
TWLA: Cuantización con pesos ternarios y activaciones de 4 bits
TWLA permite cuantizar LLMs a pesos ternarios y activaciones de 4 bits, reduciendo el costo de inferencia sin perder precisión.
TWLA permite cuantizar LLMs a pesos ternarios y activaciones de 4 bits, reduciendo el costo de inferencia sin perder precisión.

La geometría del espacio de parámetros no predice la interferencia al combinar adaptadores en LLMs. Análisis con DoRA-RBAC y benchmarks de QA.

Descubre Orthogonal Subspace Carving: enlace recursivo profundo con memoria constante. Supera TPR y VSA con eficiencia y fidelidad sin crecimiento exponencial.

Descubre Ortho-ReID, subespacios ortogonales de bajo rango para reidentificar personas con cambio de ropa. Supera en hasta un 5.9% a los mejores.

Rotate2Think mejora el razonamiento de modelos de lenguaje con rotación ortogonal. Aumenta precisión en matemáticas, ciencia y código sin entrenamiento.

Aprende cómo el problema de Procrustes restaura la correlación en datos sintéticos, preservando distribuciones y rendimiento.

Descubre cómo ExtraCare logra predicciones precisas y explicables en salud al descomponer representaciones de pacientes en componentes invariantes y covariantes. Ideal para la práctica clínica.

Descubre cómo las redes neuronales sheaf temporales mejoran la predicción de enlaces en grafos con evolución temporal, usando marcos ortogonales dinámicos y transporte local.

Descubre FOGO, un optimizador que previene el olvido en el entrenamiento de modelos de IA, mejorando la convergencia y retención sin almacenar datos. Ideal para aprendizaje continuo.

Descubre POET-X, el método que entrena LLMs de miles de millones de parámetros en una sola GPU H100 con menor memoria. ¡Optimiza tu entrenamiento!

Muon² reduce un 40% las iteraciones Newton-Schulz y ahorra hasta 25% del tiempo de entrenamiento. Descubre cómo.

Descubre cómo resolver el problema de factorización triple de matrices no negativas ortogonales simétricas con dos nuevos algoritmos heurísticos. Aplicaciones en clustering y redes.

Resuelve la factorización tri-matricial no negativa ortogonal simétrica. Algoritmos heurísticos para clustering y análisis de redes con resultados competitivos.

Descubre cómo PCA y Kernel PCA revelan la robustez de clústeres en aerolíneas, y por qué el silueta indica solo 3 grupos.

Descubre cómo PCA y Kernel PCA revelan la estructura oculta en los ciclos de ganancias de aerolíneas estadounidenses (1995-2020).
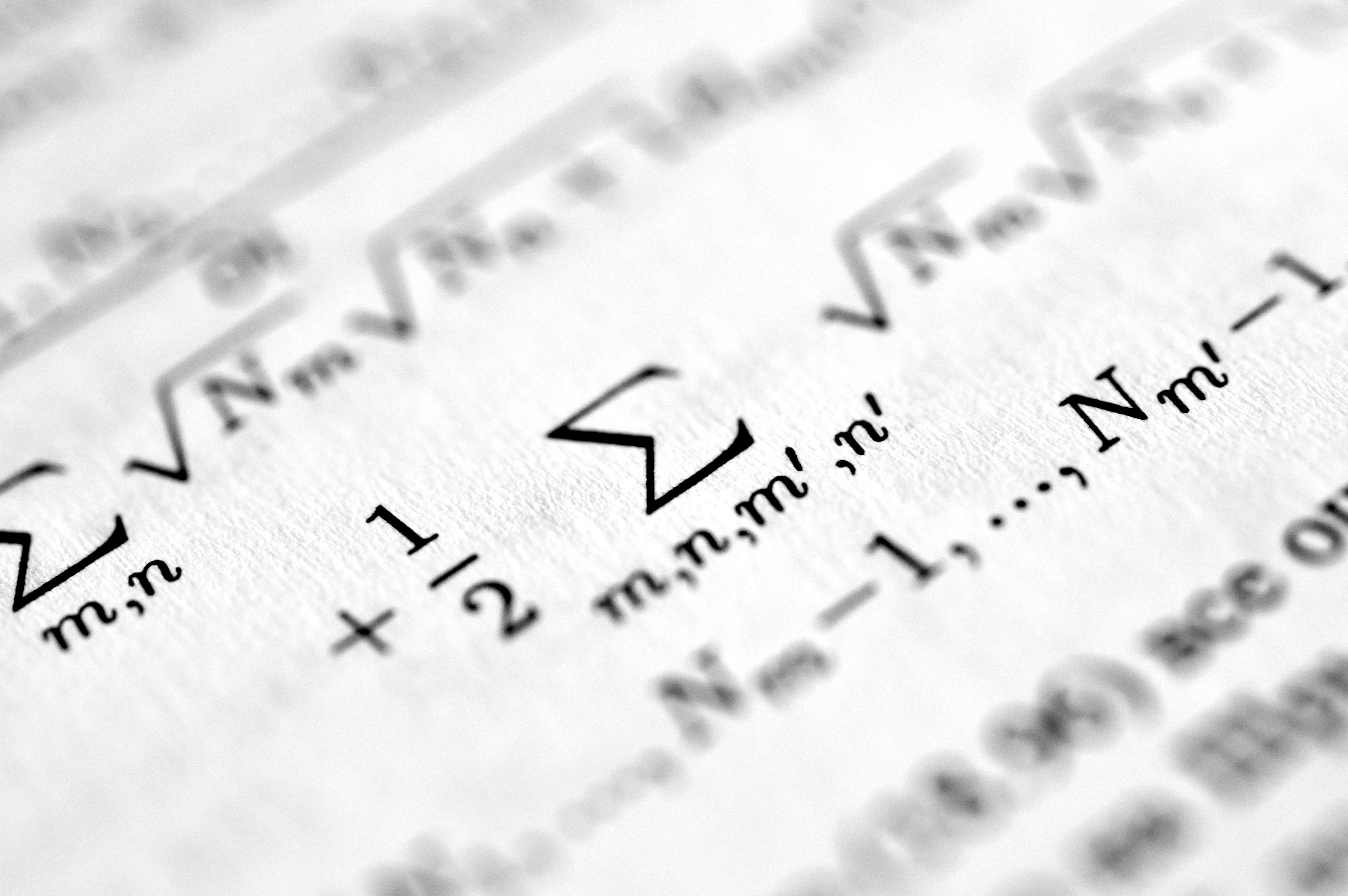
Descubre OptMuon, optimizador con momento ortogonalizado y control adaptativo en bucle cerrado. Logra tasas óptimas incluso sin ruido. Ideal deep learning.
Descubre cómo el POD multiescala con wavelet Morlet extrae modos energéticos de atención en transformers, revelando jerarquía de escalas sin anotaciones.

CascadeNet usa ML y Jacobiano para recuperar redes de influencia ocultas en datos en cascada, con validación en COVID-19.

ADIGen genera contrafactuales debiasados e invariantes automáticamente. Aprende cómo su robustez doble mejora la toma de decisiones bajo intervenciones complejas.

MAPL comprime activaciones en paralelismo de tubería con proyecciones ortogonales aprendidas, reduce comunicación sin pérdida de rendimiento en modelos LLaMA.