
SDM-Q: Aprendizaje por refuerzo con coste para clasificación multi-ómica
Descubre cómo SDM-Q usa aprendizaje por refuerzo para clasificar enfermedades con menos datos ómicos, reduciendo costes y manteniendo precisión.
Descubre cómo SDM-Q usa aprendizaje por refuerzo para clasificar enfermedades con menos datos ómicos, reduciendo costes y manteniendo precisión.
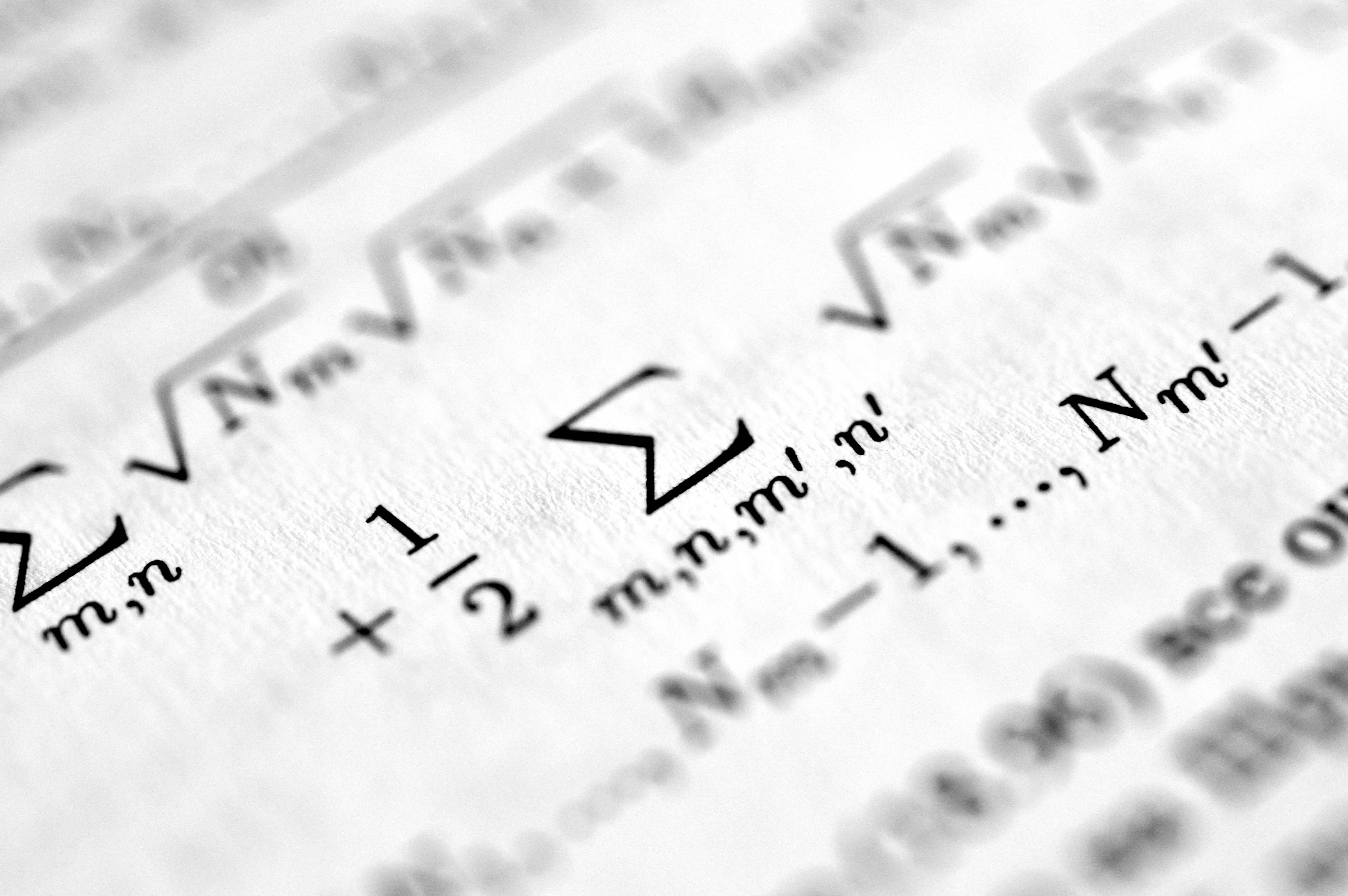
Descubre cómo el marco de Lyapunov permite analizar la convergencia en tiempo finito de algoritmos estocásticos como Q-learning y SGD. Ideal para IA y RL.
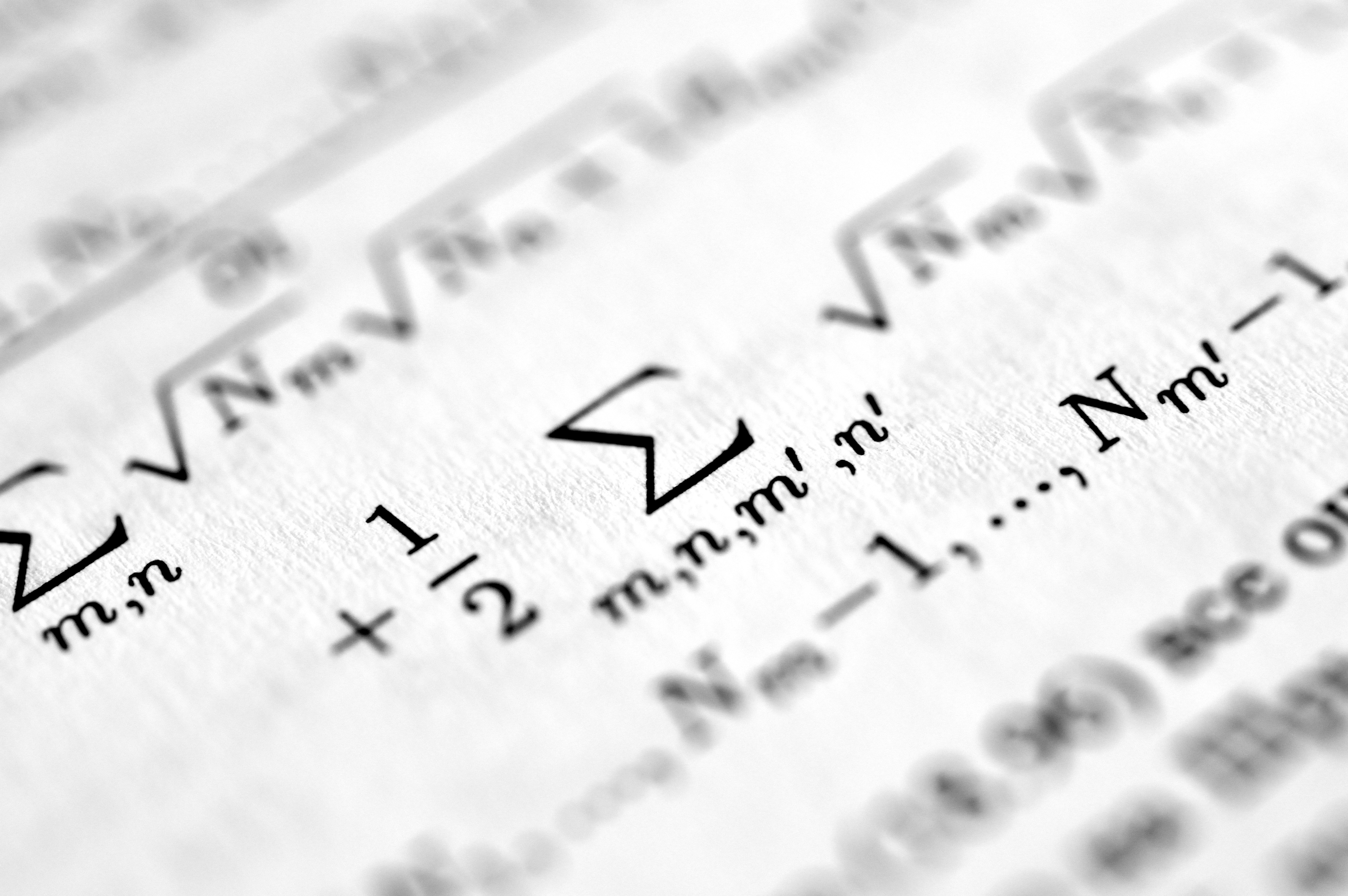
Descubre cómo las funciones de Lyapunov permiten analizar la convergencia finita de algoritmos estocásticos en aprendizaje automático y refuerzo.

Descubre cómo aplicar el ajuste de momentos en Q-learning para mejorar la convergencia y estabilidad del aprendizaje por refuerzo.