
Destilación On-Policy en Región de Confianza
TrOPD estabiliza la destilación on-policy en LLMs con regiones de confianza. Supera a OPD, EOPD y REOPOLD en razonamiento y código. ¡Descubre cómo!
TrOPD estabiliza la destilación on-policy en LLMs con regiones de confianza. Supera a OPD, EOPD y REOPOLD en razonamiento y código. ¡Descubre cómo!

Descubre cómo modernizar tus aplicaciones legacy para acceder desde cualquier lugar con seguridad zero trust. Q2BSTUDIO te guía en la transformación.

Descubre RDA, un agente basado en VLM que diseña recompensas semánticas para robots. Logra políticas alineadas con instrucciones humanas en manipulación.

Descubre cómo el aprendizaje por refuerzo inverso mejora la eficiencia de modelos de comportamiento robótico, logrando tasas de éxito superiores al 90% en tareas complejas de manipulación.
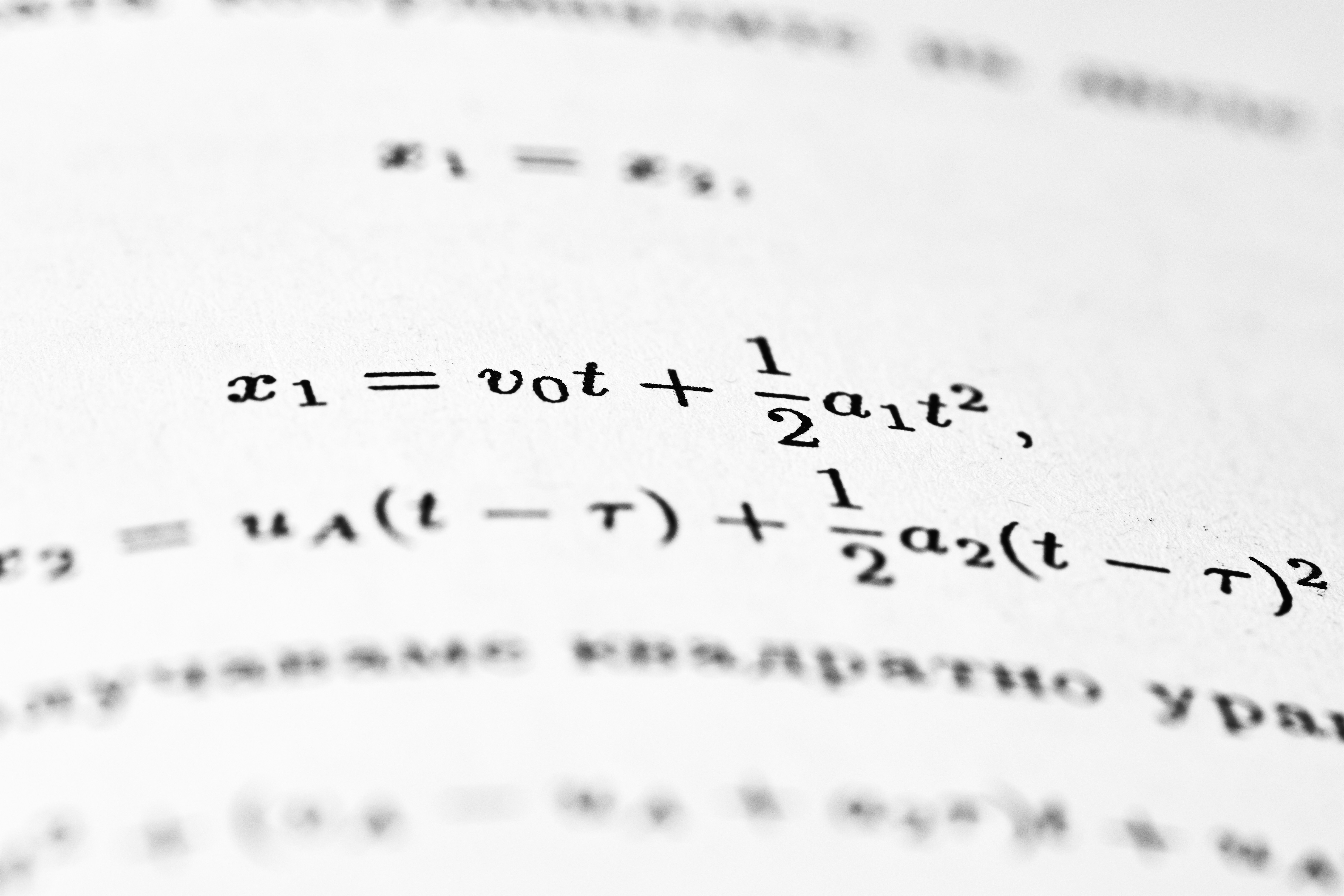
Descubre cómo la optimización bayesiana preferencial local supera limitaciones en alta dimensionalidad, reduciendo el arrepentimiento acumulativo en experimentos costosos.

Algoritmo optimista logra arrepentimiento minimax-óptimo en POMG. Complejidad O(√T) con dependencia de la dimensión de Eluder.

HALO estabiliza aprendizaje descentralizado en colaboración humano-robot mediante optimización de Lyapunov, mejorando generalización y robustez en casos extremos.

AffordGen genera datos diversos para manipulación robótica con generalización zero-shot. Aumenta la eficiencia del aprendizaje por imitación.

Políticas de orden adaptativo mejoran generación de secuencias en difusión enmascarada, superando heurísticas en tareas sensibles al orden como proteínas.

Descubre por qué auditar políticas casi óptimas en RL puede ser exponencialmente difícil. Analizamos cotas inferiores de consulta y la capacidad Rashomon.

Descubre cómo las regulaciones tecnológicas se transforman al aplicarse en sistemas reales, donde la implementación práctica revela desafíos ocultos.

Descubre qué es la soberanía industrial, los retos de Europa en energía y materiales críticos, y las claves para lograr autonomía tecnológica y digital.

Descubre el blindaje robusto para RL seguro. Garantiza seguridad en MDPs con transiciones inciertas mediante lógica temporal. Ideal para alta incertidumbre.

Descubre cómo las Políticas de Difusión Parametrizadas (PDP) transforman el ruido en control, adaptando comportamientos robóticos sin reentrenar el modelo. Resu

La administración Trump elimina orden ejecutiva de IA, desatando un conflicto interno. Ejecutivos y funcionarios buscan reconstruir la regulación. Descubre el impacto.

X-VPN completa auditoría independiente de no registros por una Big Four. Descubre cómo verifica su compromiso con tu privacidad en línea.

Descubre cómo las políticas de difusión parametrizadas permiten adaptar comportamientos robóticos sin reentrenar, mejorando la síntesis de nuevas conductas.

Nuevo método unifica incertidumbre epistémica y de modelo en RL offline. Optimización regularizada con creencia bayesiana híbrida.

Francia, EE.UU. y China logran soberanía en IA regulando su aprendizaje nacional. Modelo basado en aprendizaje centrado en humanos.

DIBS: clonación conductual desacoplada para generalización inductiva escalable en RL con entrenamiento estable y rendimiento zero-shot.