
Cumpliendo SLOs, Reduciendo Horas: Optimización Automatizada de LLM con OptiKIT
Optimiza LLMs empresariales sin experiencia previa gracias a OptiKIT: duplica el rendimiento GPU y reduce horas de trabajo.
Optimiza LLMs empresariales sin experiencia previa gracias a OptiKIT: duplica el rendimiento GPU y reduce horas de trabajo.

Descubre Hyperflux, un método de poda que revela la importancia de cada peso mediante flujo y presión. Reduce latencia y energía manteniendo precisión.

EinSort: ordenando índices para tensorizar LLMs. Descubre estructuras de rango bajo y comprime pesos y KV-cache con mejor calidad. ¡Optimiza tus modelos!

SNR-ST-Mix mejora la imputación en transcriptómica espacial con aumentos basados en vecinos espaciales y similitud de expresión, sin aumentar la complejidad del modelo.

Descubre EntropyInfer: un método sin entrenamiento que acelera hasta 2.39x la inferencia de LLMs en contextos largos, adaptando dinámicamente la atención por cabeza y segmento.
Los grafos de conocimiento y LLMs con RL logran predecir perturbaciones transcriptómicas con alta precisión, superando a métodos complejos. Descubre cómo.

Descubre cómo los IDs semánticos y un transformador de compresión global reducen costos y escalan la recomendación de videos cortos a miles de millones de usuarios.

Descubre cómo MoEngage logró personalización en milisegundos con ScyllaDB, manejando 250K escrituras/segundo y 200TB+ de datos con latencia p99 de 1ms.
Descubre por qué tu pipeline Kafka funciona en staging pero falla en producción. Aprende a evitar 4 modos de fallo comunes y protege tus datos con gobernanza.

El rapero Afroman se vuelve héroe de Bitcoin tras ganar caso a la policía, aunque aún no entiende bien la criptomoneda. Conoce su historia.

Descubre NTILC: reduce el consumo de contexto un 95% y la latencia un 74% en selección de herramientas con aprendizaje latente. Optimiza tus modelos.

Descubre cómo NTILC revoluciona la invocación de herramientas en modelos de lenguaje: reduce contexto un 95% y latencia un 74%. Aprendizaje latente eficiente.
Descubre EgoPressDiff, un marco de difusión multimodal que estima presión manual con un 34% más de precisión, ideal para AR/VR.

OpticalDNA transforma el modelado genómico usando OCR y visión artificial, logrando 20x menos tokens y superando modelos con 985x más parámetros. Descubre cómo.

Los modelos de lenguaje mejoran la compresión de audio sin pérdida. Trilobyte permite compresión a 24 bits, superando a FLAC en 8 y 16 bits.
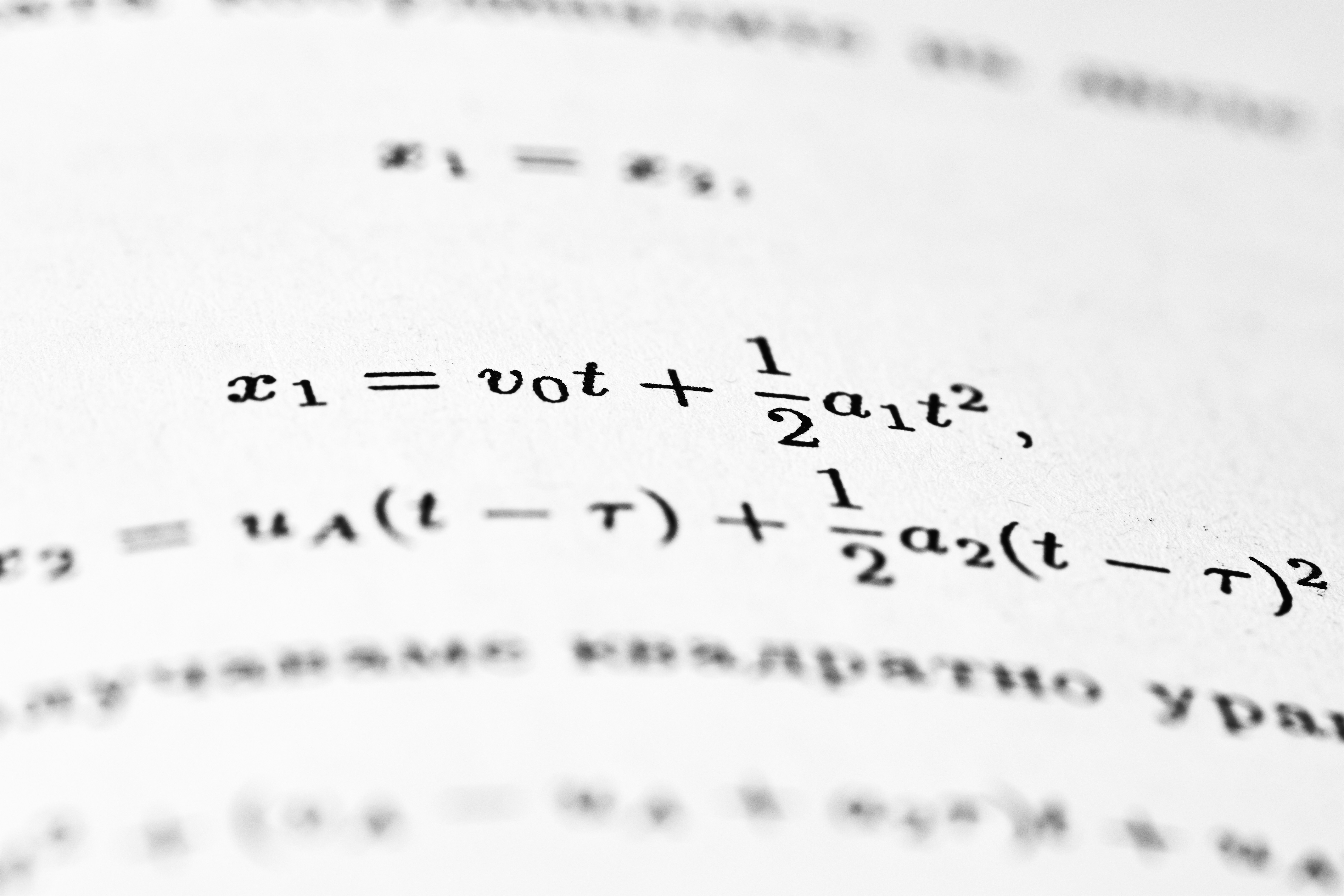
Descubre GPLFR: nuevo modelo de regresión que acopla compresión y predicción para datos escasos y alta dimensionalidad. Emuladores climáticos de exoplanetas.

Analizamos la sensibilidad al orden en transformers para decisiones binarias y presentamos un nuevo enfoque para medir confianza y reducir alucinaciones.

Descubre cómo el aprendizaje automático informado por reactividad predice la resistencia de escorias activadas y optimiza el diseño sostenible.

Descubre SigmaScale, método para comprimir LLMs con descomposición SVD y matrices de escala aprendidas. Reduce costo computacional sin perder rendimiento.

Optimiza la conducción autónoma con COMPACT-VA: compresión de tokens alineada con la planificación logra 68% éxito y 3.3x aceleración.