
LatentSkill: Habilidades latentes en pesos para agentes LLM
LatentSkill convierte habilidades textuales en adaptadores LoRA modulares, reduciendo tokens de prefijo hasta un 72% y mejorando rendimiento en agentes LLM. Descubre cómo.
LatentSkill convierte habilidades textuales en adaptadores LoRA modulares, reduciendo tokens de prefijo hasta un 72% y mejorando rendimiento en agentes LLM. Descubre cómo.
Descubre cómo el fine-tuning de LLMs como Roberta-base mejora la extracción precisa de respuestas en sistemas QA. Resultados: ROUGE-L 86.84% y BERTScore 95.38%.

Descubre cómo los nuevos Gemma 4 QAT de Google DeepMind reducen la memoria hasta 1 GB en móviles sin perder calidad. Comparativa completa.
MedReCo: un framework que permite a la IA razonar comparativamente entre imágenes radiológicas, mejorando diagnósticos y seguimientos. Resultados clínicos superiores.

Descubre cómo compartir proyecciones QKV en Transformers reduce el caché KV hasta 96.9% sin perder calidad, ideal para dispositivos edge.

Descubre cómo el modelo VLM consciente de creencias combina memoria y RL para un razonamiento similar al humano. Mejora en QA visual con HD-EPIC. ¡Lee más!

Descubre cómo un modelo VLM consciente de creencias integra memoria y aprendizaje por refuerzo para un razonamiento similar al humano, mejorando tareas de VQA.

Descubre YAQA: algoritmo de redondeo adaptativo que reduce el error de cuantización un 30% frente a GPTQ. Cotas de error garantizadas sin coste de inferencia.
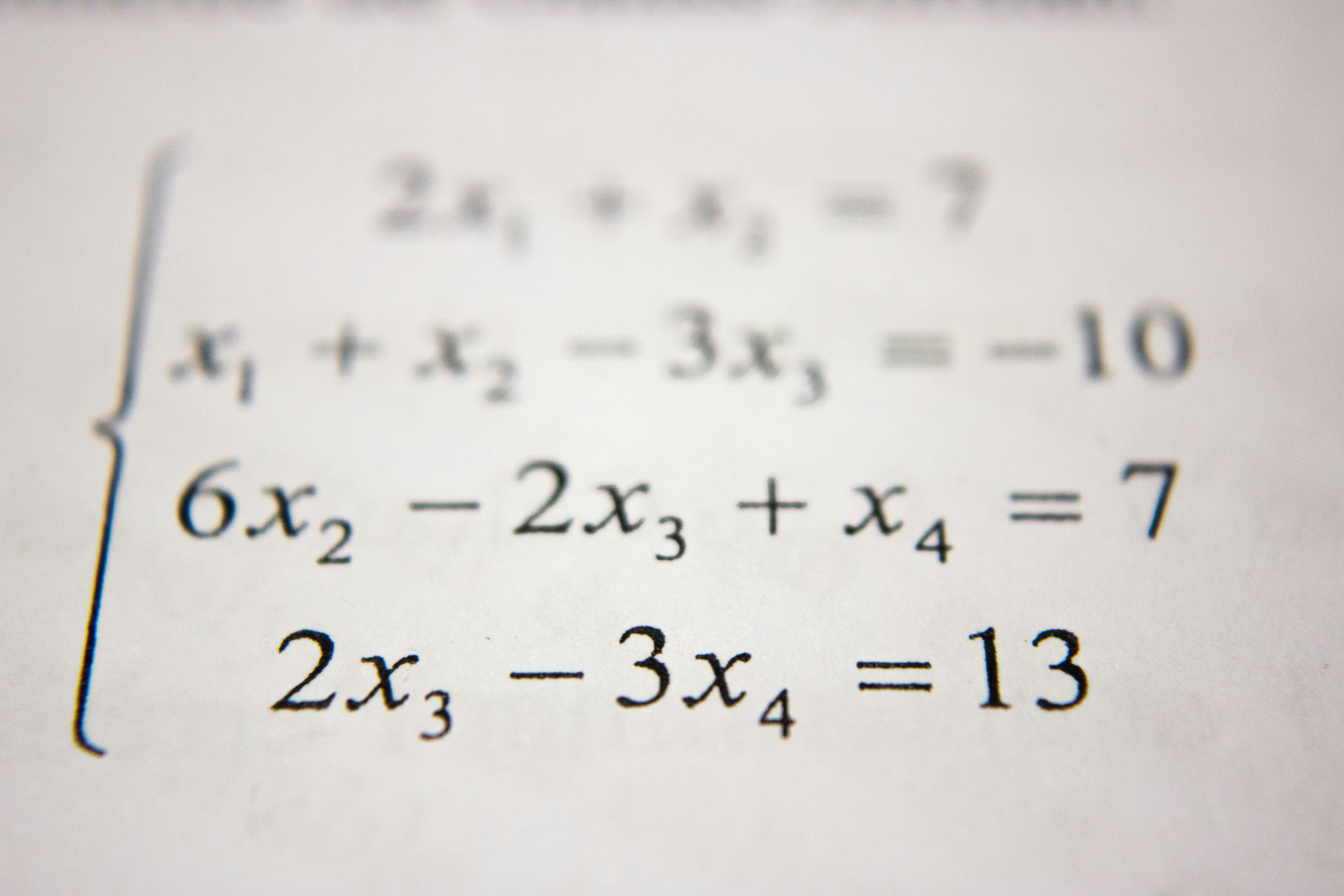
Descubre YAQA, el algoritmo de redondeo adaptativo que reduce el error de cuantización un 30% sin sobrecarga. Preserva la distribución del modelo original.

Analizamos el impacto de la relación señal-distorsión invariante a escala en la separación de voz con referencias ruidosas. Descubre cómo mejorar la calidad con NISQA.

Descubre cómo el ruido en las referencias afecta al SI-SDR en separación de voz y un método para mejorar la calidad del audio separado.

R3G: marco de razonamiento-recuperación-reordenamiento para VQA. Mejora la precisión al integrar un plan de razonamiento y recuperación de imágenes en dos etapas.

Descubre Hyper-ICL, un método ligero que elimina la necesidad de demostraciones en ICL multimodal, calibrando la atención con destilación hiperbólica para mejorar precisión y estabilidad.

Descubre MorphoQuant, un marco de cuantización que mantiene la precisión en modelos omni-modales con solo 4 bits, superando a modelos de 16 bits en ScienceQA.

Descubre cómo VISTA combina visión y validación física para adaptar datos UMI y entrenar modelos VLA, mejorando el rendimiento en manipulación robótica real.

Aprende a destilar reglas de programación lógica desde LLMs para VQA interpretable, con solo pocos ejemplos. Alternativa eficiente al aprendizaje de reglas tradicional.
Descubre TSQAgent, un marco de agentes de IA que evalúa la calidad de series temporales mediante razonamiento y herramientas analíticas. Mejora la selección de datos y el rendimiento.

Descubre PGPO, un nuevo método de optimización guiado por la física que estabiliza el post-entrenamiento de LLMs, mejorando hasta 4.5 puntos en Science-QA.

¿Las sondas lineales detectan razonamiento o formato? Un estudio revela que la precisión en LLMs se explica por confusores de formato, no por modos de razonamie

DecomposeR optimiza la investigación profunda con RL centrado en planificador y recompensa estructural. Mejora hasta 8 puntos en benchmarks.