
Aprendizaje de audio con preentrenamiento sintético y generación procedural
Descubre cómo AudioPG entrena representaciones de audio sin datos reales, logrando alta precisión en benchmarks como ESC-50 en menos de 20 minutos en una GPU.
Descubre cómo AudioPG entrena representaciones de audio sin datos reales, logrando alta precisión en benchmarks como ESC-50 en menos de 20 minutos en una GPU.
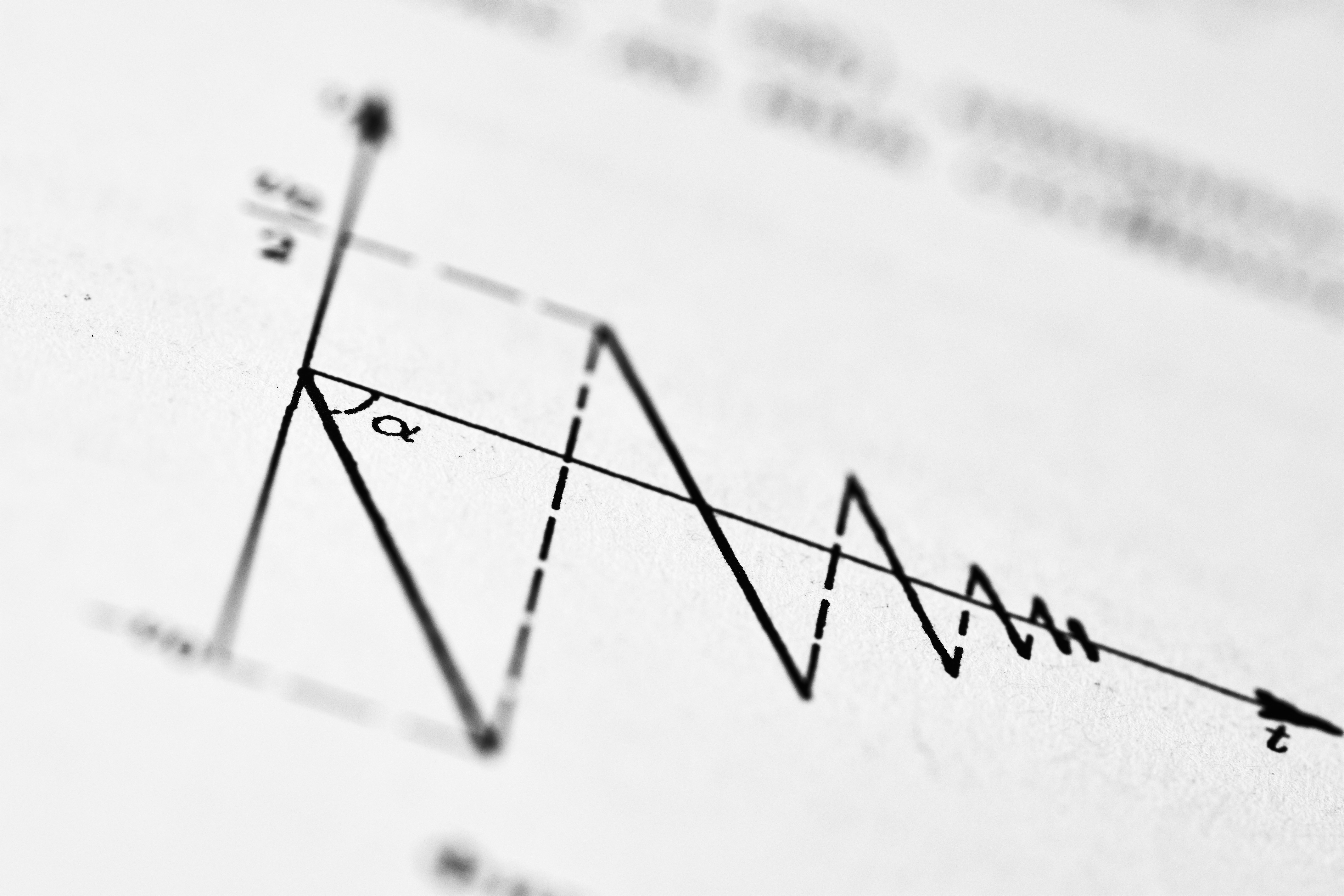
Descubre CausalLongPFN, un modelo preentrenado con datos sintéticos que predice resultados contrafactuales en secuencias temporales sin necesidad de reentrenamiento. Competitivo en benchmarks reales.