
Still: Compactación del Caché KV en una Sola Pasada Directa
Still comprime el caché KV en una sola pasada, reduciendo memoria en modelos de lenguaje sin perder calidad. Ideal para contextos largos.
Still comprime el caché KV en una sola pasada, reduciendo memoria en modelos de lenguaje sin perder calidad. Ideal para contextos largos.

Descubre FlashCP, el paralelismo de contexto que acelera hasta 1.63x el entrenamiento de LLM con carga balanceada y comunicación eficiente.

Aprende a entrenar un MoE de 120B parámetros en un solo nodo GPU usando escalado reversible y cuantización. Optimiza memoria y alcanza pérdida de 1.78.

Optimiza el uso de memoria en LLMs con PolarQuant. Esta técnica de cuantificación polar acelera la decodificación al transformar claves en coordenadas polares.

Descubre las claves para optimizar la memoria de agentes IA en cargas de largo plazo. Caracterización, implicaciones de sistema y 10 recomendaciones.
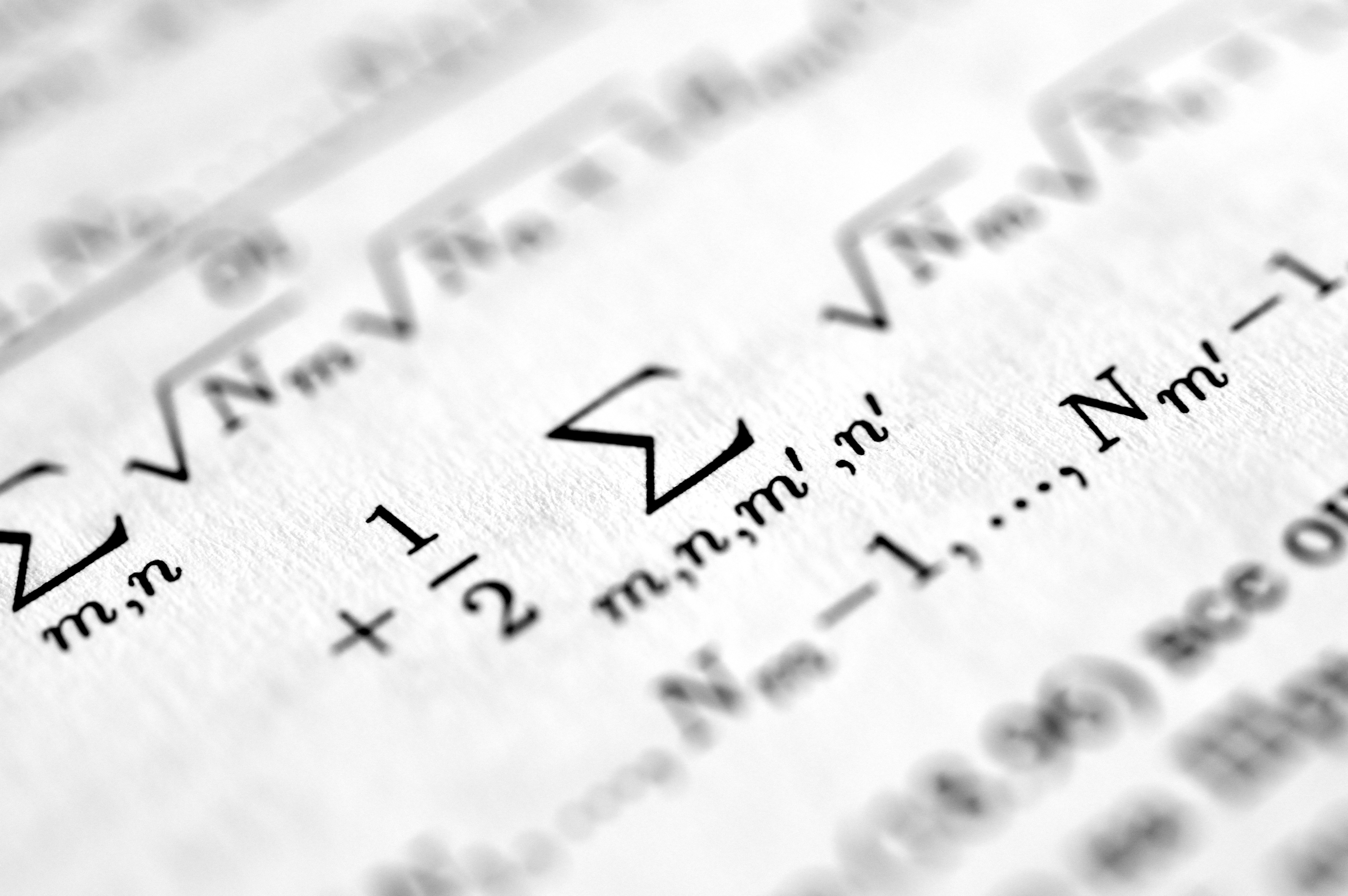
Optimiza tus modelos de lenguaje con CMPQ: cuantización de precisión mixta por canal que ahorra memoria y mejora el rendimiento en dispositivos edge.

Aumenta la tasa de éxito de agentes de software en un 5.25% con optimización de memoria en bucle cerrado.

Descubre LiftQuant: cuantización continua de LLM que permite comprimir modelos de 70B a tan solo 2.4 bits, ajustándose perfectamente a tu memoria GPU.

¿Error java.lang.OutOfMemoryError? Aprende cómo solucionar el límite de overhead del GC ajustando el heap y usando profiling. Guía paso a paso.

Descubre InfoMem, un mecanismo de recompensa que evalúa la utilidad de la memoria final para mejorar el rendimiento de los LLM en tareas de largo contexto.

Descubre MeSP: reduce un 49% la memoria al ajustar LLMs en dispositivos, con gradientes exactos. Ideal para entrenamiento privado.

Optimiza LLMs con GradMem: escribe contexto en memoria mediante descenso de gradiente en tiempo de prueba, reduciendo la necesidad de grandes cachés.

ForesightKV optimiza la evicción de caché KV en modelos de razonamiento, superando métodos previos con la mitad del presupuesto y aprendizaje combinado.

Descubre cómo LRAgent comparte eficientemente la caché KV entre agentes Multi-LoRA, reduciendo memoria y cómputo sin perder precisión. ¡Optimiza tus LLMs!

MomentKV mejora la eficiencia de inferencia larga cerrando la brecha direccional en el desalojo de cache KV, reduciendo errores y permitiendo mayor compresión.
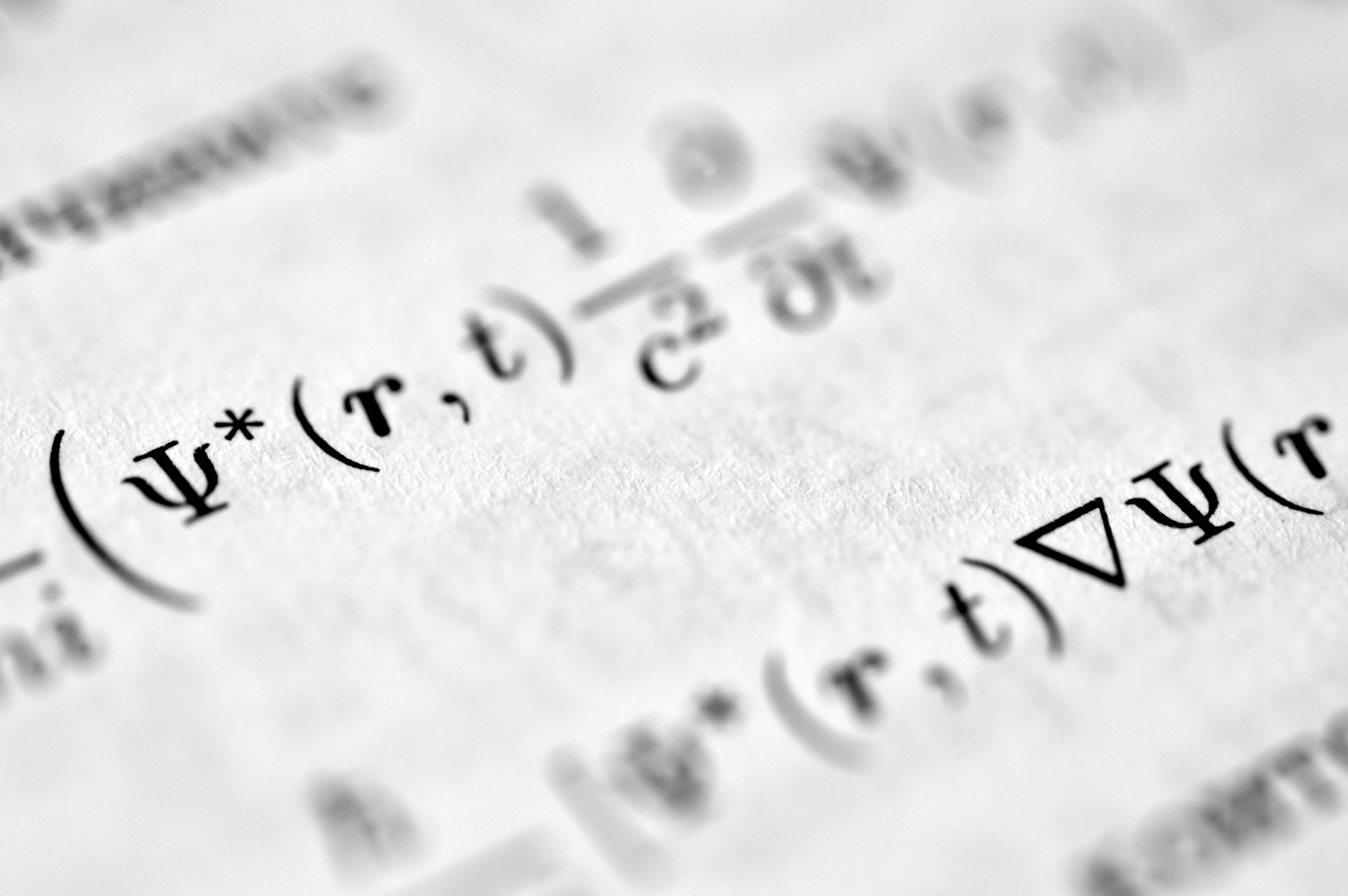
BitsMoE asigna bits inteligentemente en MoE LLM, logrando cuantización 2 bits con 27.83% más precisión, 12.3x más rápida y 1.76x más velocidad.

Descubre BudgetDraft: entrenamiento multi-vista acelera decodificación especulativa con KV disperso hasta 6.55x en contextos de 4K a 16K, optimizando memoria.

Con HASTE, el entrenamiento disperso dinámico consciente del hardware logra hasta 25x de aceleración en backpropagation para clasificación multi-etiqueta extrema.