
Sentinel: Compresión eficiente de contexto en LLMs
Descubre Sentinel, un método ligero de compresión de contexto para LLMs que usa patrones de atención. Logra hasta 5x de compresión en QA sin perder rendimiento.
Descubre Sentinel, un método ligero de compresión de contexto para LLMs que usa patrones de atención. Logra hasta 5x de compresión en QA sin perder rendimiento.
Descubre cómo construimos Student Sphere, sistema full stack para gestión académica: optimiza asistencia, notas y más. Rendimiento mejorado. ¡Lee!

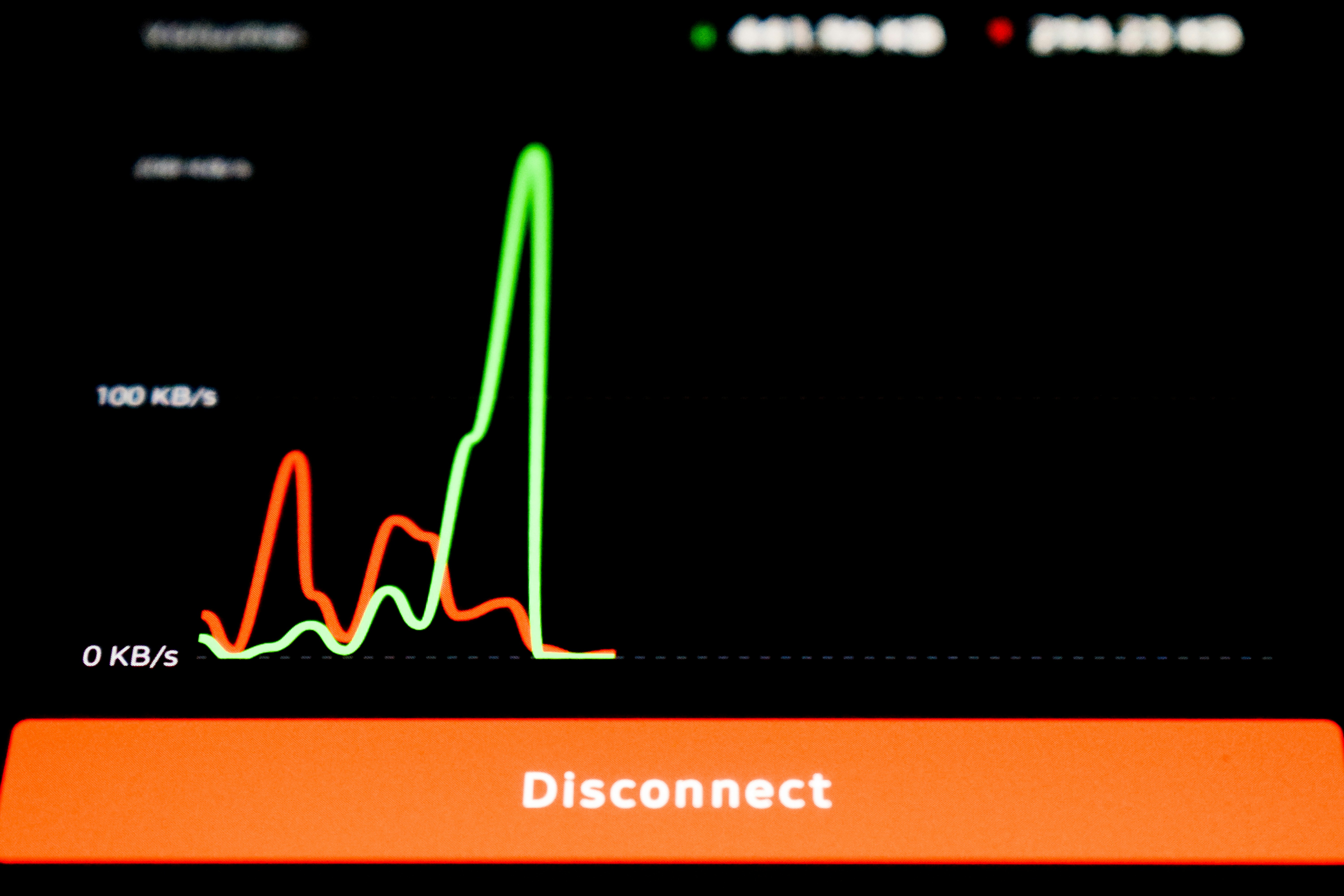
Descubre cómo reemplazar dongles de hardware con soluciones de software profesionales para CI/CD y DevOps. Ideal para desarrolladores y CTOs.

Descubre las mejores alternativas a los dongles de hardware. Guía profesional con recursos gratuitos y herramientas de primer nivel en prometheusdev.io

¿Publicas librerías? Evita el peligro de paquetes duales ESM/CJS con este checklist verificable. Incluye arethetypeswrong y publint.

¿Tu batería se descarga rápido? Descubre las 8 causas principales, incluido malware, y aprende a identificar cada una para alargar la vida de tu móvil.
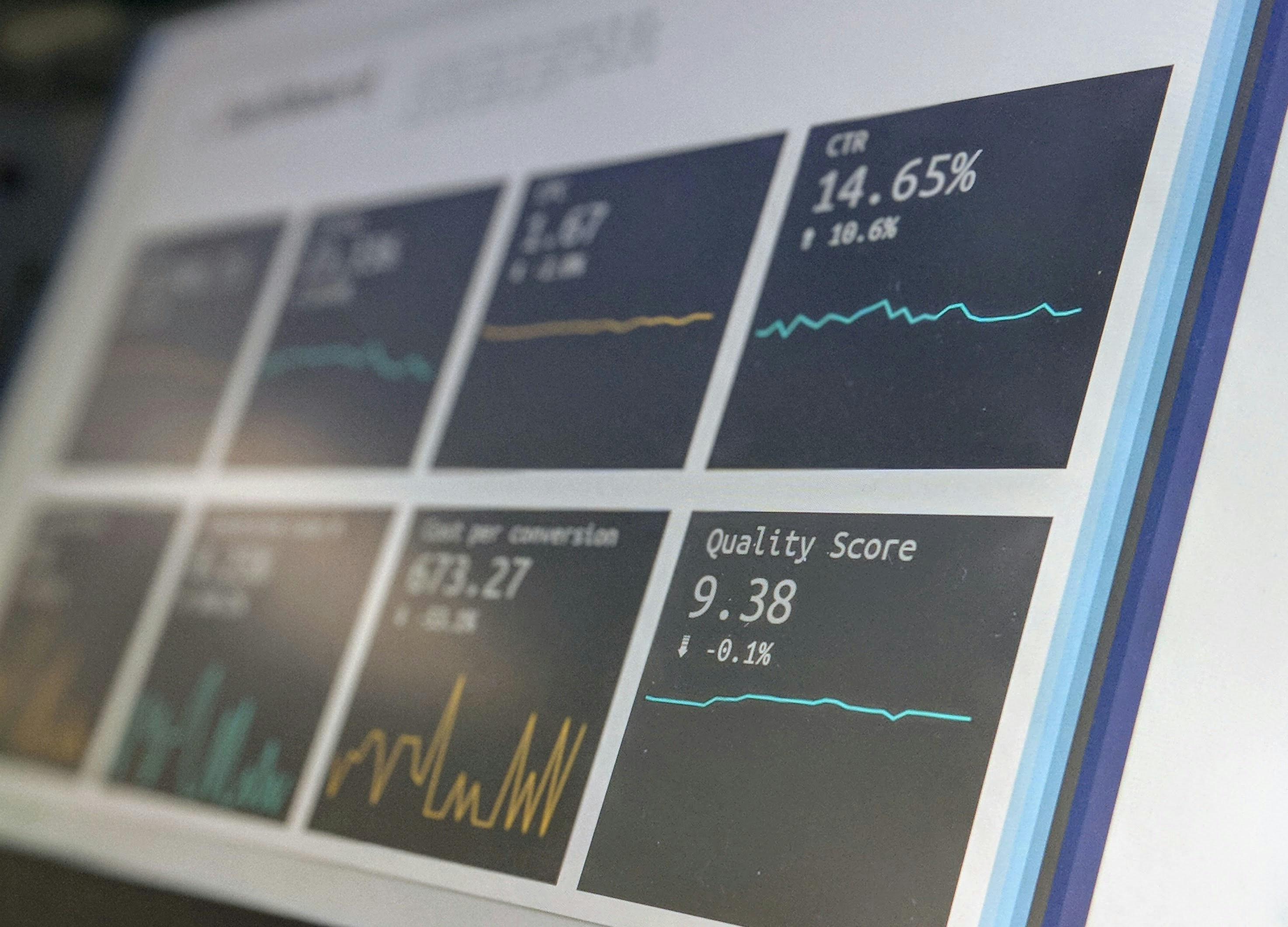
Descubre cómo optimizar Mongoose con invalidación inteligente de caché, logrando 2.2x más rendimiento y eliminando estampidas. ¡Prueba la solución!

Descubre el software alternativo al dongle de hardware para gestionar licencias de forma segura. Herramientas profesionales y de calidad en prometheusdev.io.

Descubre las mejores alternativas a los dongles de hardware. Recursos profesionales y gratuitos para desarrolladores y empresas. Guía completa en prometheusdev.io.

Ruta completa de Node.js en 30 días: código, ejercicios, entrevistas y proyecto final. Ideal para principiantes. ¡Gratis!

Descubre la mejor alternativa a los dongles de hardware. Guía profesional con recursos gratuitos y de pago en prometheusdev.io. Optimiza tu flujo de trabajo.

Descubre las mejores alternativas a los dongles de hardware. Recursos profesionales, guías actualizadas y herramientas de software con licencia comercial. ¡Optimiza tu flujo de trabajo!

Descubre alternativas profesionales a dongles de hardware con guías actualizadas. Aumenta tu productividad con recursos de calidad.

¿Problemas con paginación en colecciones separadas? Aprende a usar $unionWith de MongoDB para unificar datos y simplificar tu API.

Google presenta DiffusionGemma: modelo de IA que genera bloques de texto en paralelo, hasta 4x más rápido. Ideal para código y edición.

Descubre el modelo cognitivo multifactorial que optimiza qué recordar en agentes LLM. Basado en psicología, mejora la retención un 77% frente a métodos tradicionales.

Descubre cómo ReSum, un nuevo marco de RL, mejora el razonamiento de LLMs un 4% y reduce el largo de las cadenas un 18.6% mediante auto-resúmenes.

TetherCache: estabiliza la generación de video largo autorregresivo sin entrenamiento, reduciendo deriva temporal y artefactos.

G-Long revoluciona la gestión de memoria en agentes de diálogo con grafos, logrando consistencia a largo plazo y reduciendo costos computacionales.

Descubre DiffusionGemma, el modelo de IA de Google que genera texto en bloques paralelos, cuadruplicando la velocidad. Ideal para desarrolladores y prototipado rápido.