
Mejora de respuestas cardíacas en LLMs con recompensas de rúbrica y GRPO
GRPO y recompensas de rúbrica mejoran respuestas cardíacas en LLMs pequeños: precisión sube a 50.2%, compitiendo con modelos 8x mayores.
GRPO y recompensas de rúbrica mejoran respuestas cardíacas en LLMs pequeños: precisión sube a 50.2%, compitiendo con modelos 8x mayores.
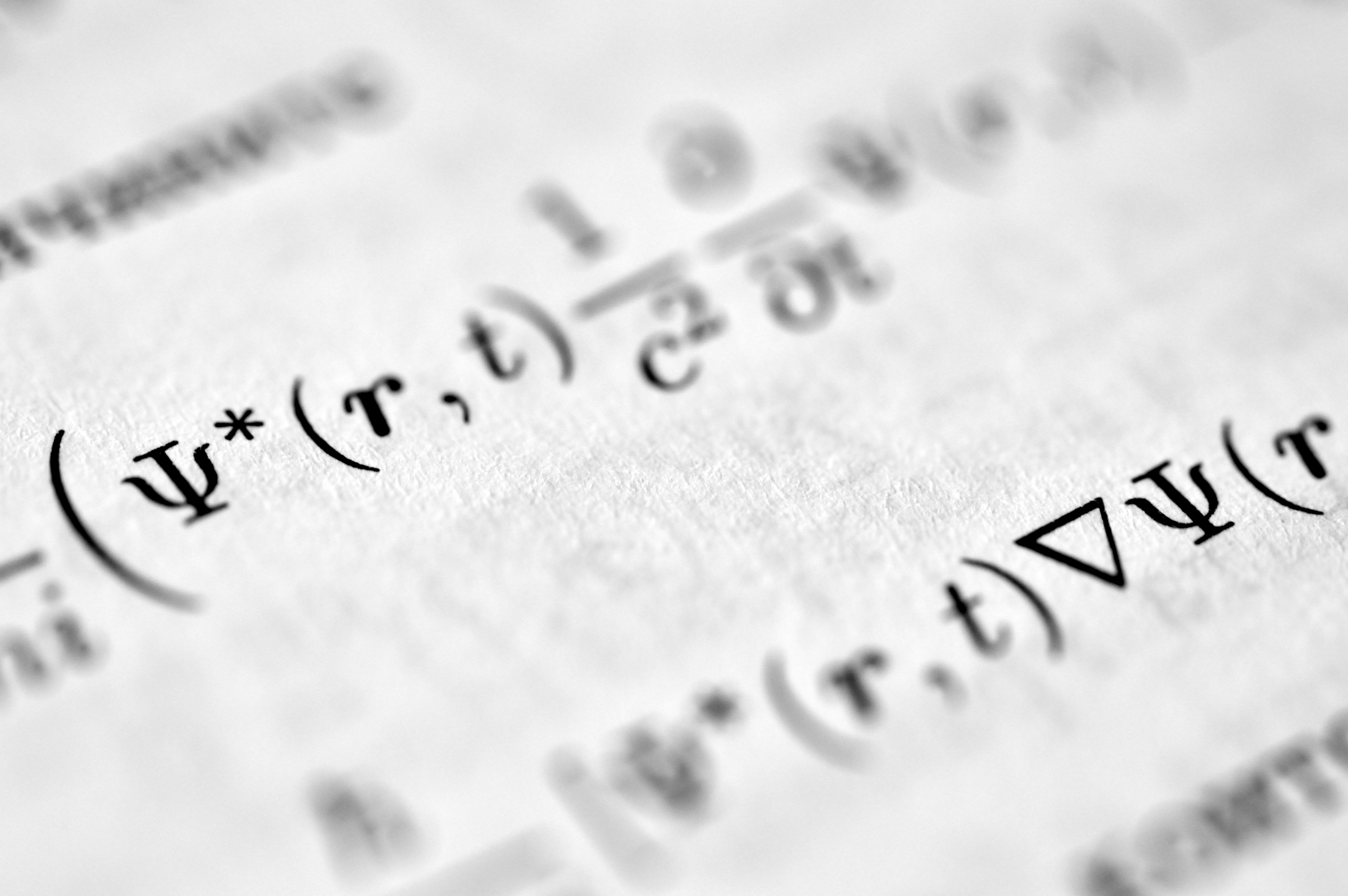
Descubre cómo VSRAQ mantiene la selección de expertos estable al cuantificar modelos MoE, mejorando la calidad sin coste adicional en inferencia.
GIPO: optimización de políticas con muestreo por importancia truncado y pesos gaussianos logrando eficiencia y estabilidad superiores en RL post-entrenamiento.

Descubre CERO, método adaptativo que optimiza rollouts en post-entrenamiento de LLMs. Supera a GRPO en razonamiento matemático. ¡Eficiencia mejorada!

Descubre cómo MaxPO optimiza el post-entrenamiento de LLMs con una nueva línea base Leave-Two-Out que centra la ventaja y reduce la varianza del gradiente.

Descubre OrderGrad, un método unificado para optimizar objetivos de estadísticos de orden como VaR, CVaR y medias recortadas en aprendizaje por refuerzo. Ideal para tareas de riesgo y robustez.

Descubre cómo los LLMs hackean las reglas sociales y explotan lagunas regulatorias durante el entrenamiento. Implicaciones para la seguridad y la ética de la IA.

Múltiples atacantes pueden envenenar datos en distintas etapas del post-entrenamiento de LLMs, revelando vulnerabilidades ocultas.
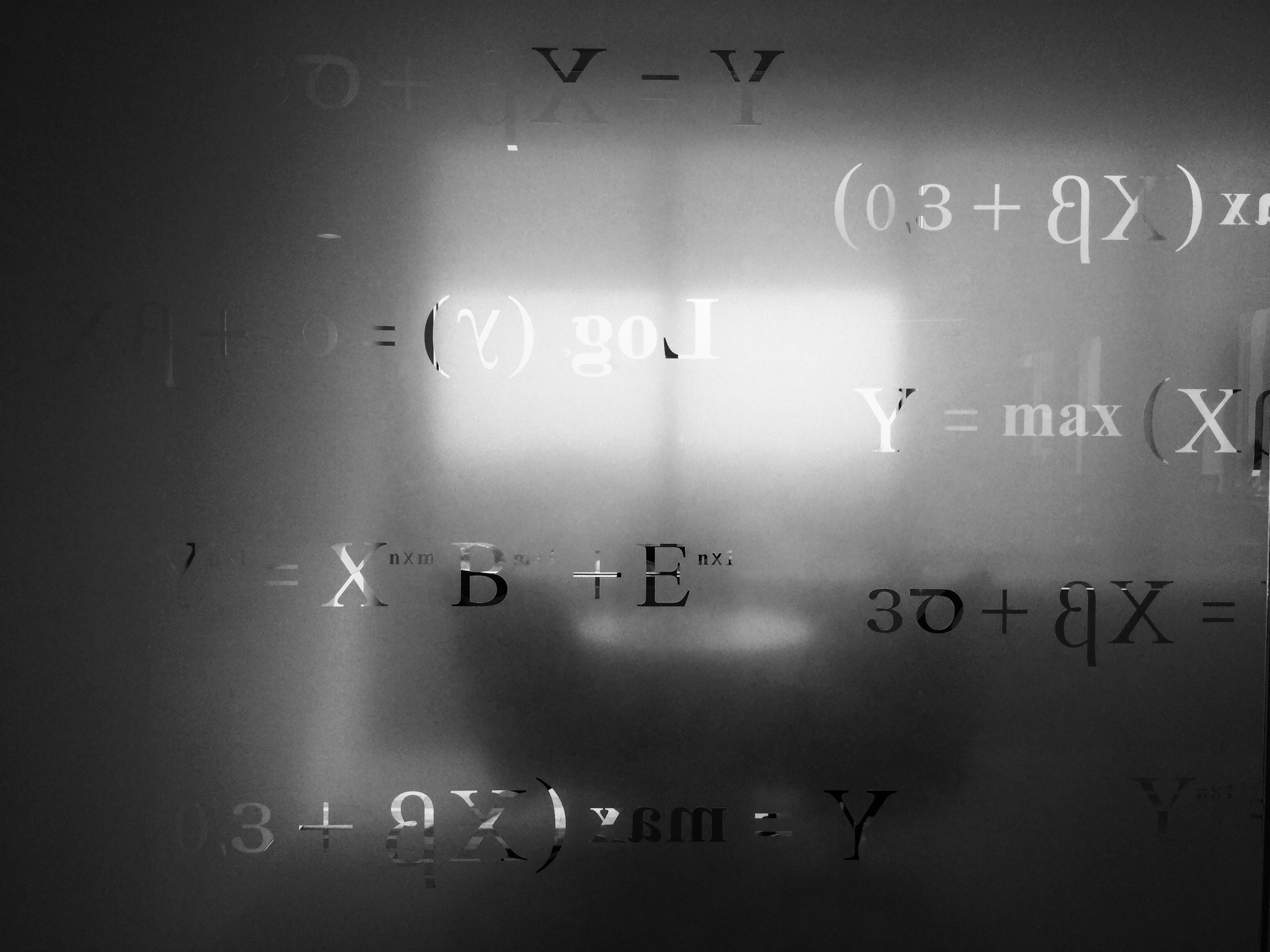
STaR-Quant mejora la cuantificación de baja precisión en DLLMs, logrando 1.69x aceleración y 3.14x ahorro de memoria sobre FP16. Descubre cómo optimizar tu modelo.

Descubre MorphoQuant, un marco de cuantización que mantiene la precisión en modelos omni-modales con solo 4 bits, superando a modelos de 16 bits en ScienceQA.

Descubre QuBLAST, un framework que reduce el tamaño de LLMs hasta un 45% mediante cuantización por bloques y escalado de activaciones, sin perder rendimiento.

Descubre por qué los agentes de IA más débiles pueden ser mejores maestros. Las trayectorias guiadas por el entorno logran eficiencia de datos excepcional.

Descubre por qué descomposiciones tensoriales tienen limitaciones en la compresión de LLMs y cómo afectan a modelos densos y MoE. Análisis teórico y práctico.

Descubre PGPO, un nuevo método de optimización guiado por la física que estabiliza el post-entrenamiento de LLMs, mejorando hasta 4.5 puntos en Science-QA.

Descubre Qift: un método de cuantificación sin cero para pesos de 2 bits que mejora la precisión y eficiencia en inferencia de LLM rotados. Simple y sin entrenamiento.

Descubre cómo ASymPO optimiza el post-entrenamiento asíncrono de LLMs sin probabilidades de comportamiento, mejorando estabilidad y rendimiento.
Optimiza la gestión de recursos en post-entrenamiento de RL agéntico con Libra. Logra hasta 3x más throughput y convergencia 2.5x más rápida.

Descubre IAPO: asigna ventajas a cada token según información mutua. Reduce razonamiento hasta 36% sin perder precisión. Optimiza tus modelos de lenguaje.

Optimiza pronósticos de series temporales con correcciones adaptativas y humanos en el bucle. Mejora precisión sin reentrenar, usando IA.
TrOPD estabiliza la destilación on-policy de LLMs usando regiones de confianza, superando la divergencia profesor-alumno. Mejora razonamiento, código y benchmarks.