
David vs. Goliat: Argmax contra LSTM, Transformer y LLM
¿Puede un simple conteo superar a LSTM, Transformer y LLM? Nuestro benchmark revela resultados sorprendentes.
¿Puede un simple conteo superar a LSTM, Transformer y LLM? Nuestro benchmark revela resultados sorprendentes.

¿Quieres reducir memoria en modelos MoE sin perder rendimiento? Descubre un principio de selección unificado que mejora hasta 8.8 puntos en benchmarks.
Descubre cómo UL4M4 imputa embeddings faltantes en aprendizaje multimodal mediante clustering no supervisado, logrando F1 >0.7 incluso con >50% de datos
Las redes bayesianas con incrustación temporal latente (BN-LTE) modelan la progresión del Alzheimer y detectan ventanas de sensibilidad amiloide.

Mejora la eficiencia de modelos de difusión discretos con decodificación paralela de campo medio. Coordina actualizaciones para generar más tokens por paso sin

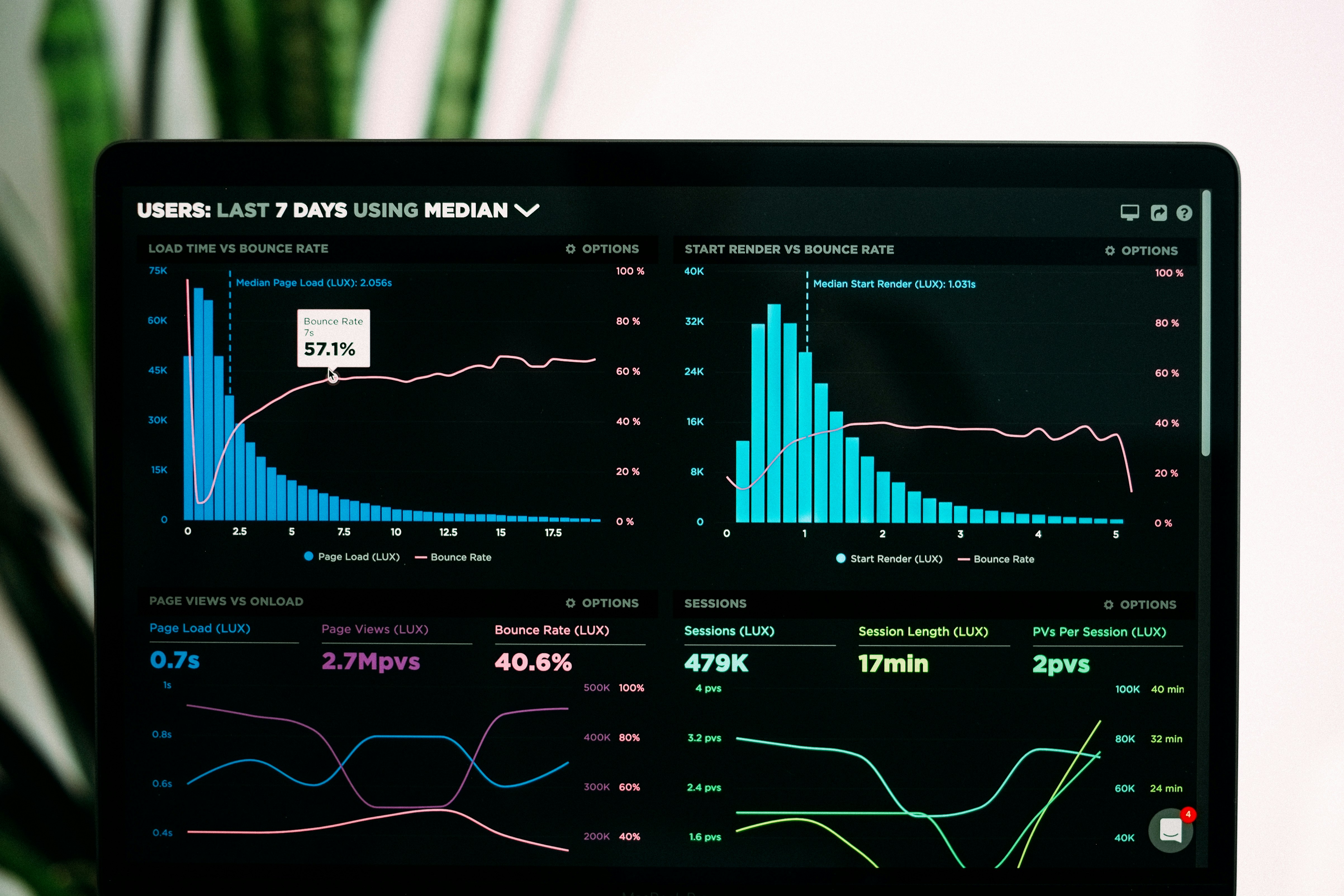
¿Un simple contador supera a modelos de IA? Este benchmark revela que argmax iguala o supera a LSTM, Transformer y LLMs.
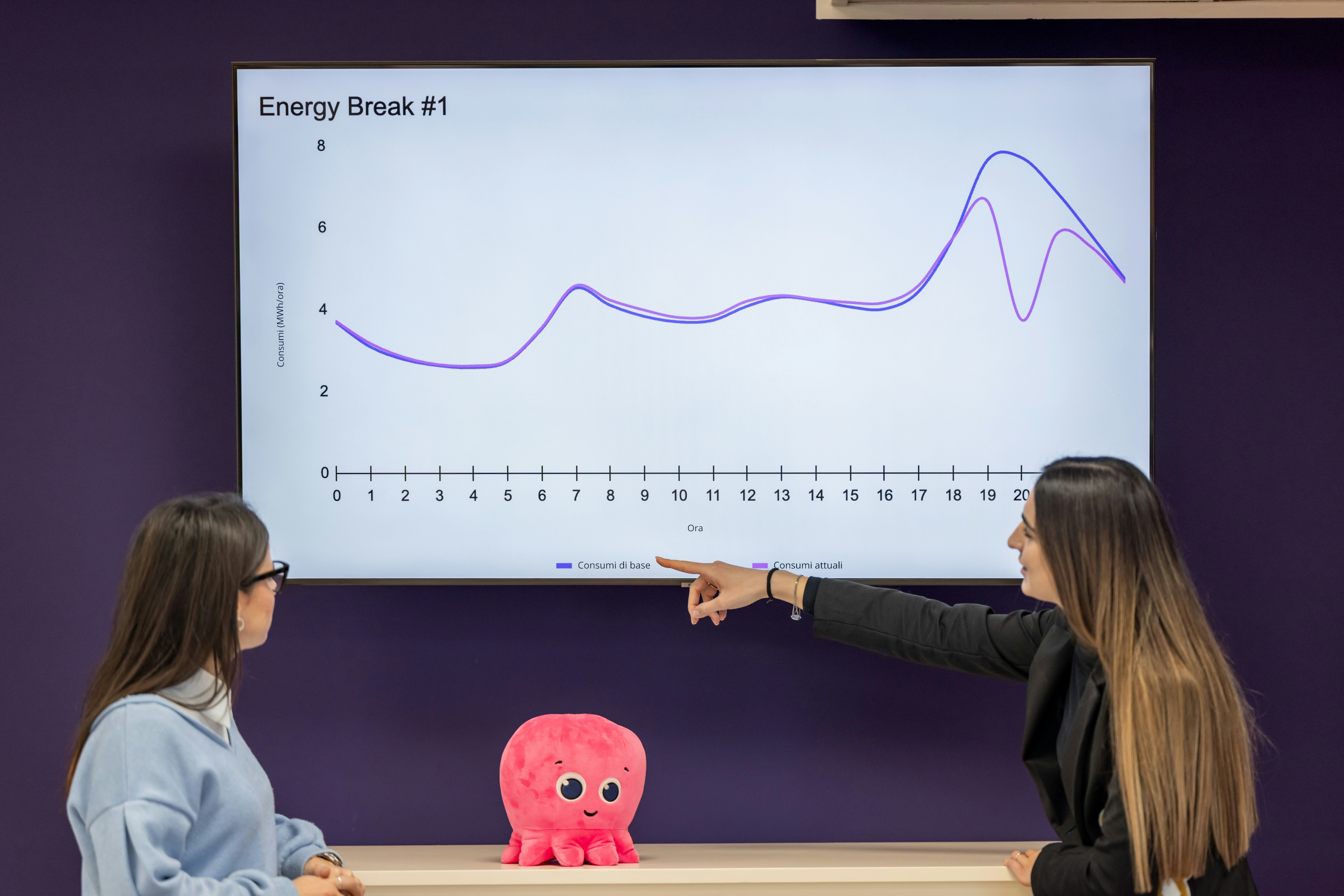
Descubre cómo GRPO entrena LLMs para predecir eventos reales, logrando que un modelo de 1.5B supere a Claude Sonnet 3.5. Resultados sorprendentes.

Aprende cómo ProGenMech descubre circuitos neuronales en modelos de proteínas para mejorar la generación y predicción de fitness.
Aprende cómo el Machine Learning explicable detecta el riesgo de disglucemia sin análisis de sangre. Modelo LightGBM supera a pruebas clínicas tradicionales.

Descubre cómo detener el muestreador de forma inteligente usando clasificadores neuronales para acelerar MCMC sin perder precisión. ¡Entra!

Descubre un marco de auditoría para comprobar si los modelos de IA realmente olvidan datos. Verifica el desaprendizaje sin reentrenar.

Predice parámetros de ejecución en química computacional con aprendizaje activo y generativo. Modelos alcanzan 99.9% de precisión.

Descubre cómo GERS mejora la generalización en RL usando solo métricas escalares, superando a métodos tradicionales en entornos no vistos.

Descubre cómo la normalización QK en MLA mejora estabilidad y eficiencia: menor pérdida, mayor precisión y menos de 2% de latencia extra en decodificación.

Aprendizaje por refuerzo offline con difusión para redes UAV justas y eficientes. Reduce energía, mejora equidad y aumenta throughput un 35%.

CacheMuon acelera el entrenamiento al reutilizar información previa para aproximar el factor polar, reduciendo costos sin perder precisión. Descubre cómo.

Descubre cómo mezclas de subespacios comprimen la comunicación un 95% para entrenar modelos de lenguaje con contextos de 100K tokens, incluso en redes lentas.

Descubre KaBiN: modelo de factorización Tucker con corrección de sesgo e inicialización Kaiming para completar tensores HDI. Mejora precisión sin sobrecarga.

MUNI: marco de difusión latente multimodal para generación any-to-any coherente. Supera modelos basados en LLM con enfoque unificado.

Descubre cómo Taylor-Calibrate inicializa modelos de atención híbrida con 88x mejora y reduce tokens de entrenamiento 9.2x. Optimiza tus Transformers.