
Cada Token Cuesta: Guía para Gestión de Desperdicio de Tokens
Descubre cómo reducir el desperdicio de tokens en sistemas de IA en producción. Aprende a optimizar costos, prompts y arquitecturas para ahorrar dinero.
Descubre cómo reducir el desperdicio de tokens en sistemas de IA en producción. Aprende a optimizar costos, prompts y arquitecturas para ahorrar dinero.

Predice la calidad de tus prompts con EMoE: incertidumbre sin entrenamiento en difusión texto-imagen.
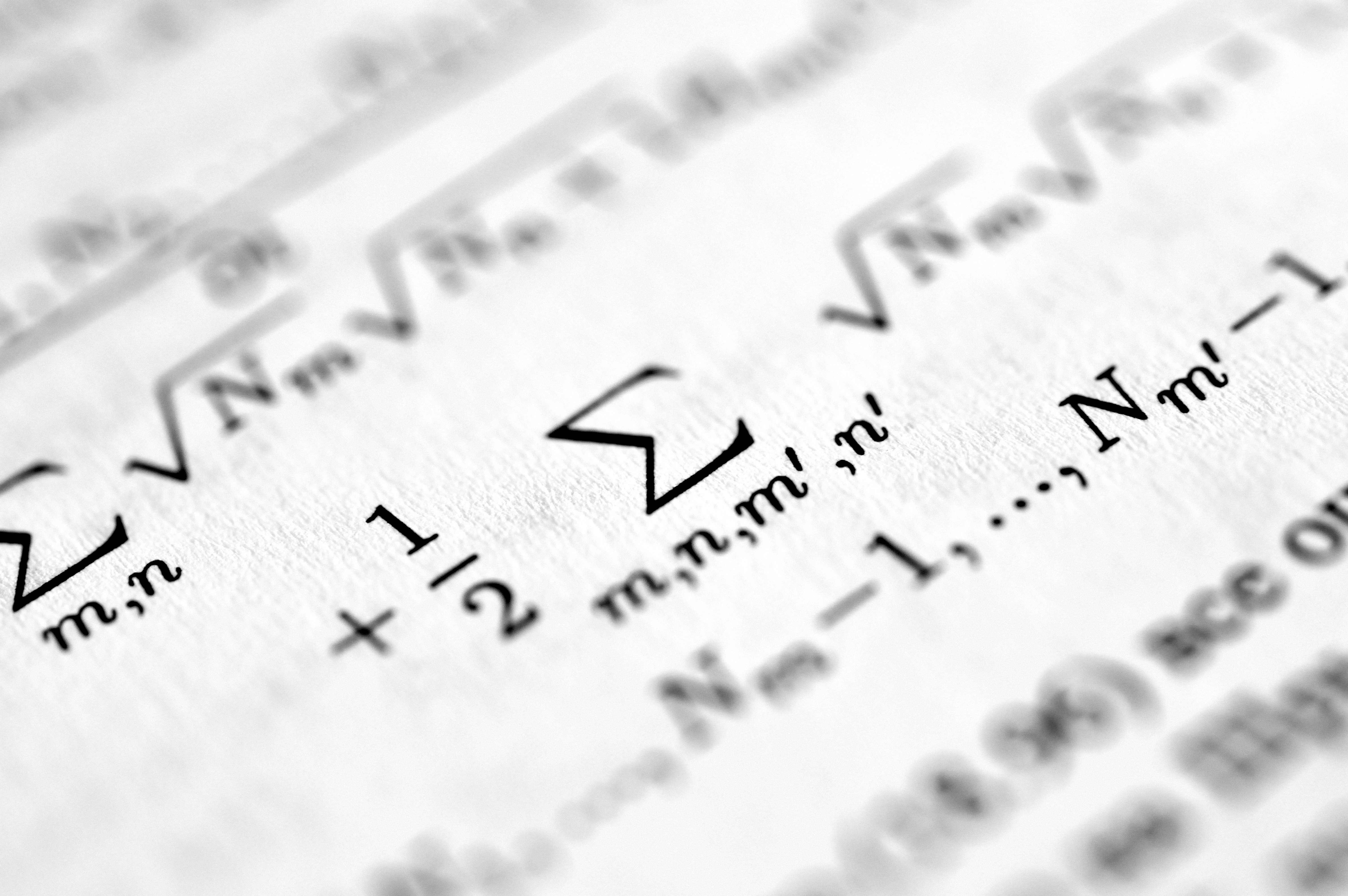
KACE: un novedoso método que separa almacenamiento y uso del conocimiento, logrando un 62.2% de precisión en AIME 2025. Ideal para mejorar razonamiento matemático en IA.

Descubre cómo un simple prompting puede revelar las trazas de razonamiento ocultas en los LLMs, desafiando la seguridad de los modelos. Aprende sobre REP.

Descubre cómo la selección de prompts con Maximum Independent Set reduce hasta un 48% el costo de evaluar LLMs en benchmarks, manteniendo rankings consistentes.
HOPM: mutación de prompts con doble retroalimentación mejora documentos de evidencia +11% en tasa de victorias. Estudio de caso.

Descubre Adaptive Auto-Harness: mejora continua de agentes LLM en flujos abiertos, superando a métodos en predicción y seguridad.

Mejora la reescritura de textos cortos con Phi Silica. Aprende a aplicar fine-tuning para mayor fidelidad semántica y menos alucinaciones. ¡Resultados sorprendentes!

Descubre un framework A* multiagente que ofusca prompts de LLM, induciendo alucinaciones de sentido común con alta eficacia y pocos intentos.

Descubre por qué el agente de Anthropic fue secuestrado el 31.5% del tiempo y cómo se comparan OpenAI, Google y Meta en seguridad de prompts.

Descubre 10 trucos imprescindibles para Google Gemini: desde personalizar instrucciones hasta automatizar tareas. Mejora tu productividad con estos consejos.

Descubre cómo reducir tu factura de Copilot hasta un 60% con 5 trucos de prompt. Ahorra tokens y mejora tus resultados. ¡Empieza hoy!

Automatiza selección de películas y feedback a cineastas en festivales independientes con IA. Ahorra tiempo y optimiza tu proceso. Guía rápida.

Descubre cinco estrategias para reducir costos de inferencia en IA. Optimiza prompts, elige modelos eficientes y reduce tokens de salida.

¿Los LLMs clínicos son inconsistentes ante cambios en las preguntas? Un estudio mide su estabilidad semántica y propone métricas para evaluarla.

Descubre cómo ataques adversariales mediante algoritmos genéticos pueden engañar a agentes de IA en ingeniería inversa, ocultando código malicioso en binarios.
Descubre cómo detectar y ofuscar ataques de inyección de prompts en sistemas de ingeniería inversa con IA. Protege tus agentes de software con tácticas defensivas avanzadas.

Descubre TunerDiT: método sin entrenamiento para videos multi-evento con transformadores de difusión. Mejora consistencia y separación de eventos.

Descubre cómo el chat en vivo con IA se integra con las principales herramientas de inteligencia artificial para mejorar tiempos de respuesta y consistencia.

¿Está realmente aislada la caché de prompts en APIs Gateway? CacheProbe audita OpenRouter y revela riesgos de seguridad por caché compartido.