
MatchFixAgent: Validación autónoma de traducción de código
MatchFixAgent usa LLM para validar y reparar traducciones de código entre lenguajes, logrando 50.6% de reparación vs 18.5% de métodos anteriores.
MatchFixAgent usa LLM para validar y reparar traducciones de código entre lenguajes, logrando 50.6% de reparación vs 18.5% de métodos anteriores.

Descubre un método asintóticamente óptimo para pruebas secuenciales en cadenas de Markov. Mejora límites inferiores y aplicaciones en MCMC y MDPs.

Optimiza LLMs con GradMem: escribe contexto en memoria mediante descenso de gradiente en tiempo de prueba, reduciendo la necesidad de grandes cachés.
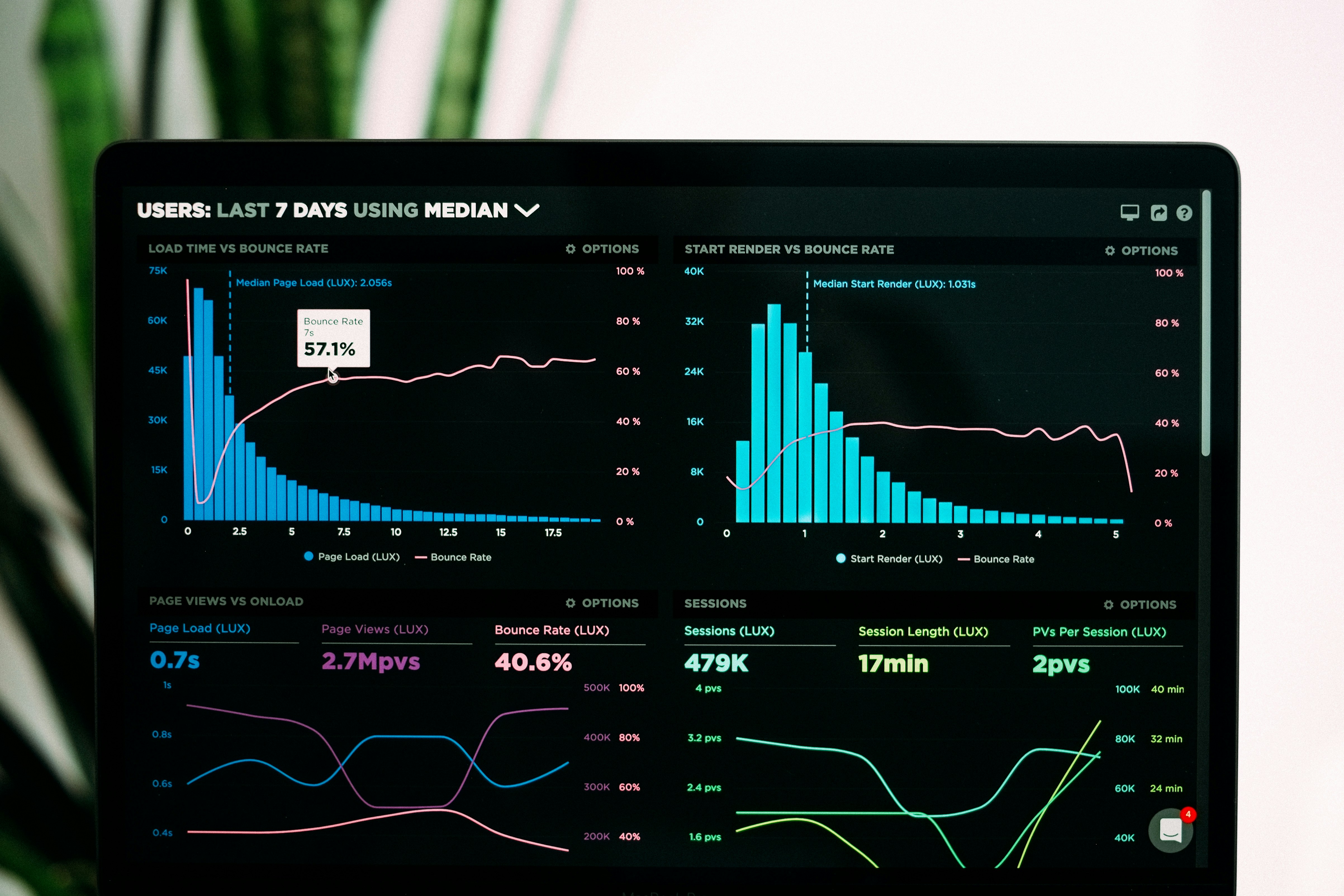
Descubre cómo un enfoque de prueba de distribución permite recuperar la partición oculta de distribuciones con cotas de complejidad de muestreo ajustadas.

Descubre cómo evaluar proveedores para reemplazar tu base de datos Access. Mejora seguridad, acceso multiusuario e integración. Q2BSTUDIO te guía.

Descubre cómo EffortX, impulsado por IA y blockchain, mide la calidad de tus contribuciones en GitHub y genera pruebas verificables de tu impacto como desarrollador.

Descubre cómo probar y evaluar el reemplazo de tu base de datos Access por una app moderna con demos y pilotos personalizados antes de invertir.

Descubre DSR-Bench, el benchmark que revela las limitaciones en razonamiento estructural de los LLM. ¡El mejor modelo solo obtiene 0.46/1!

Descubre cómo garantizar la fiabilidad al migrar tu base de datos Access a una aplicación moderna. Alta disponibilidad, monitoreo y pruebas rigurosas para un servicio ininterrumpido.

Descubre cuánto tiempo toma migrar de Access a una app moderna. Factores clave, plazos y cómo Q2BSTUDIO acelera el proceso. ¡Planifica tu proyecto!
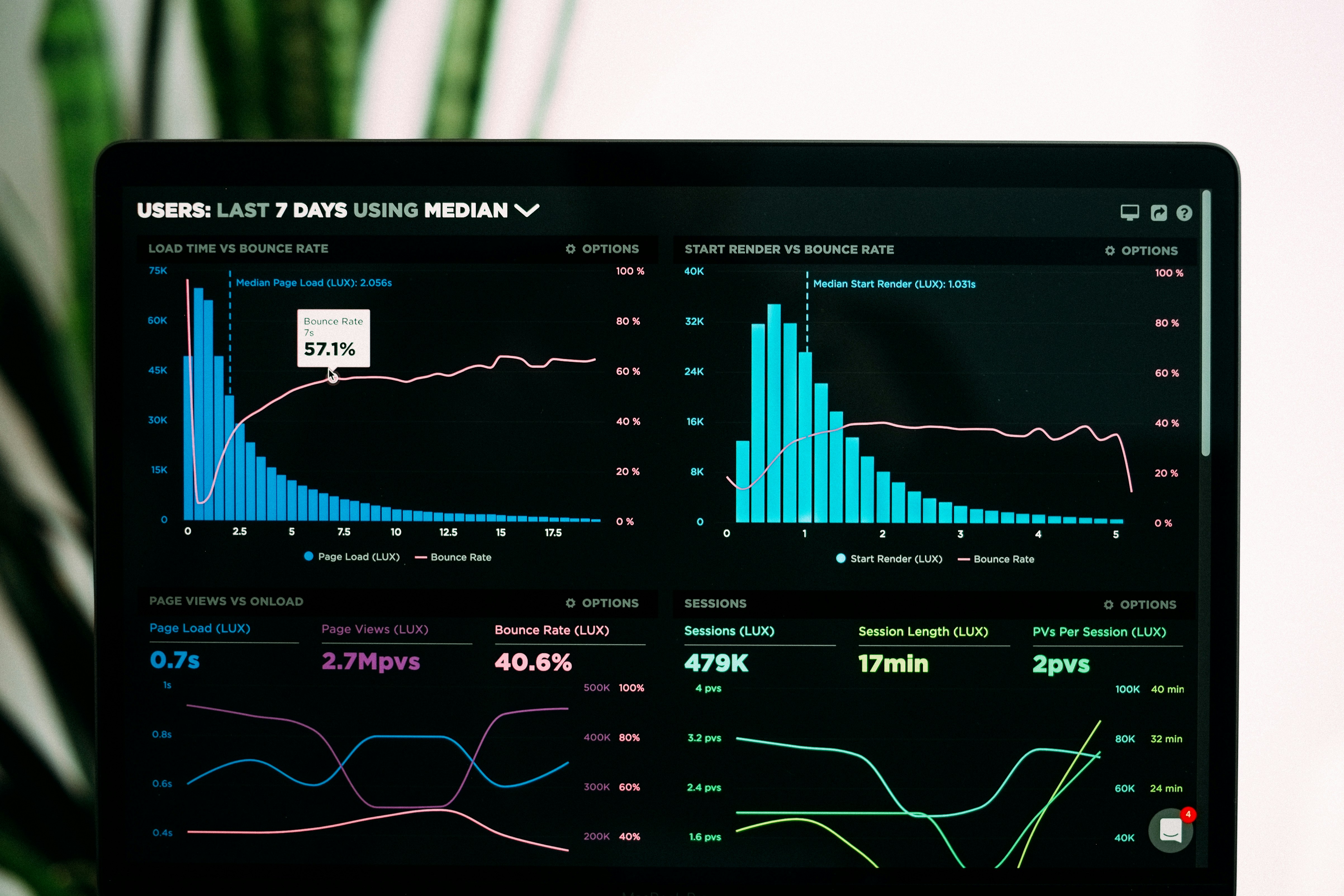
Descubre cómo generar datos sustitutos para pruebas estadísticas no paramétricas en grafos dirigidos, superando limitaciones de métodos existentes.

Descubre cómo aprovechar las similitudes entre sistemas en pruebas A/B usando estimación off-policy para obtener resultados más precisos y robustos.

Descubre pruebas privadas casi óptimas para hipótesis simples y MLR con privacidad diferencial gaussiana. Resultados comparables a pruebas no privadas.

Anthropic amplía el acceso a Mythos a 150 nuevas organizaciones. Miles de vulnerabilidades ya fueron detectadas. Mejora la ciberseguridad.

Por primera vez, se demuestran cotas de generalización no triviales para redes profundas sin modificaciones, incluso con 600M parámetros. Análisis basado en la geometría de los datos.

Nuevas cotas de generalización para algoritmos Monte Carlo en el régimen de interpolación, con resultados en MNIST, CIFAR-10 y SVHN.

Descubre cómo los algoritmos adaptativos mejoran la exploración en bandidos con estado latente, reduciendo el arrepentimiento dinámico mediante resúmenes y pruebas de actualización.
Descubre cómo Tempora evalúa la adaptación en tiempo de prueba bajo presión temporal. Conoce métricas para elegir el mejor método según latencia y precisión.

Instala un arnés a tu IA de código con AGENTS.md, commits previos y pruebas. Convierte a tu asistente en un colaborador seguro y revisable.

Aprende a construir una CLI de quiz en TypeScript usando enum, tipos tupla y mocks de Jest. Incluye async/await y buenas prácticas de testing.