
ProjQ: Compresión de LLM con Cuantización y Adaptadores
ProjQ revoluciona la compresión de LLMs al proyectar el ruido de cuantización en un subespacio de bajo rango. Obtén modelos más ligeros y eficientes con fine-tuning mejorado.
ProjQ revoluciona la compresión de LLMs al proyectar el ruido de cuantización en un subespacio de bajo rango. Obtén modelos más ligeros y eficientes con fine-tuning mejorado.

GC-MoE utiliza mezcla de expertos guiada por genómica para predecir expresión génica por célula desde histología, mejorando la precisión en transcripción espacial.

SubFit comprime LLMs a nivel de submódulos con selección no contigua. Mejora el equilibrio precisión-perplejidad, acelera inferencia y ahorra memoria KV-cache. ¡Más eficiente!
AdaCodec reduce tokens visuales en video MLLMs hasta 1/7, mejorando benchmarks y reduciendo tiempo de primera respuesta de 9.26s a 1.62s.
Descubre cómo ACON comprime el contexto de agentes LLM sin reentrenar, reduciendo tokens hasta un 54% y mejorando el éxito en tareas largas. ¡Optimiza tu IA!

Descubre por qué el software de laminado es más determinante que tu impresora 3D para lograr piezas perfectas. Consejos clave para optimizar tus impresiones.

TRACE comprime evidencia de riesgo en trayectorias de agentes para mejorar la seguridad en tareas de largo plazo. ¡Alta precisión!
Optimiza el submuestreo en compresión de sensores con modelos generativos de flujo. Logra reconstrucciones de imágenes de alta calidad con solo el 5% de datos. Ideal para MRI.
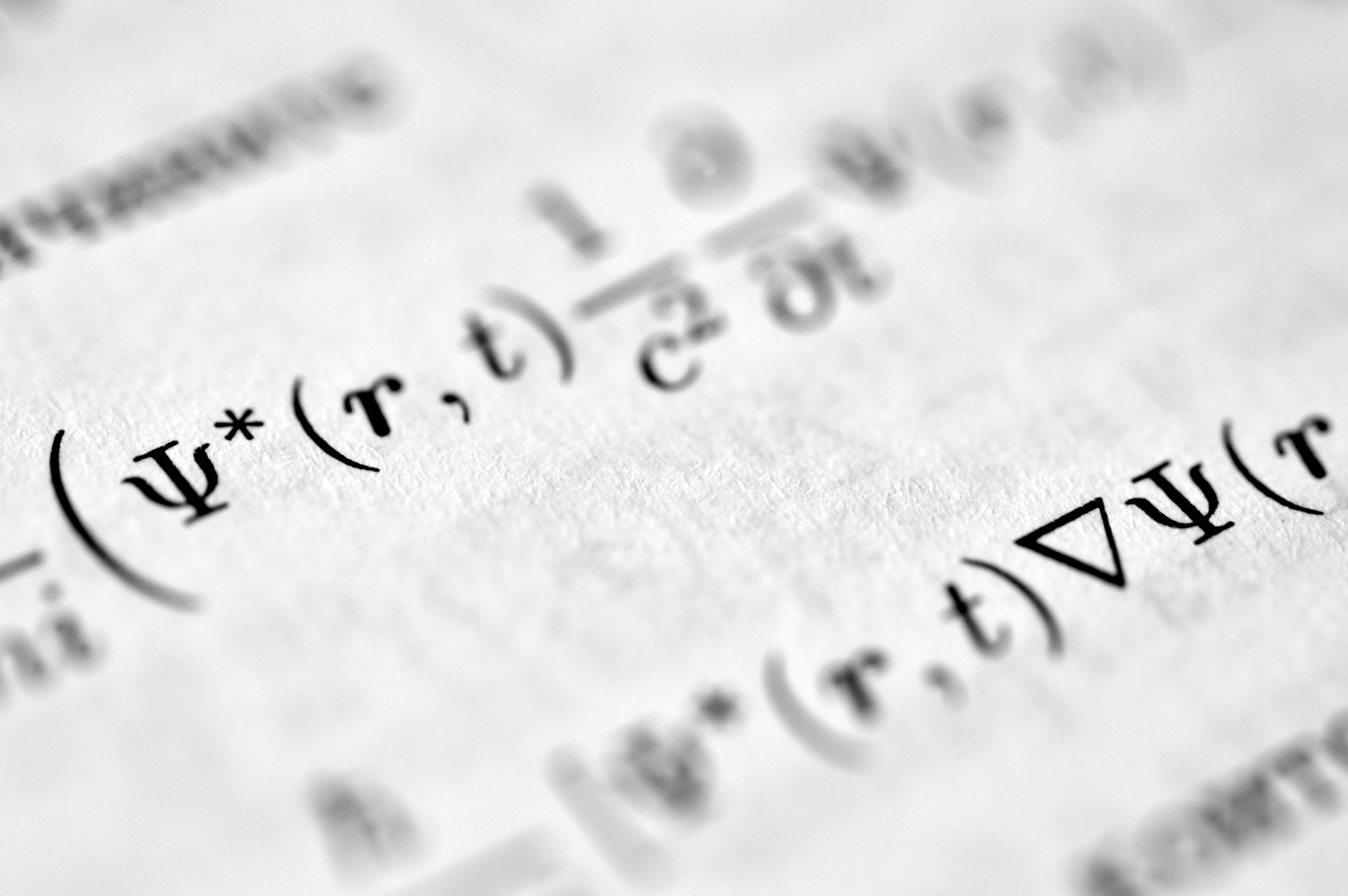
BitsMoE asigna bits inteligentemente en MoE LLM, logrando cuantización 2 bits con 27.83% más precisión, 12.3x más rápida y 1.76x más velocidad.

Explora ADNTN: comprime DNN hasta 77,000x, mejorando precisión. Redes tensoriales no lineales automáticamente diferenciables.

Nuevo método de clasificación guiada por puntuación detecta depresión con EEG sin aumentación de datos, mejorando precisión.

¿Son únicas las representaciones que aprende tu modelo? Descubre el criterio de fibra para identificar si las propiedades de representación son identificables en aprendizaje supervisado.

Descubre cómo MiCU, un LLM especializado, mejora un 20% la precisión en comandos del hogar inteligente y reduce correcciones un 1.57%. ¡Lee más!

Aprende a comprimir redes neuronales agrupando neuronas por equivalencia diferencial. Reduce parámetros sin perder precisión, alternativa eficaz.

STaR-KV comprime la caché KV en modelos GUI sin entrenamiento, reduciendo memoria GPU un 40% sin penalizar precisión. Descubre cómo.

El marco S^3 suprime atajos específicos de falsificación para lograr detección de deepfakes generalizable y robusta, mejorando el rendimiento en nuevos métodos de ataque.

Descubre cómo optimizar modelos de video Wan2.2 con destilación y cuantización de baja precisión. ¡Mejor calidad, menos pasos!

Descubre cómo los límites informacionales afectan la optimización estocástica con gradientes de baja precisión: reducción a estimación gaussiana.
La dinámica de entropía revela la fragilidad de los orquestadores y la trampa del razonamiento en sistemas multiagente. Identifica el colapso del rendimiento.

Descubre cómo DASH comprime modelos de difusión manteniendo calidad y guía, superando al entrenamiento desde cero.