Análisis de supervivencia con Graph Mamba y ordenación topológica
Descubre cómo TopoMamSurv supera las limitaciones de Mamba en análisis de supervivencia con ordenación topológica y modelado bidireccional.
Descubre cómo TopoMamSurv supera las limitaciones de Mamba en análisis de supervivencia con ordenación topológica y modelado bidireccional.

Descubre cómo anotaciones verificadas revelan que ~39% de FOLIO y MALLS son incorrectos. Un marco LLM reduce el esfuerzo de reetiquetado humano.

Descubre GRZO, el optimizador que reduce la varianza en el ajuste fino de LLMs, mejorando precisión y ahorrando memoria GPU.

Estudio revela que el reordenamiento con LLM puede amplificar contenido extremo, pero una regularización ligera mejora la diversidad ideológica.

Descubre cómo las redes neuronales simplécticas preservan la estructura hamiltoniana en modelos reducidos, logrando simulaciones precisas y estables a largo plazo.

Trump firma orden ejecutiva que crea un marco voluntario para revisar modelos de IA antes de su lanzamiento, buscando equilibrar innovación y ciberseguridad.

Trump firma orden ejecutiva de IA que permite al gobierno revisar modelos y seleccionar socios de confianza. Expertos alertan sobre favoritismo.

Descubre cómo la truncación balanceada con cuadratura Hermite simétrica permite aprender sistemas dinámicos lineales a partir de datos de derivadas, preservando estabilidad y hermiticidad.

Descubre R3-CoVR, un marco zero-shot sin entrenamiento que alcanza 91.9% R@1 en recuperación de videos compuestos mediante razonamiento multimodal y reordenamiento.

Descubre cómo la supervisión de segundo orden mejora el aprendizaje de sistemas caóticos, preservando atractores con bajo costo computacional.

Descubre cómo extraer relaciones estáticas no lineales de datos no etiquetados con autoencoder de varianza ordenada. Ideal para optimización en tiempo real.

Descubre la profundidad polar, una nueva métrica para ordenar extremos en datos de cola pesada y detectar anomalías multivariantes. Aplicaciones en ciberseguridad y análisis de riesgos.

Descubre d2, un marco de razonamiento para modelos de difusión que mejora el rendimiento en tareas lógicas y matemáticas, superando a RL tradicional.

Descubre RO-HNN: combina mecánica hamiltoniana y reducción de orden para aprender dinámicas complejas a gran escala con predicciones consistentes.
Los modelos de recompensa en IA tienen sesgos. La recompensa mecánica los mitiga con pocos datos. Optimiza la alineación de modelos de lenguaje.

Políticas de orden adaptativo mejoran generación de secuencias en difusión enmascarada, superando heurísticas en tareas sensibles al orden como proteínas.

EST-PRM pone a prueba la estabilidad de los modelos de recompensa de proceso ante transformaciones que distorsionan la calibración de recompensas.

Descubre cómo las simetrías en el espacio de pesos facilitan la estimación de la curvatura en redes neuronales, mejorando la optimización y reduciendo costos computacionales.
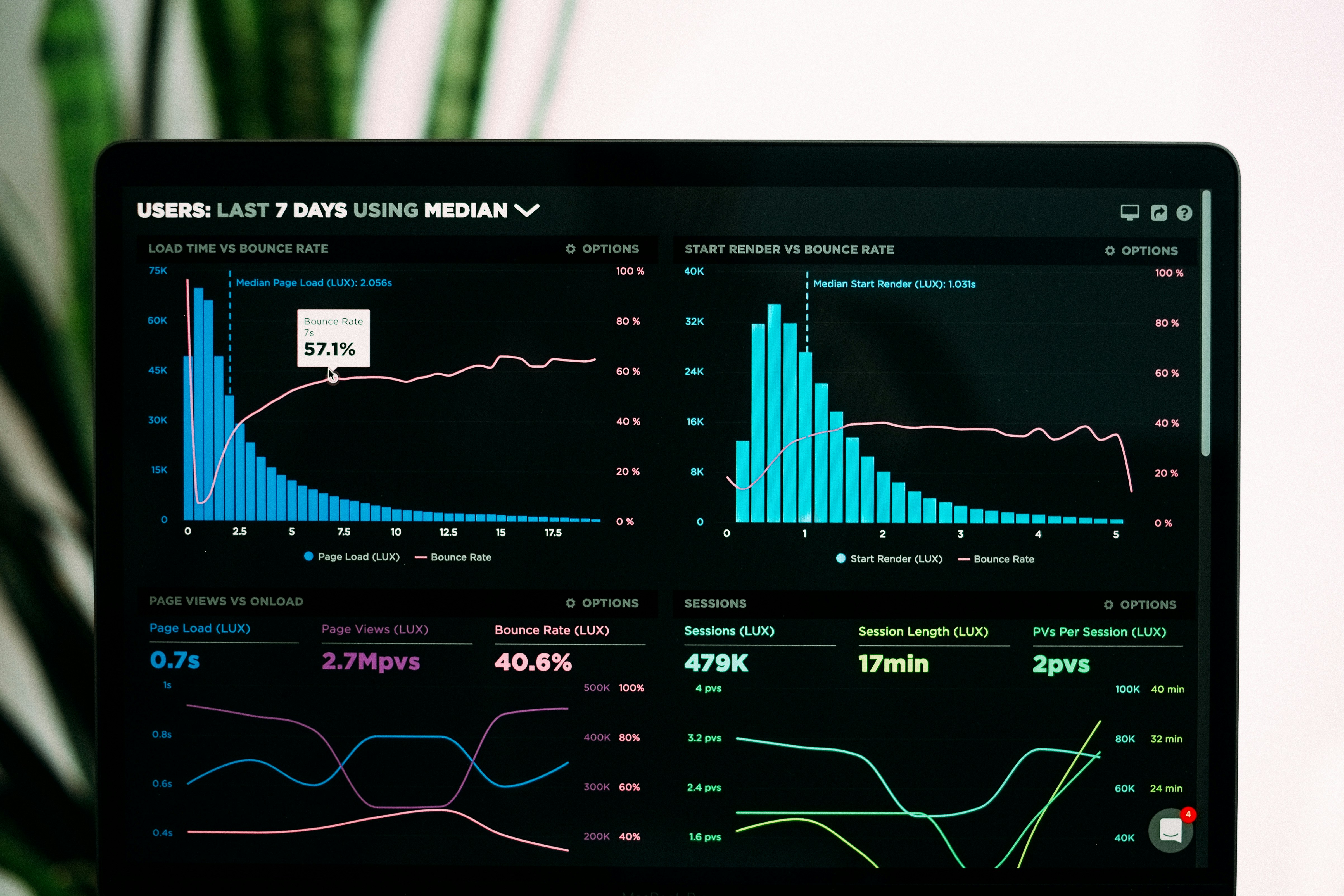
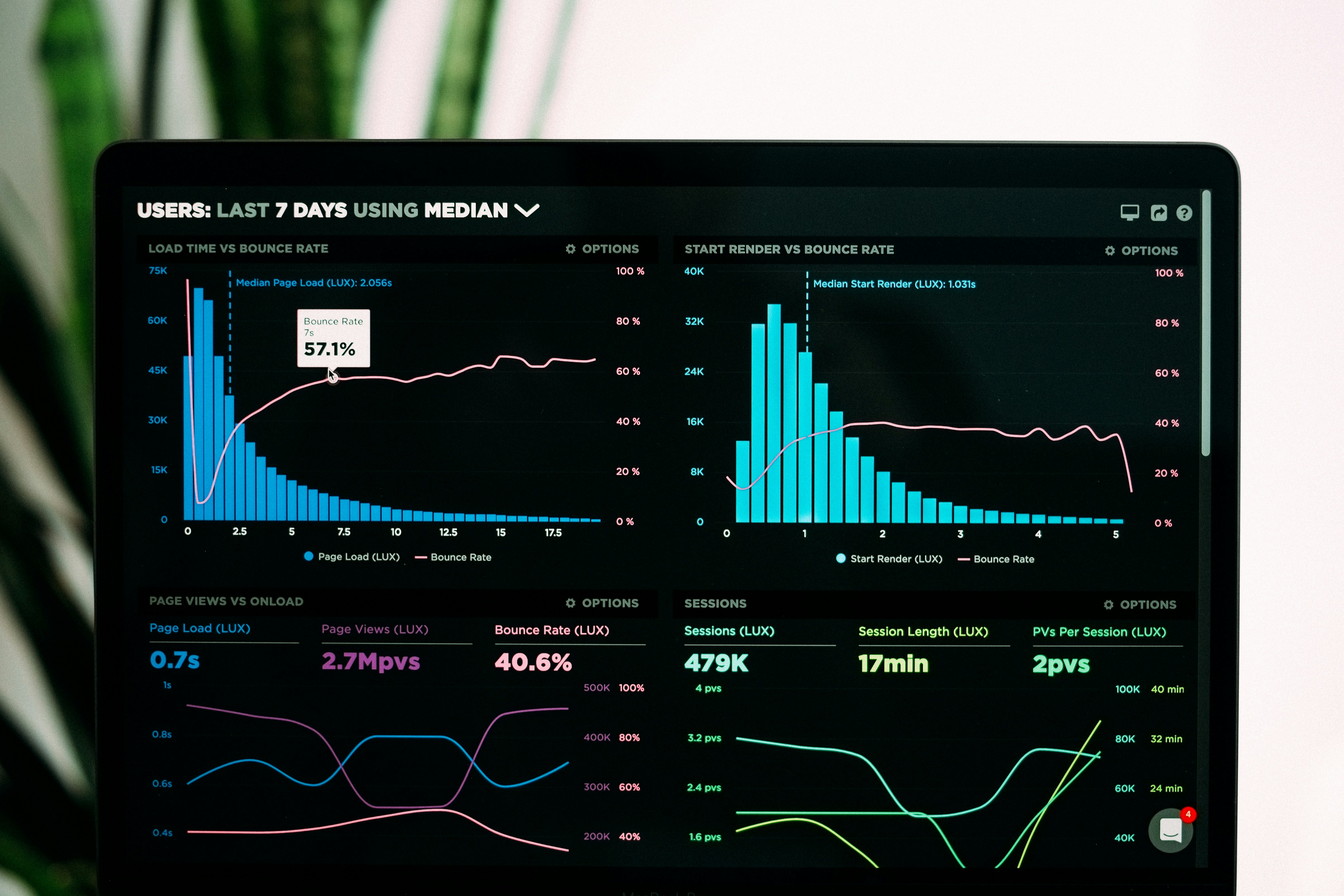
Descubre cómo las consultas pushdown reducen la latencia de API hasta 5x y el consumo de memoria 160x frente al filtrado en memoria. Resultados de benchmark.

La administración Trump elimina orden ejecutiva de IA, desatando un conflicto interno. Ejecutivos y funcionarios buscan reconstruir la regulación. Descubre el impacto.