Clasificación óptima y justa con puntuaciones calibradas bajo suficiencia
Logra decisiones justas en clasificación binaria con puntuaciones calibradas usando un algoritmo de post-procesamiento que garantiza suficiencia.
Logra decisiones justas en clasificación binaria con puntuaciones calibradas usando un algoritmo de post-procesamiento que garantiza suficiencia.

El Puente de Identidad: un simple ajuste en los datos de entrenamiento que rompe la maldición de la reversión en modelos de lenguaje. Logra un 50% de éxito.

ProtoT usa prototipos para modelos de lenguaje interpretables, permitiendo transparencia y ediciones dirigidas.

KnowledgeBerg: benchmark que evalúa cobertura sistemática y razonamiento composicional en LLMs. Resultados clave sobre sus limitaciones.
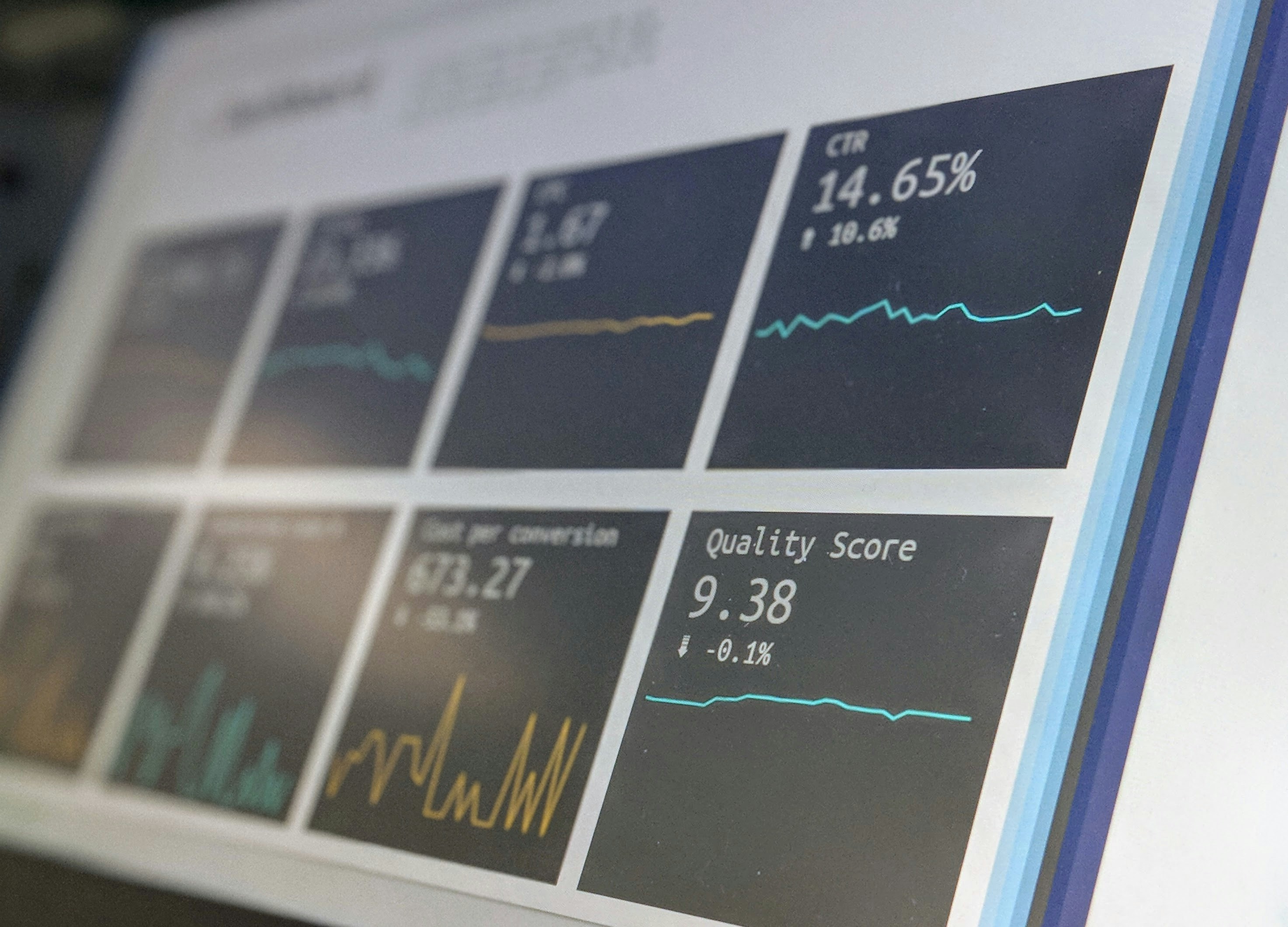
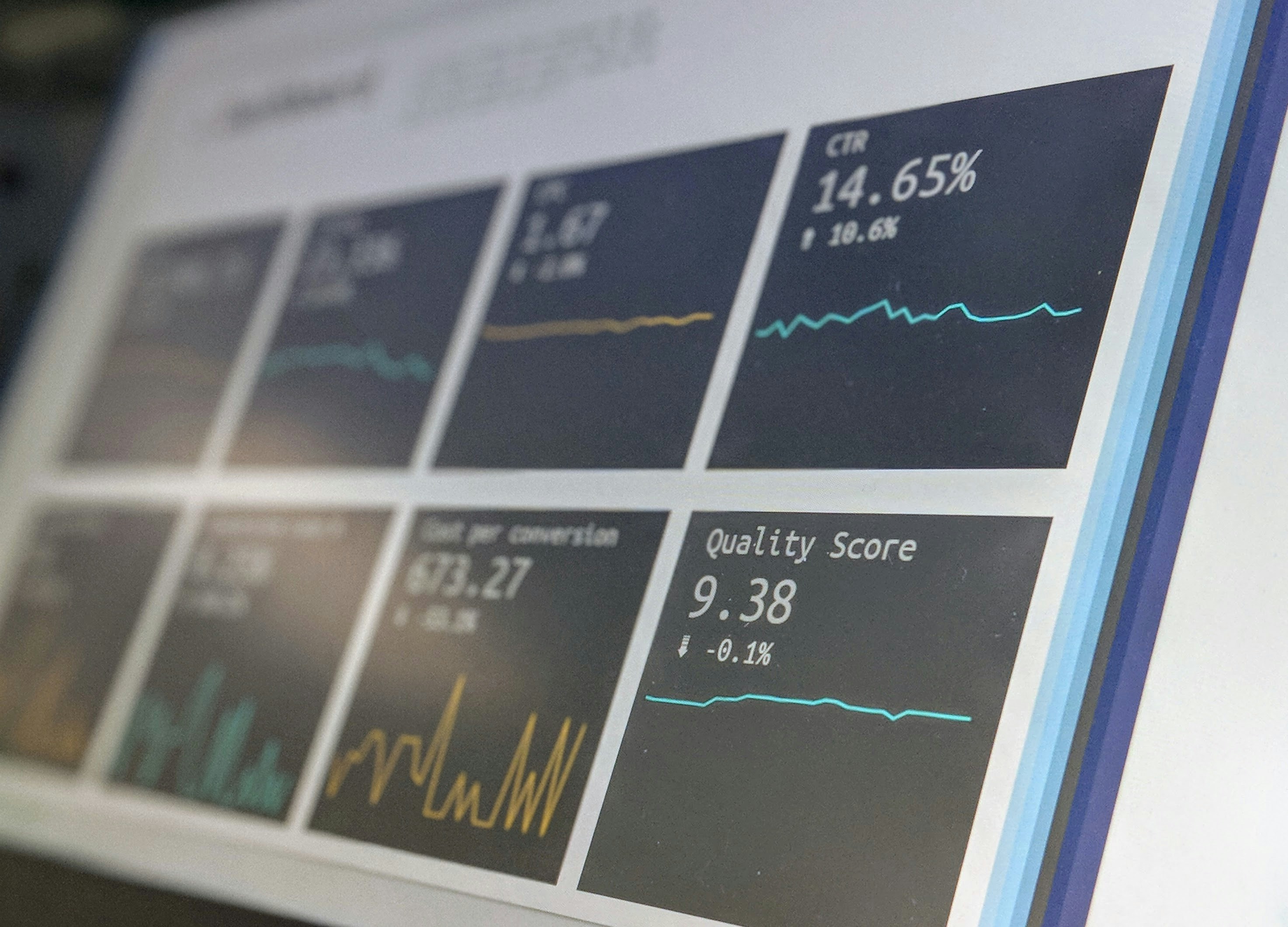
Descubre HiFi-KPI, el dataset con 1.65M de párrafos y 198k etiquetas jerárquicas para extraer KPIs de informes financieros. Modelos de IA alcanzan 0.906 F1 en clasificación.
Descubre EuroBERT, la nueva familia de codificadores multilingües. Supera a alternativas en recuperación, clasificación y más. Soporta 8,192 tokens.

LightOn lanza oferta SaaS soberana para integrar IA documental con soberanía de datos. Descubre cómo simplifica la adopción segura.
Nuevo modelo multimodal de Alibaba, Qwen3.7-Plus, a bajo costo pero propietario. Analizamos su rendimiento, precios y licencia.

Migra tu base de datos Access a una app moderna con IA. Mejora seguridad, acceso multiusuario y análisis predictivo. Q2BSTUDIO te guía en el proceso.

Descubre cómo una red ligera y sin entrenamiento logra segmentar y reconocer texto en escenas con alta eficiencia, reduciendo costos computacionales y manteniendo precisión.

Un nuevo marco de IA combina bases de datos textuales ligeras y LLM para planificar síntesis de nanomateriales, logrando resultados en solo tres iteraciones.
Descubre SG-NTF, un innovador método de factorización de Tucker guiado por espectro para completar tensores de alta dimensión e incompletos con eficiencia paramétrica.
Descubre cómo el clustering de verbos basado en un léxico sintáctico mejora el análisis sintáctico del francés en parsers probabilísticos.
Descubre cómo generar datos sustitutos para pruebas estadísticas no paramétricas en grafos dirigidos, superando limitaciones de métodos existentes.
Descubre un algoritmo práctico y óptimo para bandits contextuales lineales con O(log log T) actualizaciones. Máximo rendimiento con mínima complejidad.

Detección contextual de habla infantil en grabaciones largas: modelos auto-supervisados logran +13.8% F1, superando a sistemas basados en reglas en múltiples idiomas.

Descubre cómo la nueva arquitectura dual-encoder con fusión Choquet mejora la clasificación acústica submarina, ofreciendo precisión e interpretabilidad.

Descubre GottBERT, el primer modelo RoBERTa entrenado solo en alemán. Excelente en NER y clasificación. Descárgalo bajo licencia MIT.

Los modelos de difusión enmascarada (MDLM) son sensibles a pequeños desplazamientos posicionales. Descubre cómo CTC mejora el ajuste fino y supera a la entropía cruzada en cuatro benchmarks.

Las redes profundas aprenden a analizar lenguajes libres de contexto usando solo estadísticas locales. Un estudio revela cómo emergen representaciones jerárquicas.