
Tasas adaptativas con probabilidad sustituta para FTPL
Descubre cómo las tasas de aprendizaje adaptativas con probabilidades sustitutas mejoran el algoritmo FTPL, logrando garantías de mejor de ambos mundos sin perder eficiencia computacional.
Descubre cómo las tasas de aprendizaje adaptativas con probabilidades sustitutas mejoran el algoritmo FTPL, logrando garantías de mejor de ambos mundos sin perder eficiencia computacional.

El Suavizado Exponencial de Wasserstein extiende el clásico ES a series de distribuciones. Descubre cómo estimar el parámetro de suavizado y sus aplicaciones en finanzas y energía.

Optimiza la dinámica de Fokker-Planck con campos gauge no reversibles, Hamiltonianos supersimétricos y aprendizaje de fuerzas finitas mediante actor-critic.

Descubre cómo SPLIT-PINN generaliza la predicción probabilística de microestructuras en materiales policristalinos.

OPAL optimiza el etiquetado para inferencia precisa, logrando intervalos de confianza válidos con menos muestras etiquetadas. Ideal para medicina y ciencias.
Nuevo marco de aproximación cuantitativa mejora la destilación de flujo en difusión, reduciendo errores hasta 51.9% con particiones no uniformes.

Descubre cómo el nuevo algoritmo A-MWGraD acelera la optimización multiobjetivo en espacios de Wasserstein, logrando convergencia O(1/t²) y mejor muestreo.
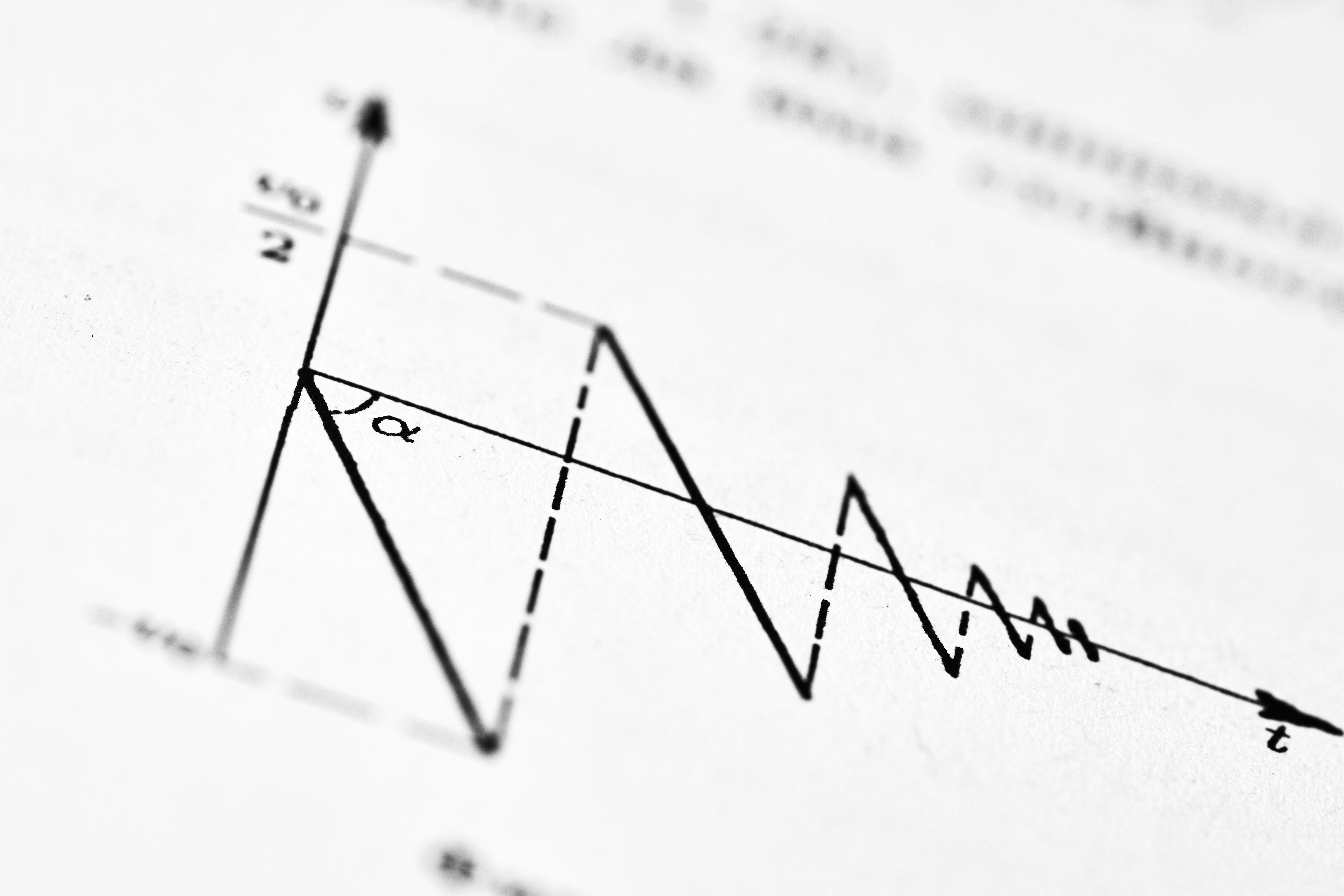
Descubre cómo un enfoque de perturbación logra arrepentimiento óptimo en bandidos lineales no restringidos, con nuevas garantías de alta probabilidad y tasas adaptativas.

E2M revoluciona la predicción de datos no euclidianos con deep learning. Conoce su teoría, rendimiento y aplicaciones en mortalidad y tráfico.

Descubre el análisis teórico del valor Shapley para localizar anomalías en sensores. Comparamos su rendimiento con tests más simples y revelamos sorpresas.

La similitud de coseno entre representaciones de etiquetas no revela las probabilidades del modelo. Descubre qué revela sobre clasificadores softmax y sigmoide.

¿Cómo se relacionan las leyes de escalado con las representaciones internas en deep learning? Este estudio revela una correlación entre rendimiento y estructura

Descubre cómo el Transporte Óptimo de Mezclas (OMT) revoluciona el mapeo entre distribuciones con una solución única y estable. Ideal para big data y bioinformática.

Descubre Grounded Decoding, un método sin entrenamiento que fusiona probabilidades para mejorar la precisión factual en sistemas RAG. Resultados superiores en ALCE, NQ y FActScore.

Desde Pascal hasta la IA: exploramos la evolución de la probabilidad como espejo de la razón y su relación con la lógica difusa y el deep learning.
Descubre cómo mejoramos la estimación de distribuciones discretas bajo norma infinito con nuevas cotas minimax y resultados empíricos prometedores.

Descubre DTop-p MoE, un nuevo mecanismo de enrutamiento dinámico que aprende el umbral de probabilidad para controlar la esparcidad, superando a Top-k y Top-p fijo en modelos fundacionales.

Estudio revela: los cuestionarios psicométricos no reflejan el comportamiento real de los LLM. La generación de probabilidades es más precisa.

Descubre cómo dos comunidades unifican enfoques para recuperar recompensas desde datos offline. Análisis de identificación y algoritmos IRL/DDC.

Descubre cómo las transformaciones de probabilidad inducidas en tiempo de inferencia en LLMs siguen patrones log-ratio reproducibles. Un análisis empírico de 4,975 problemas.