Compresión eficiente de datasets: unificando poda y destilación
Descubre cómo PCA unifica poda y destilación de datasets para compresión eficiente sin etiquetas suaves. Mejora almacenamiento y entrenamiento.
Descubre cómo PCA unifica poda y destilación de datasets para compresión eficiente sin etiquetas suaves. Mejora almacenamiento y entrenamiento.

HEIST: modelo fundacional de grafos para transcriptómica y proteómica espacial. Aprende cómo analiza tejidos con grafos jerárquicos y logra predicciones clínicas de vanguardia.

Optimiza LLM/VLM con compresión de bajo rango informada por activaciones y guiada por Pareto. Logra mayor eficiencia sin sacrificar precisión.

Descubre cómo usar modelos fundacionales de IA para predicción en bases de datos relacionales sin necesidad de entrenar ni ajustar. Con RDBLearn, resultados robustos de inmediato.

MAPL comprime activaciones en paralelismo de tubería con proyecciones ortogonales aprendidas, reduce comunicación sin pérdida de rendimiento en modelos LLaMA.

Descubre cómo Fisher-MoE recorta dimensiones intermedias para comprimir modelos MoE al 50%, reduciendo memoria un 45% y acelerando inferencia un 21% sin perder capacidad.

SelfBootTok equilibra compresión y generación de imágenes con solo 64 tokens, logrando un gFID de 1.56 y reduciendo el cómputo un 40%.

¿Cómo aplicar los derechos de rectificación y supresión del GDPR en modelos de ML? Analizamos los desafíos en cadenas de suministro y el fenómeno 'modelos en la oscuridad'.

Comprime trazas de razonamiento para destilar conocimiento. Reduce tokens de entrenamiento hasta 70% y acelera 7.6x con hasta 96% de precisión.

Descubre cómo el principio de refinamiento dinámico de abstracciones mejora el aprendizaje por refuerzo, usando distorsión de tasa para lograr rendimiento óptimo con compresión.

Descubre 5 herramientas open source y gratuitas para gamers: emuladores, compresión y streaming. Apoya a sus creadores con donaciones en cripto vía Kivach.

Kevin O'Leary reduce a la mitad su centro de datos en Utah tras protestas por uso de agua. Descubre los detalles del proyecto Stratos y su impacto ambiental.

Descubre el increíble récord mundial del Benchy, el icónico barco de prueba para impresoras 3D. ¿Tu impresora puede superarlo?

Descubre LiftQuant: cuantización continua de LLM que permite comprimir modelos de 70B a tan solo 2.4 bits, ajustándose perfectamente a tu memoria GPU.

Aprende cómo los navegadores modernos comprimen imágenes directamente en el cliente, ahorrando ancho de banda y protegiendo la privacidad. ¡Descubre las APIs clave!

Descubre cómo un nuevo enfoque de NAS optimiza arquitectura y cuantización en LLM, logrando hasta 1.4x más velocidad y 6% más precisión en tareas de razonamiento. ¡Mejora tus despliegues en edge!

Descubre BRAINCELL-AID, un sistema de IA agéntica que revoluciona la anotación de tipos celulares cerebrales. Mejora la precisión con RAG y análisis de RNA-seq.

Descubre YAQA: algoritmo de redondeo adaptativo que reduce el error de cuantización un 30% frente a GPTQ. Cotas de error garantizadas sin coste de inferencia.
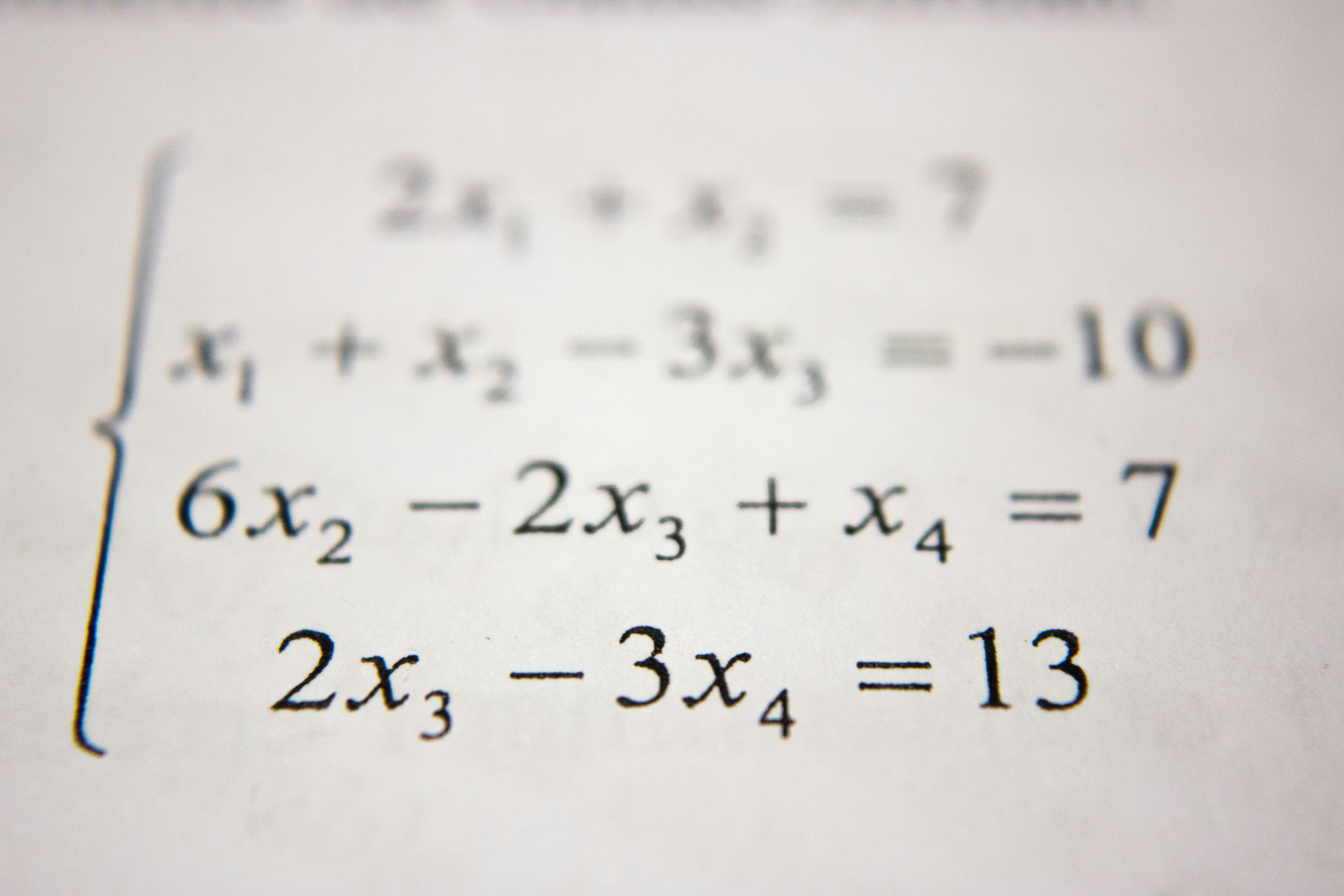
Descubre YAQA, el algoritmo de redondeo adaptativo que reduce el error de cuantización un 30% sin sobrecarga. Preserva la distribución del modelo original.

Descubre cómo el post-razonamiento y UCoT comprimen cadenas de pensamiento en LLMs, reduciendo tokens un 50% sin perder rendimiento. ¡Mejora la eficiencia!