
Aprendizaje adaptativo ejecución paralela para localización eficiente de código
Descubre FuseSearch, con 84.7% F1 en archivos, 56.4% en funciones, 93.6% más rápido y 67% menos invocaciones.
Descubre FuseSearch, con 84.7% F1 en archivos, 56.4% en funciones, 93.6% más rápido y 67% menos invocaciones.

MAPL comprime activaciones en paralelismo de tubería con proyecciones ortogonales aprendidas, reduce comunicación sin pérdida de rendimiento en modelos LLaMA.

Descubre DiffAero, un marco de simulación diferenciable acelerado por GPU que acelera el aprendizaje de políticas de vuelo para drones. Entrena en horas con hardware convencional.

Descubre UltraEP, el primer balanceador de carga en tiempo real para MoE que logra un 94.3% del rendimiento ideal en entrenamiento e inferencia con 2560 GPUs.

Descubre cómo Attn-Sampler optimiza el muestreo en modelos de lenguaje de difusión, mejorando la calidad y el paralelismo. ¡Lee más!

Aprende a introducir la automatización de documentos legales sin interrupciones. Estrategias de pilotos, paralelismo y monitoreo para una transición fluida.

Descubre cómo E2LLM optimiza el despliegue de LLMs en entornos Edge/Fog, reduciendo el tiempo de espera en más del 50%.

Descubre cómo PipeDream logra convergencia en entrenamiento distribuido con un nuevo análisis teórico no convexo. Comparativa con LocalSGD.
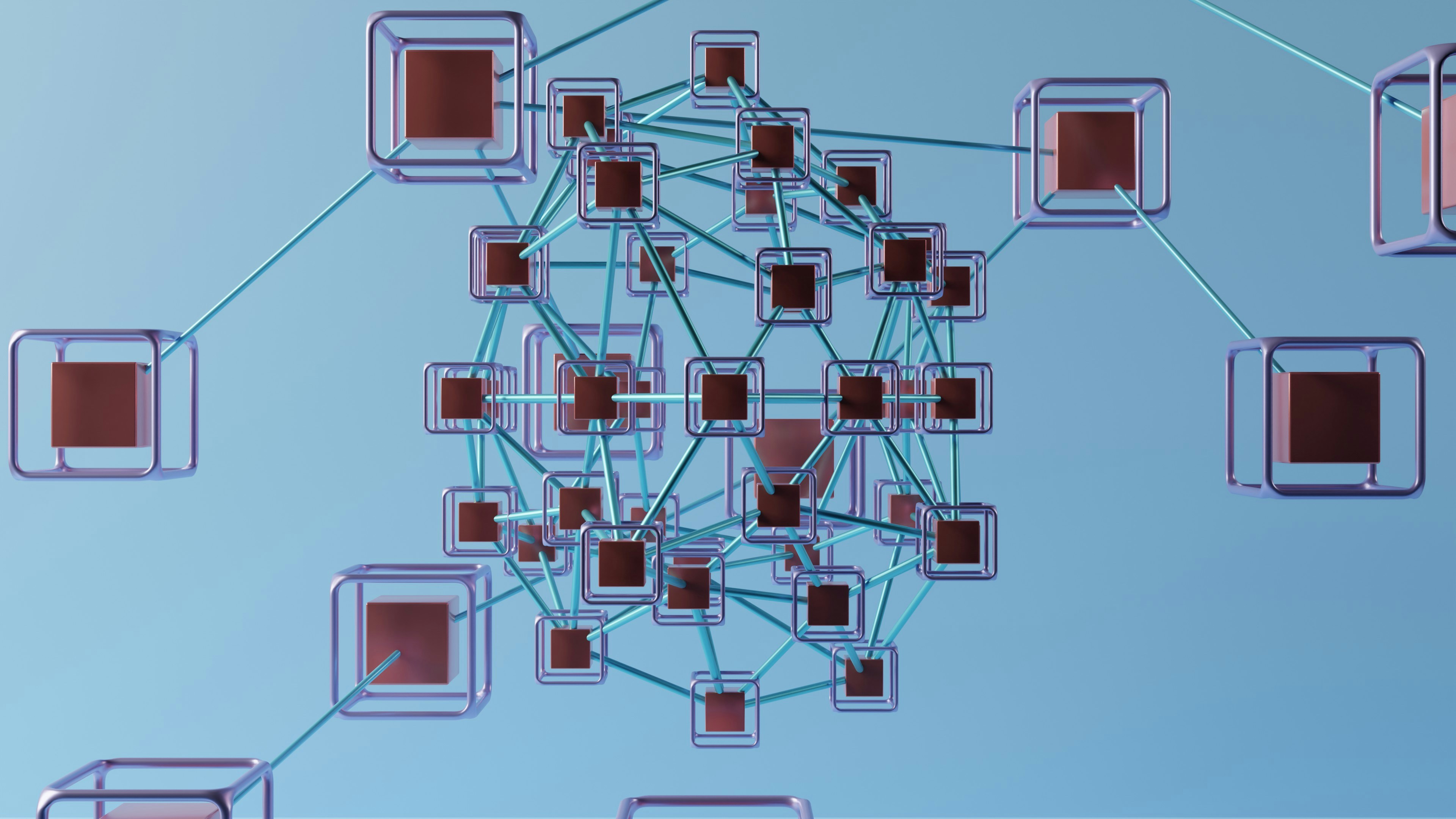
Descubre ParaBlock: una técnica innovadora que acelera el aprendizaje federado de grandes modelos de lenguaje al paralelizar comunicación y computación, manteniendo el rendimiento.

Descubre cómo codificar tareas factorizadas en SAT para mejorar la planificación. Analizamos estrategias que optimizan el rendimiento y el paralelismo.

Descubre cómo el Subnetwork Data Parallelism reduce el uso de memoria en un 28-60% al entrenar modelos de IA, manteniendo el rendimiento. ¡Optimiza tu entrenamiento distribuido!

Descubre APB-V: acelera la comprensión de videos largos en múltiples GPUs hasta 12.72x sin pérdida de rendimiento. Ideal para modelos multimodales.

Aprende cómo la partición cohesiva de tareas mejora el rendimiento en codificación multiagente: +14% aciertos, 2.1x velocidad, -35% costos.
Descubre cómo los kernels invariantes de árbol garantizan inferencia determinista con resultados bit a bit idénticos, eliminando el desajuste entre entrenamiento e inferencia en LLMs.
CA-AC-MPC: control predictivo basado en actor-crítico acelerado por CUDA para optimización en tiempo real de sistemas de control.
<meta content=Solucion eficiente de programacion lineal entera con templado paralelo. Optimizacion avanzada para problemas complejos.>
AMDP: paralelismo de tubería asíncrono y multidireccional para modelos a gran escala. Optimiza el entrenamiento de grandes modelos con esta técnica avanzada.
<meta name=description content=LaneRoPE es una innovadora codificación posicional que habilita el razonamiento paralelo colaborativo en modelos de lenguaje. Descubre cómo optimiza el procesamiento y mejora el rendimiento.>
DREAM-R: razonamiento especulativo multimodal con redacción por refuerzo, verificación precisa y paralelismo para inferencia eficiente.