dLLM-Cache: Caché Adaptativa para Modelos de Lenguaje con Difusión
dLLM-Cache acelera hasta 9x modelos de difusión con caché adaptativa, sin entrenamiento y con latencia cercana a modelos autoregresivos.
dLLM-Cache acelera hasta 9x modelos de difusión con caché adaptativa, sin entrenamiento y con latencia cercana a modelos autoregresivos.
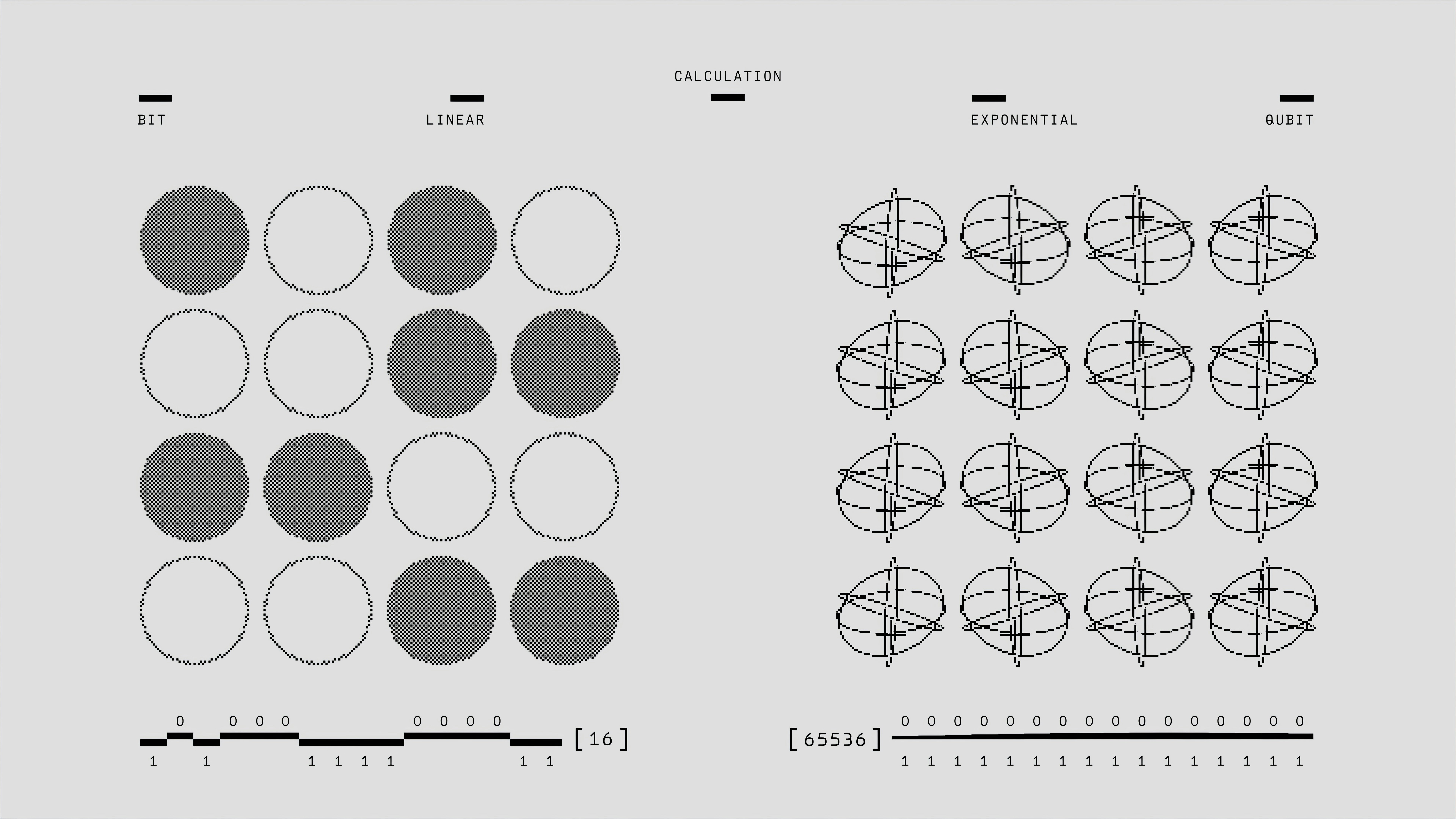
Descubre PAND: destilación de vecindad consciente de prompts para clasificación visual fina. Supera al estado del arte con modelos ligeros.

Descubre la metodología rigurosa de Gate AI para evaluar detectores de inyección y jailbreaks en LLM con umbral único y 16 benchmarks. Resultados sin sesgos.

Aprende a combinar LoRAs sin entrenamiento con ponderación por prompt para lograr composiciones de múltiples conceptos con alta fidelidad.

Descubre cómo ADPrompt adapta GNNs pre-entrenadas con un doble prompting que reduce sesgos de atributo y estructura, mejorando la equidad en clasificación de nodos.

Aplica protocolos de evaluación basados en pruebas de aceptación para sistemas LLM seguros, confiables y alineados con el negocio.
Protege tu sistema de calificación: conoce los ataques de inyección de instrucciones en LLM y cómo mitigarlos.

Message Tuning supera al Graph Prompt Tuning: la Teoría del Espacio Prismático explica por qué. Descubre el nuevo método MTG.

Descubre marco optimización prompts que utiliza evaluación unificada para mejorar calidad respuestas por consulta. Resultados interpretables y consistentes.
Descubre cómo un comentario en GitHub secuestra agentes de IA en CI y extrae secretos. Protege tus pipelines con un firewall de herramientas.
Crea un reescritor de currículums con IA y LangChain en Node.js. Optimiza tu perfil con prompts inteligentes y streaming. ¡Guía práctica!

Descubre qué herramienta de Claude te evitaba escribir los mismos prompts una y otra vez, y por qué Anthropic la retiró. Conoce alternativas y soluciones.

Descubre DetailMaster, el nuevo benchmark para evaluar modelos de texto a imagen con prompts de hasta 284 tokens. ¿Tu modelo lo logra? Entérate.

Los distractores visuales afectan a los modelos visión-lenguaje de forma distinta a los textuales: reducen precisión sin alargar el razonamiento. Aprende a mitigarlos.

Mitiga alucinaciones en LLMs con soft prompts: un método ligero que mejora la precisión y fomenta la abstención responsable. Ideal para aplicaciones críticas.

KG-FairDiff reduce sesgos demográficos en generación de imágenes vía refinamiento de prompts con grafos de conocimiento. Sin reentrenamiento, mejora equidad.

Descubre VERA, un framework de inferencia variacional que genera prompts adversariales para identificar vulnerabilidades en LLMs sin reoptimización.

El 45% de las empresas lucha por asegurar sus agentes de IA. Aprende a implementar las 4 capas de seguridad críticas: aislamiento, control, identidad y monitoreo.

Instala un arnés a tu IA de código con AGENTS.md, commits previos y pruebas. Convierte a tu asistente en un colaborador seguro y revisable.

Descubre cómo reducir tu factura de APIs de IA hasta un 90% con estrategias de selección de modelos, caching y enrutamiento inteligente. Guía práctica para desarrolladores.