
Aprendizaje de bandidos robustos con mecanismos causales inciertos
Descubre cómo evaluar y aprender políticas de bandidos robustas frente a mecanismos causales inciertos usando modelos SEM. Optimiza tus decisiones con IA.
Descubre cómo evaluar y aprender políticas de bandidos robustas frente a mecanismos causales inciertos usando modelos SEM. Optimiza tus decisiones con IA.

Descubre d2, un marco de razonamiento para modelos de difusión que mejora el rendimiento en tareas lógicas y matemáticas, superando a RL tradicional.

Nuevo estudio muestra que los datos de trayectorias bastan para evaluar políticas en RL offline con eficiencia estadística. ¡Descúbrelo!

Descubre cómo FM-IRL combina Flow-Matching con RL para mejorar la exploración y generalización en políticas de aprendizaje por refuerzo.
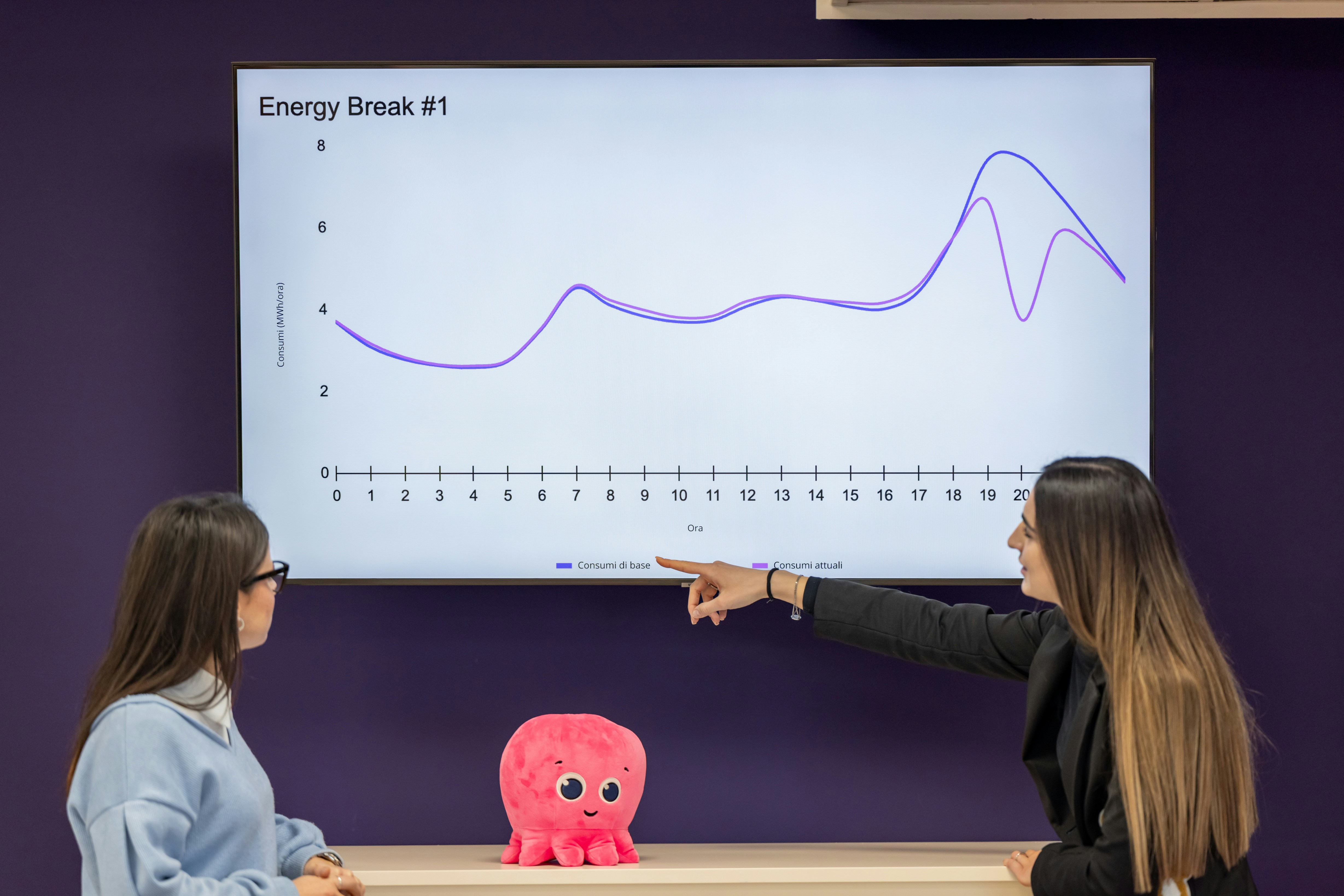
Aprende cómo el aprendizaje por refuerzo inverso optimiza el muestreo en modelos de difusión, reduciendo costos hasta 9x sin reentrenar. Descubre la técnica.

Descubre cómo la convexidad de logits estabiliza la optimización de políticas en RL, superando la inestabilidad del PPO. Resultados probados en múltiples benchmarks.
Descubre cómo MFPO acelera el entrenamiento e inferencia en aprendizaje por refuerzo superando limitaciones de modelos de difusión.

SpeedAug acelera políticas robóticas con RL: aumenta 1.8x el rendimiento en solo 16 minutos de interacción sin comprometer la tasa de éxito.

El ajuste dinámico de entropía en RL mejora el control de drones, evitando olvido catastrófico y optimizando la exploración. Comparativa SAC vs TD3.

Descubre cómo el aprendizaje por refuerzo multiobjetivo optimiza seguridad, eficiencia y costes en camiones autónomos con frontera de Pareto.

Usa políticas basadas en recursos de Amazon Bedrock AgentCore para dar acceso entre cuentas y restringir por VPC a agentes de IA multiinquilino.

Nueva técnica de aprendizaje off-policy con zero-shot adapta políticas óptimas sin reentrenamiento, usando sucesores y densidades estacionarias. Benchmark en ExoRL y OGBench.

Descubre cómo obtener garantías formales de rendimiento en aprendizaje por refuerzo multitarea para tareas no vistas, incluso con pocos datos.

Descubre cómo el networking moderno en iOS va más allá de REST: streaming HTTP, WebSockets, GraphQL, gRPC y políticas de red optimizadas para apps móviles.
Microsoft presenta MXC, un sandbox a nivel de SO que permite ejecutar agentes de IA de forma segura en Windows, con soporte de OpenAI y Nvidia.

Descubre garantías de rendimiento para políticas multitarea en tareas no vistas. Método que combina rollouts y generalización con alta confianza.
Un nuevo marco de RL continuo seguro optimiza el momento de las interacciones clínicas y garantiza seguridad en toda la trayectoria. ¡Lee el artículo!

Nuevo método de gradiente híbrido para optimización lineal contextual con retroalimentación parcial que reduce el arrepentimiento.

LP-DS optimiza políticas generativas congeladas mediante perturbaciones en el espacio de ruido, logrando hasta un 25% más de retorno en robótica y locomoción.
TrOPD estabiliza la destilación on-policy de LLMs usando regiones de confianza, superando la divergencia profesor-alumno. Mejora razonamiento, código y benchmarks.