
Agrupamiento temporal robusto con modelos de salto ponderados
Descubre un modelo robusto de agrupamiento temporal que pondera características según el estado y maneja outliers con Tukey. Ideal para análisis de conflictos y economía.
Descubre un modelo robusto de agrupamiento temporal que pondera características según el estado y maneja outliers con Tukey. Ideal para análisis de conflictos y economía.

Descubre cómo restaurar la cobertura nominal en Bayes Conformal ante cambios de etiqueta: comparamos calibración post-hoc y adaptación en entrenamiento.

El Agente Ensemble Causal (CEA) usa LLM para re-ponderar expertos en descubrimiento causal, mejorando la precisión de los gráficos causales. ¡Descúbrelo!

DFL-AA corrige sesgo y obsolescencia en aprendizaje federado descentralizado usando ponderación inversa y edad de información. Mejora precisión en redes.

DFL-AA combina ponderación inversa y edad de la información para eliminar sesgo y obsolescencia en aprendizaje federado descentralizado con redes inalámbricas.

Descubre cómo FedBB resuelve el desbalance triple en aprendizaje federado con una función de pérdida balanceada y reponderación de clientes, mejorando la precisión y privacidad.
Descubre phepy, un benchmark visual para evaluar detectores OOD, y las mejoras como t-poking y ponderación que afinan la frontera ID-OOD.

El nuevo algoritmo RT-PG reutiliza trayectorias off-policy para acelerar la convergencia en métodos de gradientes de política, mejorando la eficiencia muestral.

Aprende a combinar LoRAs sin entrenamiento con ponderación por prompt para lograr composiciones de múltiples conceptos con alta fidelidad.

Mejora tus análisis de texto con LLM usando hipótesis condicionales y covariables. Evita sesgos y descubre diferencias reales en subgrupos relevantes.
Nuevo método de submuestreo y reponderación reduce coste computacional en estimación de riesgo contrafactual para eventos raros en datos longitudinales.
Descubre cómo SCOPE mejora el razonamiento de los LLMs con destilación adaptativa dual, logrando un 11.42% más de precisión.

Descubre cómo FW-NKF combina filtros de Kalman con redes neuronales y ponderación de frecuencia para reducir errores de localización en robótica hasta un 10%.

STaR-KV comprime la caché KV en modelos GUI sin entrenamiento, reduciendo memoria GPU un 40% sin penalizar precisión. Descubre cómo.

Descubre cómo la predicción conforme multiagente con validez estadística personalizada mejora la calibración y privacidad en entornos heterogéneos. ¡Lee más!
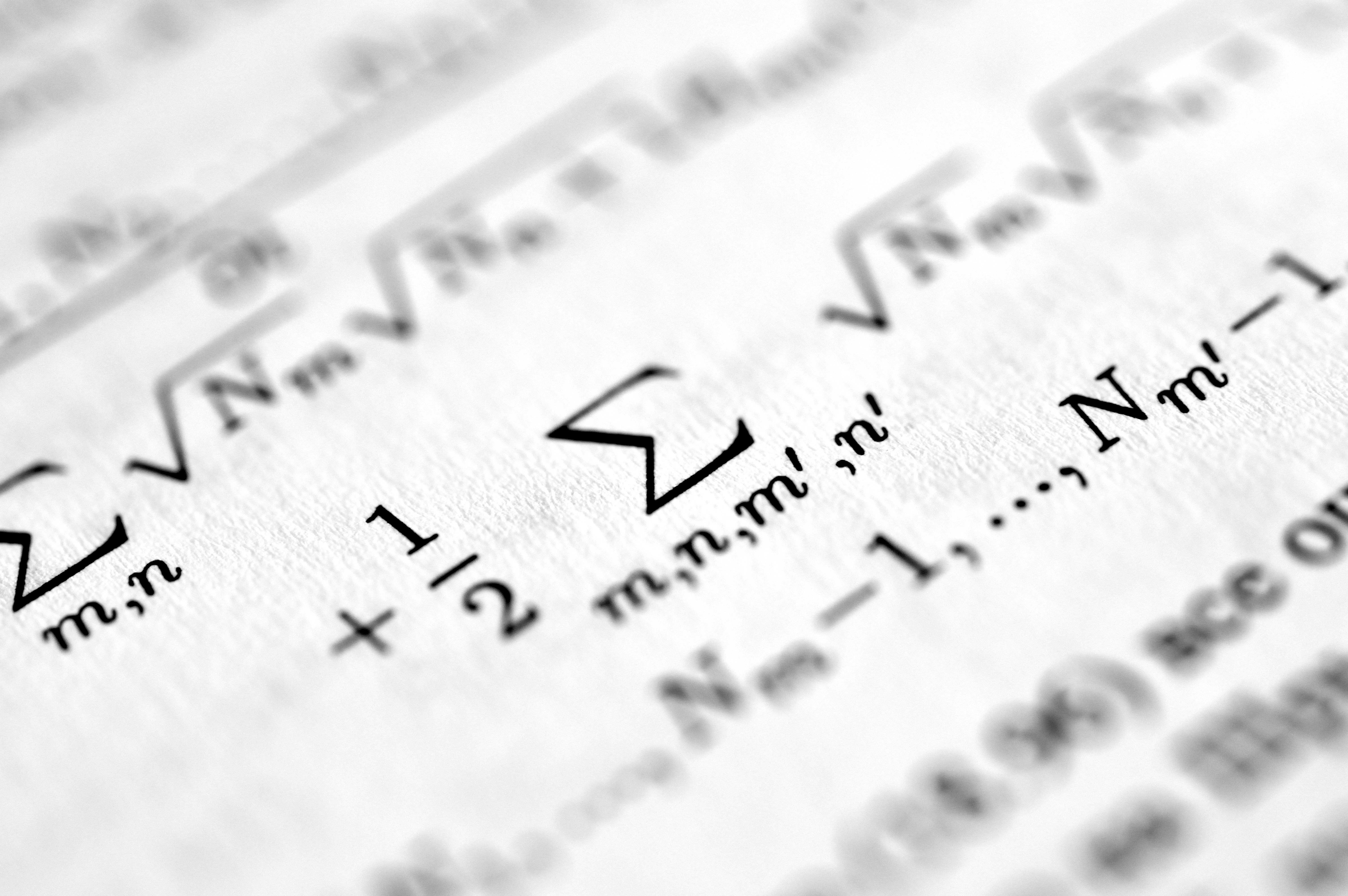
Descubre un marco matemático que redefine el conflicto en datos contextuales como objeto independiente. Ideal para modulación y análisis.