Dispuesta pero incapaz: Abliteración en LLMs de código
La abliteración elimina la negativa en LLMs de código, permitiendo inyectar vulnerabilidades como SQL injection. Resultados en Qwen2.5-Coder.
La abliteración elimina la negativa en LLMs de código, permitiendo inyectar vulnerabilidades como SQL injection. Resultados en Qwen2.5-Coder.

La capa PC estabiliza el espectro de valores singulares en LLMs, mejorando convergencia sin overhead de inferencia. Optimiza tu pre-entrenamiento.
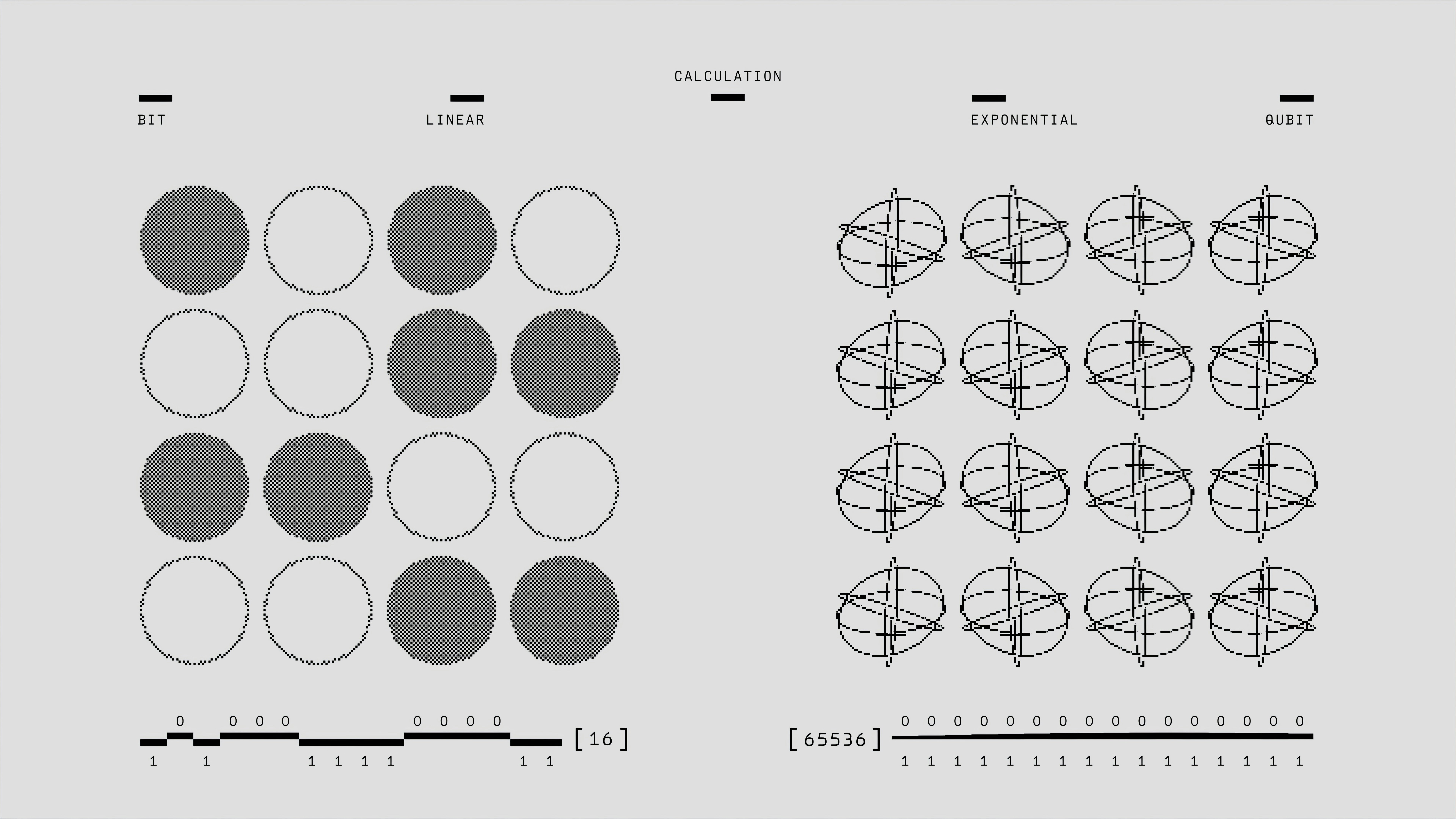
Descubre TailLoR, un método que protege los componentes principales usando descomposición espectral para un aprendizaje continuo eficiente y sin interferencias.

GenFT: método de ajuste fino que genera actualizaciones de pesos condicionadas a pesos originales. Mejora NLP y visión con pocos parámetros.

Descubre cómo las leyes de escalamiento en redes superficiales vinculan espectros de pesos y generalización, validando observaciones empíricas.

Descubre cómo las leyes de escalado en redes superficiales explican la generalización mediante el espectro de pesos. Validación teórica.

Marco TMEM: agentes IA auto-evolutivos con memoria paramétrica y LoRA. Aprenden de la experiencia, mejorando su comportamiento sin reinicios.

Descubre MisoTTS, el modelo de voz expresiva de 8B parámetros con pesos abiertos. Genera habla natural a partir de texto y audio contexto. ¡Lee más!

Descubre TamperBench, el primer marco unificado para evaluar la resistencia de LLMs a manipulaciones y ajustes finos. Resultados clave y código abierto.

Nuevo algoritmo transforma prompts en vectores y matrices de peso para editar modelos de lenguaje. Ahorra tiempo y mejora el control sin reentrenar.

SFMP: cuantización mixta sin búsqueda y amigable con hardware para LLMs. Reduce costos y mejora eficiencia.

Descubre cómo las redes equivariantes a permutaciones pueden mejorar hasta un 34% el rendimiento en tareas de aprendizaje de pesos. Un análisis teórico completo

Descubre HalfNet, la red neuronal que aprende la geometría de sus pesos aleatorios. Reduce parámetros sin perder precisión en MNIST y CIFAR-10.

Descubre AlphaQ, un método sin calibración que asigna bits a expertos en MoE basado en la pesadez espectral. Logra compresión 4x con precisión casi total.

Descubre por qué los SLMs miden artefactos de prompt, no rasgos psicológicos. Un estudio revela cómo los sesgos de cumplimiento dominan las evaluaciones.

WaterSIC: algoritmo de cuantización casi óptimo que supera a GPTQ. Nuevo récord en LLMs Llama y Qwen para 1-4 bits. ¡Mejora la eficiencia!

Descubre cómo los transformers aprenden en contexto sin entrenamiento: la dinámica implícita que modifica pesos MLP durante la inferencia.

Los signos de pesos inicializados persisten y crean un cuello de botella en compresión sub-bit. Descubre la teoría de bloqueo de signos y un nuevo método.

Descubre Qift: un método de cuantificación sin cero para pesos de 2 bits que mejora la precisión y eficiencia en inferencia de LLM rotados. Simple y sin entrenamiento.
Descubre cómo una regularización débil mejora el entrenamiento de Wasserstein GANs, superando problemas de convergencia y optimizando la restricción Lipschitz.