Percepción primero: modelo nativo de video para QA implícito
Descubre por qué la percepción visual supera al razonamiento en preguntas de video. Análisis del modelo Perception First para el desafío VRR 2026.
Descubre por qué la percepción visual supera al razonamiento en preguntas de video. Análisis del modelo Perception First para el desafío VRR 2026.

Descubre cómo HyperDet permite la detección de objetos 3D usando solo radar 4D, mejorando nubes de puntos ruidosas sin necesidad de LiDAR.
Med-Scout cura la ceguera geométrica de los MLLMs en diagnóstico médico mediante entrenamiento con refuerzo. Mejora percepción geométrica más del 40%.

El acento afecta la clonación de voz: clones de habla acentuada son menos similares pero más inteligibles. Estudio revela que preservar el acento es clave.

Una IA menos competente puede aumentar tu satisfacción laboral. Estudio revela impacto en percepción propia y de colegas en el trabajo.
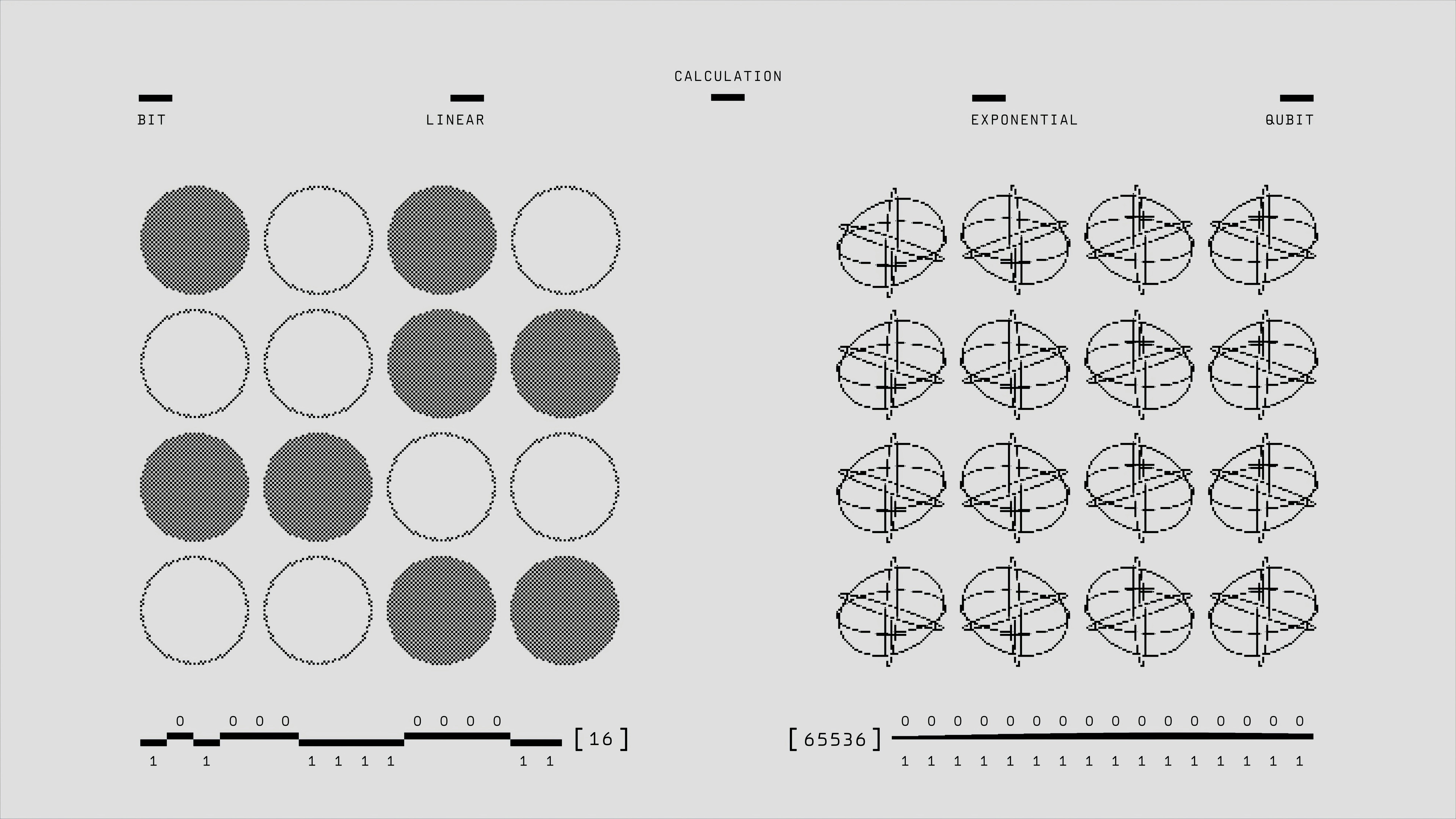
Los tokens latentes en modelos multimodales no almacenan memoria visual. Descubre cómo los marcadores de límite y formato generan las ganancias.

Descubre cómo PSG-Nav usa grafos de escena probabilísticos y decisiones multiverso para navegar en entornos abiertos con alta incertidumbre. Nuevo state-of-the-art en MP3D, HM3D, HSSD.

SkyShield es el primer benchmark de ocupación semántica front-view para drones a baja altitud. Mejora la seguridad con métricas dinámicas y alcanzabilidad.

Benchmarks de VLM en percepción urbana: confiabilidad y negociación. Estudio en Montreal muestra impacto de fiabilidad humana.

Reinterpreta umbrales de seguridad como disparos neuronales con SNN para alinear evaluación de riesgos con el frenado humano.

CHONN: redes de alto orden inspiradas en circuitos unifican dinámicas neuronales para resolver PDEs y mejorar percepción visual. Modelado estable y eficiente.

Descubre GSAM, un marco robótico que mejora un 36% la tasa de éxito en manipulación de objetos articulados, reduciendo colisiones. ¡Lee más!

Analizamos la relación entre información visual y comportamiento de conducción en modelos VLA mediante perturbaciones controladas. Implicaciones para sistemas más seguros.
ERGeoBench evalúa la geolocalización encarnada de modelos multimodales usando razonamiento espacial y percepción visual. Descubre sus limitaciones.
<meta name=description content=DynaFLIP presenta un enfoque innovador de percepción robótica utilizando dinámicas tri-modales para mejorar la interacción y el aprendizaje en entornos complejos. Descubre cómo esta tecnología impulsa la robótica avanzada.>
Descubre xModel-KD, un método de destilación de conocimiento intermodal que optimiza la percepción 3D con LiDAR para mejorar la precisión y eficiencia en visión por computadora.

Inserción de clavija en agujeros reales no vistos mediante simulación visual. Aprende esta técnica innovadora para ensamblaje preciso sin visión directa.
<meta content=Descubre si los agentes LLM pueden fundamentar sus acciones en estados ambientales con GroundAct. Análisis clave para la IA y robótica.>
<meta name=description content=Mejora el aprendizaje por refuerzo en 3D con segmentación semántica. Caso práctico en ViZDoom para optimizar el rendimiento de agentes.>
<meta content=Descubre el razonamiento audiovisual multi-salto con percepción omni-modal activa. Una innovadora técnica que integra múltiples sentidos para un análisis profundo y dinámico de la información.>