
POET-X: Entrenamiento eficiente de LLMs con transformaciones ortogonales
Descubre POET-X, el método que entrena LLMs de miles de millones de parámetros en una sola GPU H100 con menor memoria. ¡Optimiza tu entrenamiento!
Descubre POET-X, el método que entrena LLMs de miles de millones de parámetros en una sola GPU H100 con menor memoria. ¡Optimiza tu entrenamiento!

Muon² reduce un 40% las iteraciones Newton-Schulz y ahorra hasta 25% del tiempo de entrenamiento. Descubre cómo.

Descubre cómo resolver el problema de factorización triple de matrices no negativas ortogonales simétricas con dos nuevos algoritmos heurísticos. Aplicaciones en clustering y redes.

Resuelve la factorización tri-matricial no negativa ortogonal simétrica. Algoritmos heurísticos para clustering y análisis de redes con resultados competitivos.

Descubre cómo PCA y Kernel PCA revelan la robustez de clústeres en aerolíneas, y por qué el silueta indica solo 3 grupos.

Descubre cómo PCA y Kernel PCA revelan la estructura oculta en los ciclos de ganancias de aerolíneas estadounidenses (1995-2020).
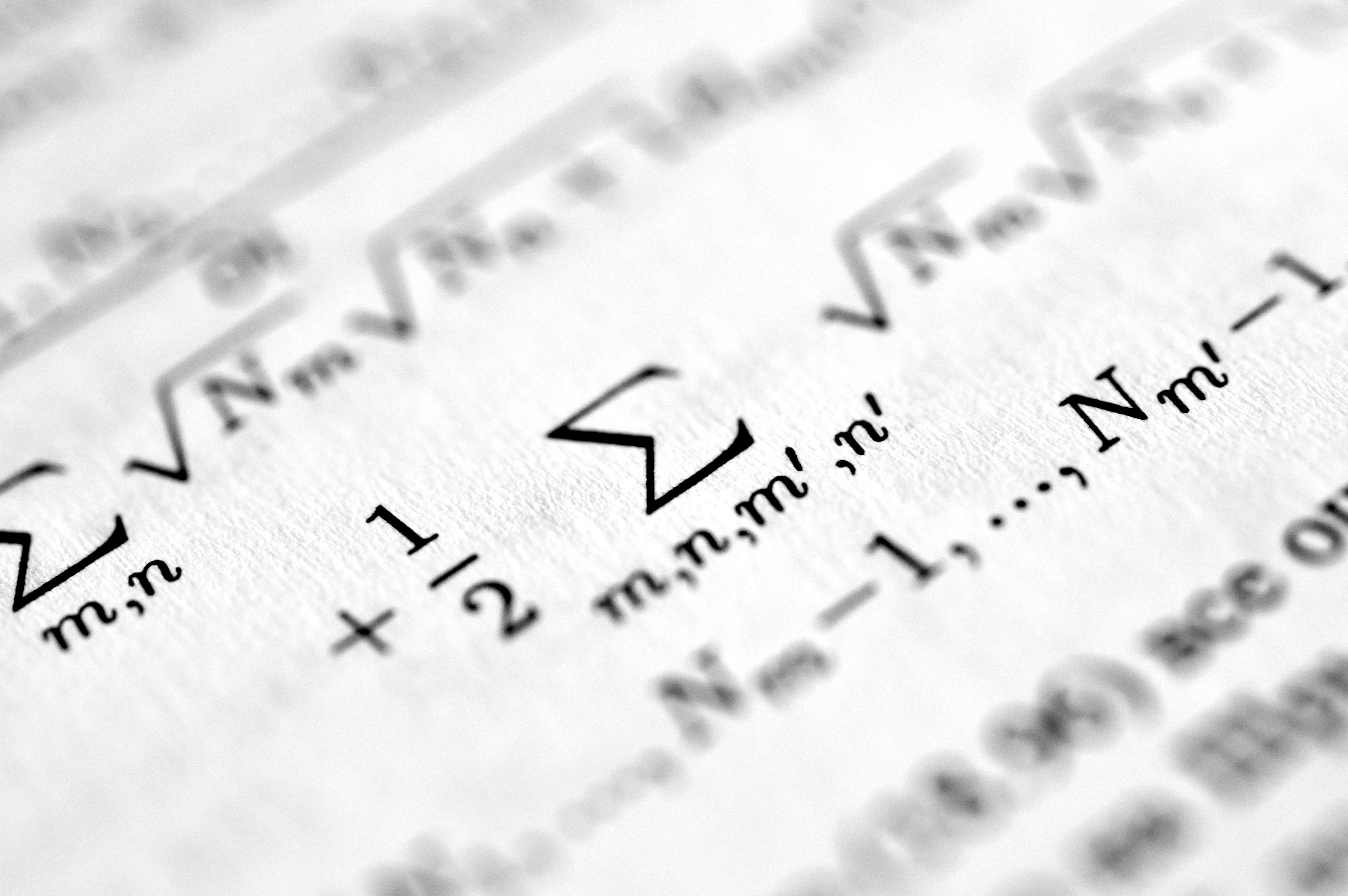
Descubre OptMuon, optimizador con momento ortogonalizado y control adaptativo en bucle cerrado. Logra tasas óptimas incluso sin ruido. Ideal deep learning.
Descubre cómo el POD multiescala con wavelet Morlet extrae modos energéticos de atención en transformers, revelando jerarquía de escalas sin anotaciones.

CascadeNet usa ML y Jacobiano para recuperar redes de influencia ocultas en datos en cascada, con validación en COVID-19.

ADIGen genera contrafactuales debiasados e invariantes automáticamente. Aprende cómo su robustez doble mejora la toma de decisiones bajo intervenciones complejas.

MAPL comprime activaciones en paralelismo de tubería con proyecciones ortogonales aprendidas, reduce comunicación sin pérdida de rendimiento en modelos LLaMA.

Descubre cómo un ataque de envenenamiento sigiloso en vectores de dirección puede burlar la seguridad de LLMs. Aprende sobre la defensa ortogonalización.

Descubre el nuevo LT-O-learner: un método ortogonal robusto para estimar efectos de tratamiento a largo plazo incluso con baja superposición. Ideal para marketing y medicina.

Descubre el colapso neuronal guiado por óptica mejora el aprendizaje incremental en SAR con pocos datos, logrando mayor precisión y menor olvido catastrófico.
Método innovador para inversión rápida de datos en procesos Ornstein-Uhlenbeck de alta dimensión, con mejor filtrado y estimación geofísica.

Clasificación interpretable de series temporales con AnchorMoE: transparencia ante-hoc sin post-hoc. Ideal para diagnóstico clínico y detección de fallos.
Una neurona de picos firmada basada en MTJ ortogonal logra 91% en CIFAR-10. Descubre cómo este avance impulsa la computación neuromórfica.

Descubre cómo el momento en Muon filtra el ruido del gradiente, mejorando el entrenamiento de LLMs. Un análisis teórico con respaldo experimental.
Descubre cómo la dimensión del modelo establece los límites geométricos para la representación de características en transformers, y cómo estimar la capacidad real de direcciones ortogonales.

Descubre cómo el nuevo método DCO alinea el manifold semántico en LLMs para reducir alucinaciones, mejorando la fidelidad contextual sin sacrificar conocimiento.