
Límites de generalización de longitud en transformers
Descubre por qué no existen límites computables de generalización de longitud para transformers y C-RASP, y cómo afecta al aprendizaje automático.
Descubre por qué no existen límites computables de generalización de longitud para transformers y C-RASP, y cómo afecta al aprendizaje automático.

Descubre ASKD-Whisper, una técnica de destilación adaptativa que acelera 5x el reconocimiento de voz y supera al profesor en precisión.

Descubre cómo LASER logra una aceleración 2.3x en modelos visión-lenguaje con baja precisión, usando SVD consciente de pérdida y asignación de rango.

GPTQ-intrinsic LoRA: mejora la cuantización de baja precisión con corrección de bajo rango. Algoritmo casi óptimo para modelos grandes.

GPTQ-intrinsic LoRA combina cuantización de baja precisión y adaptación de bajo rango para comprimir redes neuronales. Algoritmo sin entrenamiento mejora modelos como Qwen3 y DeiT.

Descubre cómo una red con atención multi-cabeza alcanza R² 0.84 en predicción de reflectancia foliar, supera modelos clásicos. Ideal para monitoreo de viñedos.
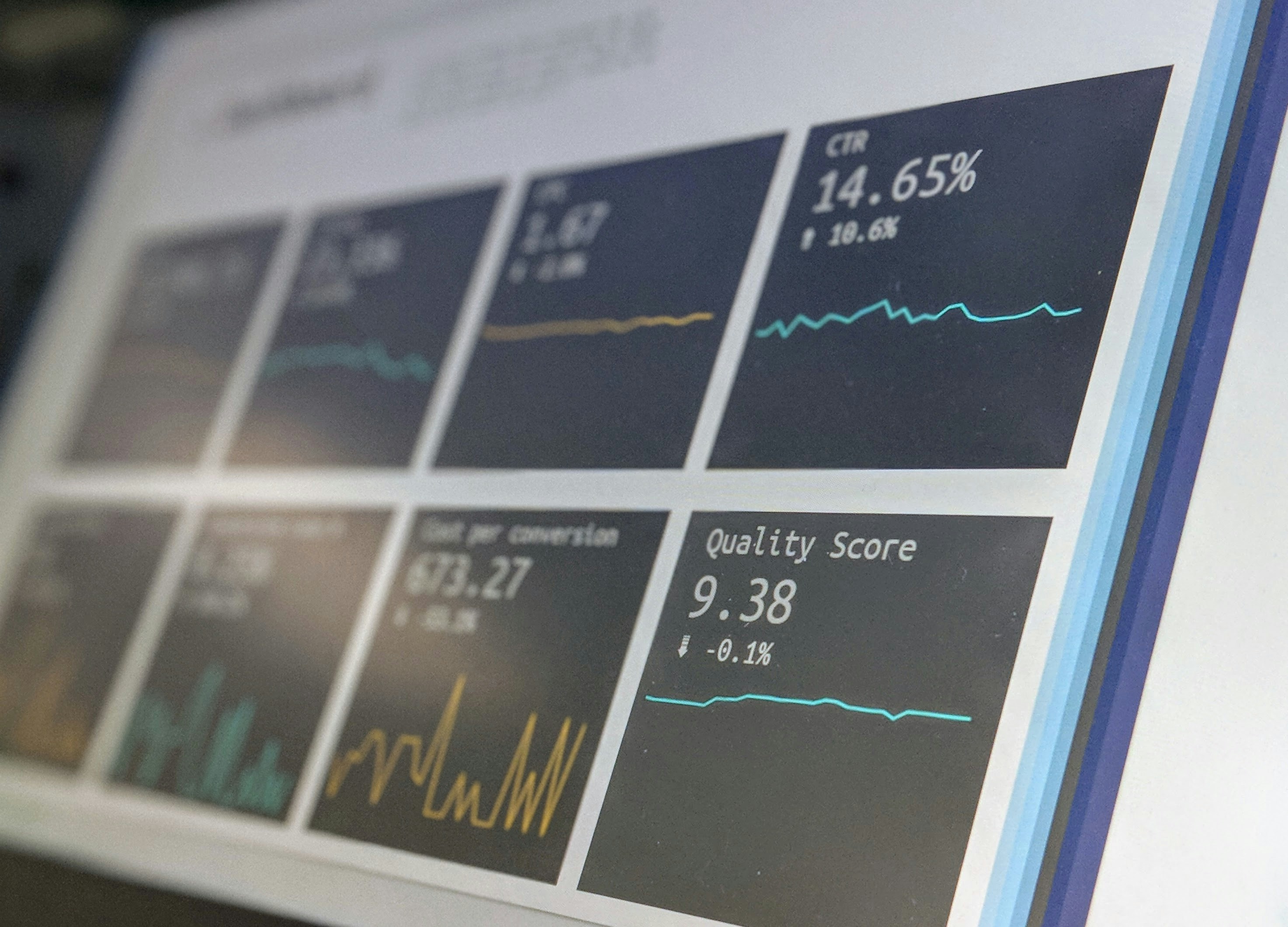
Modernizar aplicaciones legacy asegura la precisión de datos mediante validación, conciliación y gobernanza. Calidad de datos confiables.

Estudio evalúa la fiabilidad de motores de búsqueda y asistentes IA al responder preguntas factuales en chino, revelando diferencias clave.

Agente de RL optimiza señales de excitación para identificación de parámetros en sistemas mecatrónicos, superando métodos clásicos con solo 0.75% de violaciones

La cuantización agresiva reduce la precisión y alarga el razonamiento de los modelos de IA. Descubre cómo una penalización simple en tokens de 'overthinking' mejora la eficiencia.

Descubre cómo los algoritmos de cuantización adaptativa preservan el producto interno de vectores, ofreciendo precisión y velocidad hasta 10 veces mayor.

Descubre GNMR, un controlador ligero que estabiliza el entrenamiento de modelos de lenguaje en baja precisión sin cambiar el formato numérico. Mejora la calidad y reduce costes.
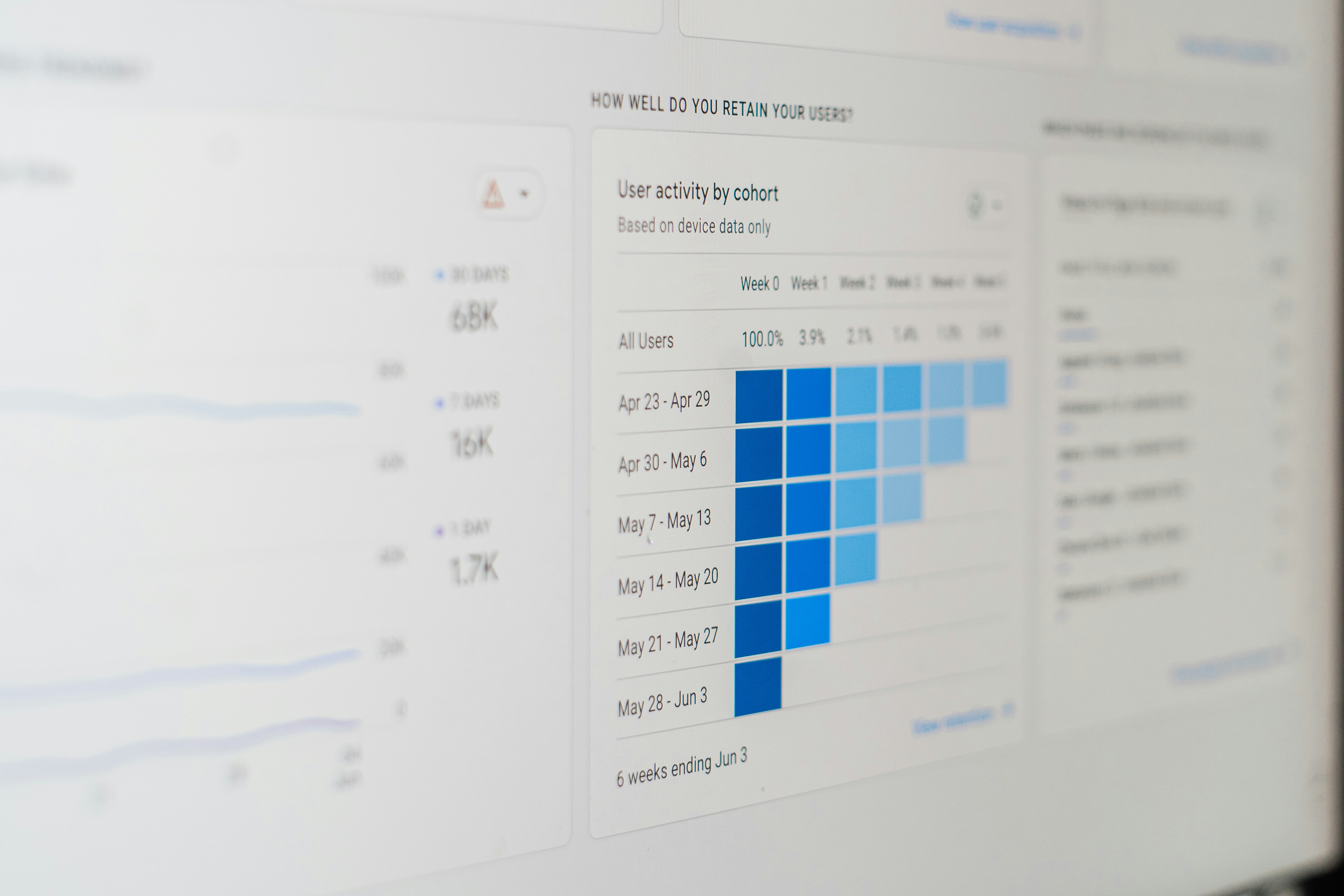
Moment-Video evalúa la capacidad de MLLM para captar eventos visuales que duran solo unos fotogramas. Resultados sorprendentes.

SubFit comprime LLMs a nivel de submódulos con selección no contigua. Mejora el equilibrio precisión-perplejidad, acelera inferencia y ahorra memoria KV-cache. ¡Más eficiente!
Descubre cómo los agentes de ingeniería de software con LLM logran un 41.6% de precisión en la localización de fallos del kernel de Linux. Mejora tu depuración con IA.

Descubre AXIOM, una arquitectura neuro-simbólica que combina IA y sistemas algebraicos para razonamiento matemático verificable con 94% de precisión y cero errores.

Descubre CAREAgent, el agente clínico que combina razonamiento estructurado y herramientas integradas para generar órdenes clínicas precisas. Mejora el F1 un 5%

Descubre cómo ComProScanner extrae datos de materiales de figuras científicas con precisión del 97%. Automatiza tu investigación.
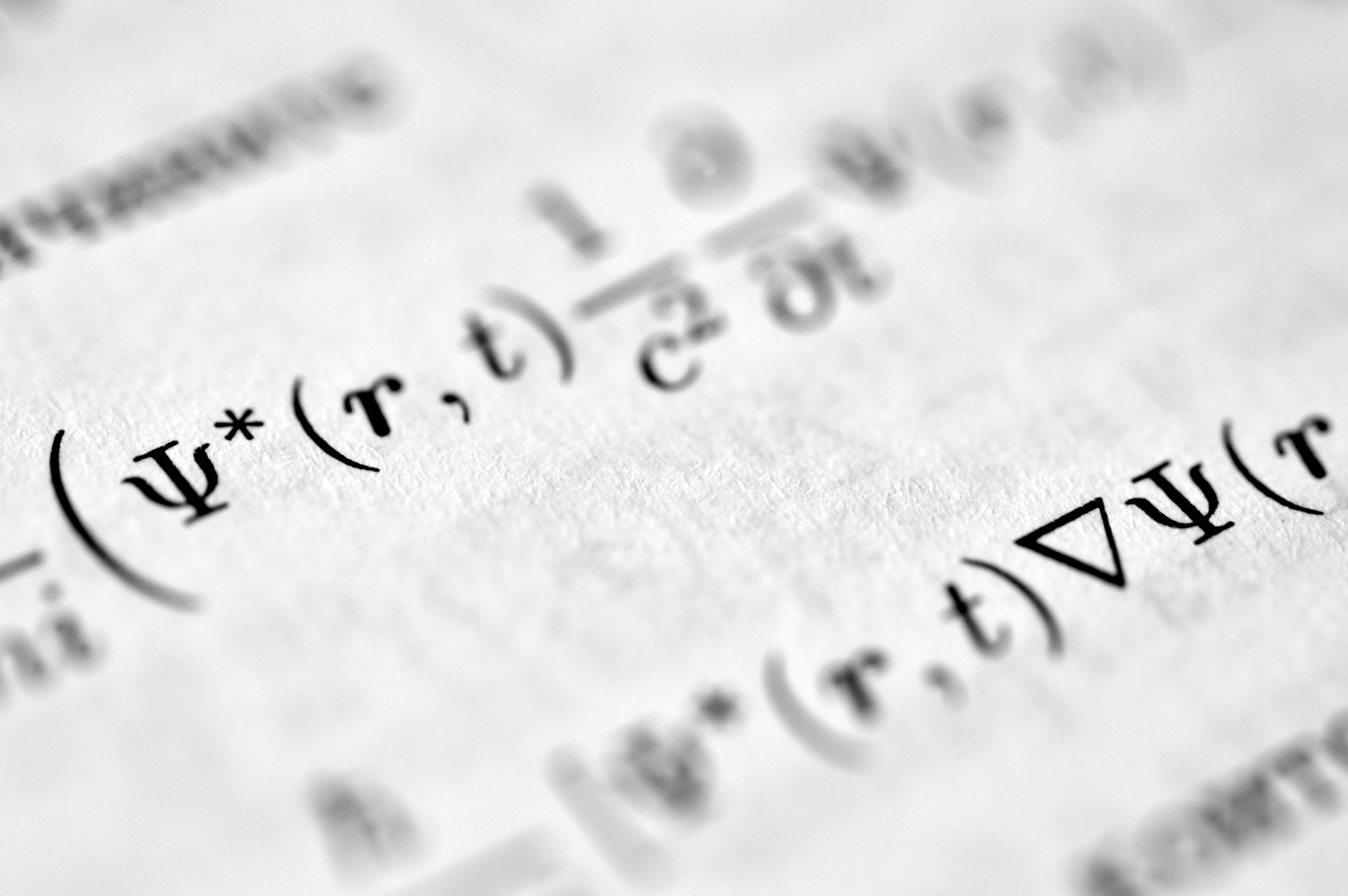
BitsMoE asigna bits inteligentemente en MoE LLM, logrando cuantización 2 bits con 27.83% más precisión, 12.3x más rápida y 1.76x más velocidad.

DLLM-JEPA: nueva arquitectura que combina JEPA y difusión enmascarada para reducir FLOPs un 33% y ganar hasta 18.7% en precisión.