
Entrenamiento convexo de redes superficiales regularizadas con Lipschitz
Aprende a entrenar redes neuronales superficiales con regularización Lipschitz usando optimización convexa para mayor robustez y precisión.
Aprende a entrenar redes neuronales superficiales con regularización Lipschitz usando optimización convexa para mayor robustez y precisión.

Explora cómo combinar propiedades en abducción ABox bajo semántica de reparación no incrementa la complejidad. Optimiza hipótesis con múltiples criterios.

Aprende cómo QueryMarket y OVBAL permiten comprar datos de forma inteligente bajo presupuesto, maximizando el rendimiento del modelo en streams dinámicos.

Descubre QueryMarket y OVBAL, un marco que optimiza la compra de datos en flujos no estacionarios, maximizando la utilidad bajo restricciones de presupuesto.
Descubre cómo optimizar la densidad propuesta en métodos Monte Carlo para mejorar el rendimiento en aprendizaje automático, inferencia bayesiana y más.
Descubre AIQI, el primer agente de IA universal sin modelo que logra optimalidad asintótica en aprendizaje por refuerzo general. Un avance revolucionario.

Descubre AIQI, el primer agente de IA universal sin modelo que demuestra optimalidad asintótica en aprendizaje por refuerzo general. ¡Revoluciona la IA!
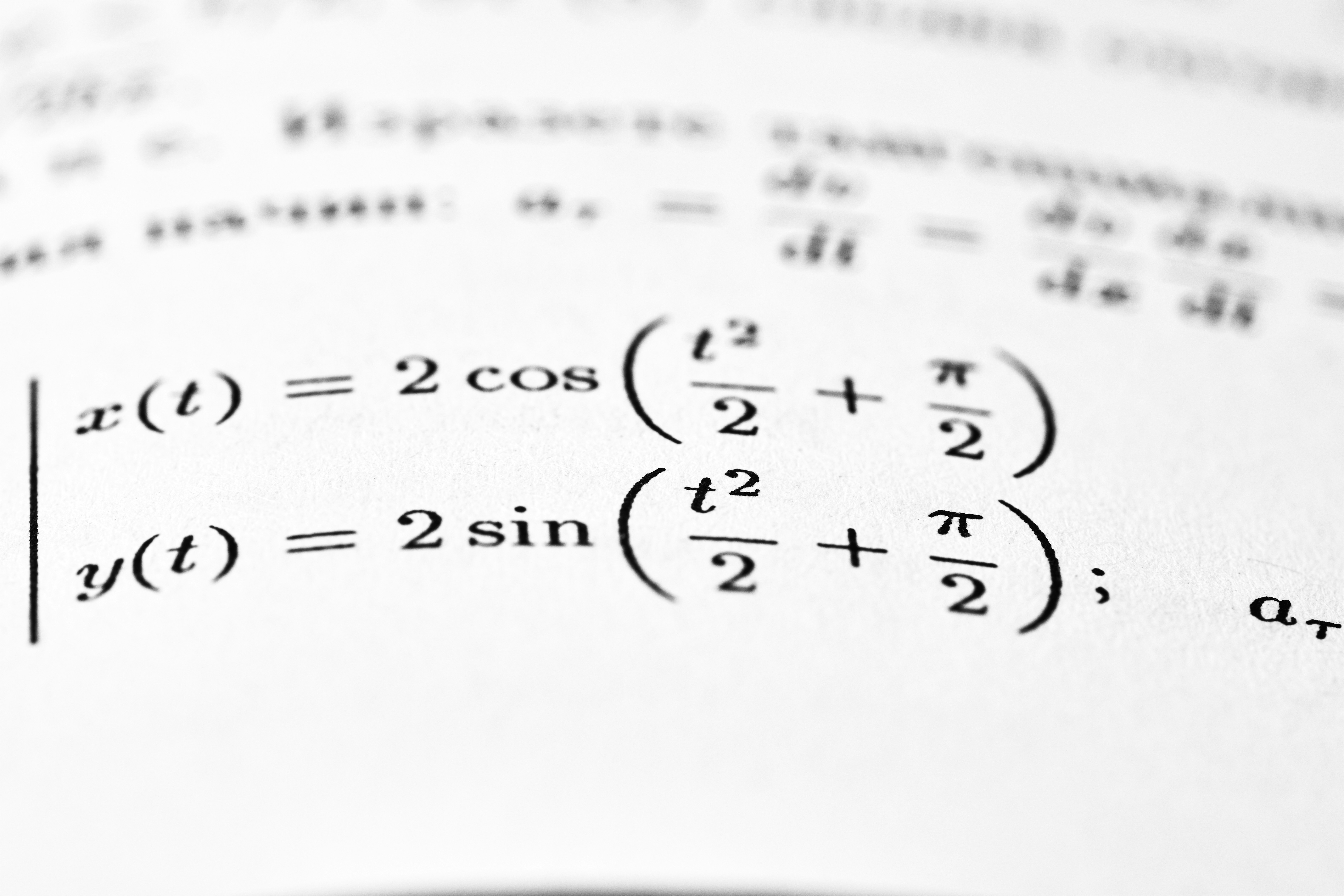
Descubre cómo un método cuasi-Bayes secuencial resuelve el problema de decisión compuesta de Poisson en streaming, con eficiencia y garantías de optimalidad.

Descubre un mecanismo neuronal que maximiza la utilidad del sistema manteniendo la equidad dinámica en la asignación de múltiples recursos con demanda secuencia

Los tokens FSQ son óptimos para difusión continua en datos categóricos. Este estudio demuestra que superan a modelos LLM en TTS siendo más pequeños y rápidos.
Descubre cómo la predicción parcialmente performativa aborda cambios de distribución endógenos y exógenos en modelos predictivos. Aprende heurísticas prácticas para adaptarte.

Un algoritmo de Thompson Sampling no paramétrico logra optimalidad asintótica en bandidos aversos al riesgo con recompensas subgaussianas.

Descubre cómo mejorar la optimización convexa estocástica cuando se desconocen parámetros clave. Métodos para evitar sobreajuste y lograr complejidad de muestreo óptima.

Descubre cómo Bucket-Level MOO resuelve conflictos de gradientes en el ajuste fino multilingüe, mejorando el rendimiento de los LLMs en múltiples idiomas.