO.