
Gobernanza de la interacción humano-LLM: seguridad, civilidad y bloqueo afectivo
Descubre cómo la gobernanza de la interacción con LLM afecta seguridad, civilidad y el bloqueo afectivo. Estudio de control de estilo y autonomía del usuario.
Descubre cómo la gobernanza de la interacción con LLM afecta seguridad, civilidad y el bloqueo afectivo. Estudio de control de estilo y autonomía del usuario.
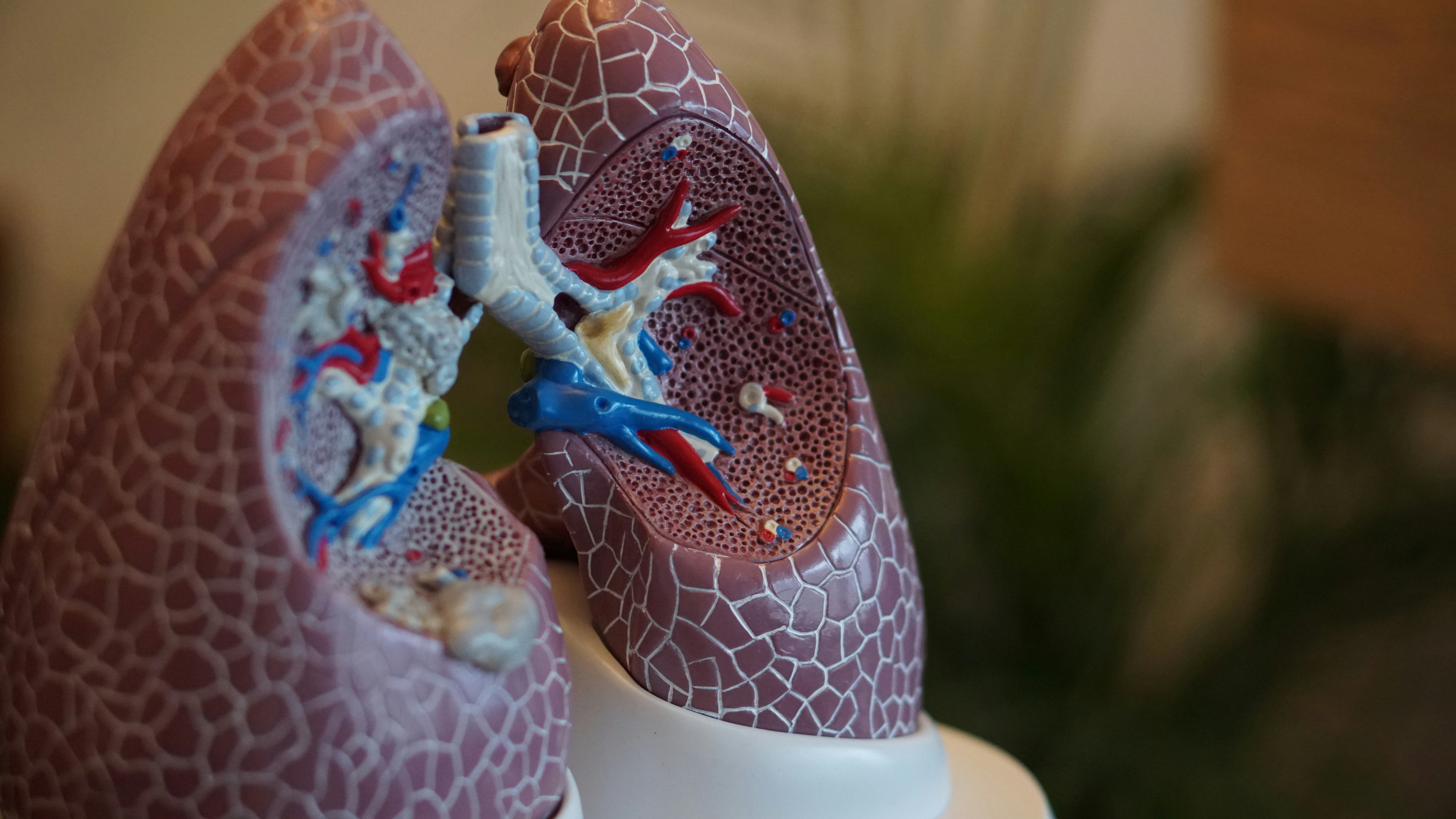
Descubre AeroSpectra Sentinel, un prototipo que combina STFT, ML y LLM para evaluar riesgo de asma a partir de sonidos respiratorios y señales clínicas. Auditoría segura.

Descubre cómo los arrays de floats permiten la inyección indirecta de prompts, evadiendo detectores de texto como Prompt Guard 2. Un estudio con 14,400 pruebas.

Descubre FaithRewriter, innovador marco que alinea reescritura de prompts con anclas visuales para generar imágenes fieles a la intención del usuario.

Los formatos estructurados como JSON pueden degradar el rendimiento de la IA si el modelo opera al límite. Estrategia: pensar antes de formatear.

PRISM decodifica las instrucciones activas en modelos de lenguaje. Un nuevo enfoque para monitorizar agentes de IA ante inyecciones y objetivos ocultos.

Evaluamos prompts avanzados en Gemini Flash para QA biomédica. Un prompt complejo logró 0.720, superando al básico (0.565). El diseño de prompts es clave.

No empieces con LangChain sin entender los fundamentos. Aprende funciones Python, APIs, JSON, tool calling y LLM para construir agentes de IA sólidos. Guía esencial para principiantes.

Descubre cómo un socio de automatización low-code se integra con herramientas de IA para acelerar la innovación, garantizando gobernanza, escalabilidad y seguridad.
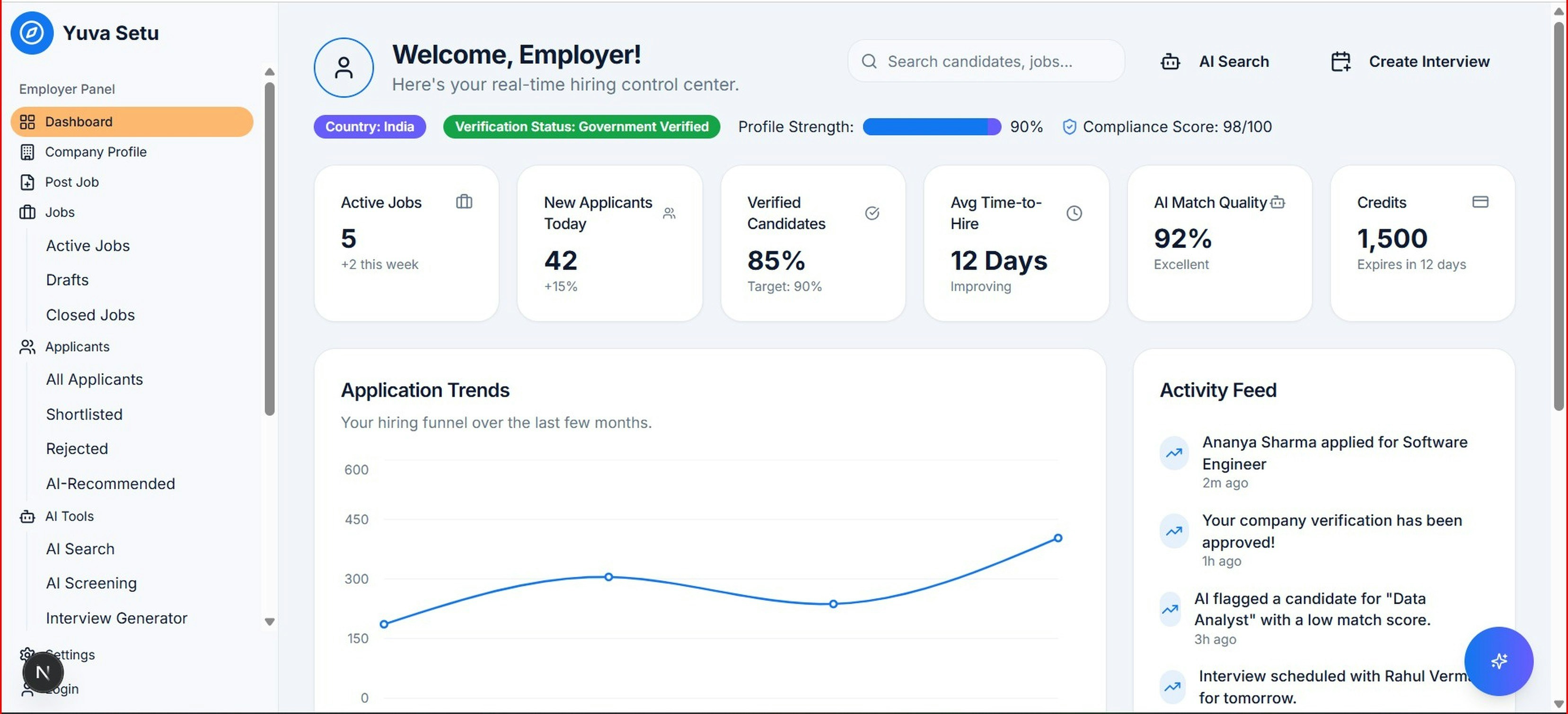
Descubre por qué renombré mi herramienta de seguridad para agentes de IA y añadí un dashboard de equipo. Una evolución impulsada por el uso remoto y la autonomía.

Descubre cómo el modo Lockdown de ChatGPT evita el robo de datos mediante inyección de prompts, aunque limita la navegación web. Protege tu privacidad.

Tokenpocalipsis: costos de IA se disparan. Sistemas agentivos maduran y la seguridad es crítica. Novedades de OpenAI, Microsoft, Apple y más.

Descubre ZEDD: detección ligera de inyecciones de prompts en LLMs sin entrenamiento, con >93% de precisión y <3% de falsos positivos. ¡Escalable y eficaz!

Descubre RECAP, un benchmark que revela que los métodos actuales de optimización de prompts no se adaptan proactivamente a cambios en restricciones. ¿Qué falla?

RECAP: benchmark que mide la adaptación proactiva de prompts en agentes de IA. Descubre por qué los métodos actuales fallan ante restricciones cambiantes en producción.
Descubre AdaGRPO: algoritmo de RL adaptativo para modelos de flujo T2I. Mejora selección de prompts y estimación de ventajas. ¡Optimiza tu entrenamiento!

Descubre cómo SS-TPT logra un equilibrio robustez-rendimiento usando estabilidad y adecuación para seleccionar las mejores vistas. Lee más.

Los modelos de lenguaje en salud fallan ante cambios sutiles en prompts, generando errores clínicos. Un estudio revela que variaciones mínimas pueden alterar diagnósticos y recetas.

Descubre MHA-RAG, el nuevo framework que mejora RAG en un 20% de precisión y reduce costos 10x usando prompts suaves y atención multi-cabeza. ¡Más rápido y eficiente!

La ingeniería de prompts ya no es ventaja competitiva. Descubre por qué la ingeniería de sistemas es la habilidad más valiosa en IA.